- The paper demonstrates that system-level correlations yield significant results only for METEOR and semantic adequacy, unlike more consistent sentence-level findings.
- The paper employs rigorous experiments with nine NLG systems on the WebNLG dataset, using Spearman's correlation to compare human judgments and automatic scores.
- The paper suggests that refined or novel automatic metrics are needed to more accurately mirror human judgment, particularly at the sentence level.
Overview of the Paper
The research investigates the correlation between human evaluations and automatic metrics in natural language generation (NLG) through system- and sentence-level analyses. The study aims to highlight the inconsistencies in correlation results when comparing these two levels of analysis. Experiments reveal similar findings to those reported in machine translation (MT), suggesting a critical reflection on evaluation methodologies in the NLG field.
Context and Experimental Setup
The analysis is motivated by the existing discrepancy in correlation accuracies when comparing human and automatic metrics. In established MT practices, system-level correlation has shown more favorable results with automatic metrics like BLEU, METEOR, and TER than sentence-level comparisons. This study extends the analysis to NLG using the webnlg dataset, consisting of entries mapping triples from DBpedia to text.
Experiments were conducted using outputs from nine NLG systems from the WebNLG Challenge. Semantic adequacy, grammaticality, and fluency were rated by human judges on a three-point Likert scale. Automatic metrics were computed for each system and sentence, then compared to human-derived scores using Spearman's correlation. Statistical analyses were done using R, following best practices to minimize bias.
Findings on System-Level vs. Sentence-Level Correlations
The correlation analysis revealed contrasting results at the system-level and sentence-level:
- System-Level Correlation: Significant correlations were observed only between METEOR and semantic adequacy (p < .001), consistent with observations in MT. Other metric comparisons did not reach statistical significance.
- Sentence-Level Correlation: All correlations were found statistically significant (p < .001) with the highest between METEOR and semantic adequacy (ρ=0.73). Correlations between automatic metrics themselves were notably strong (ρ≥0.78). Despite statistical significance, correlations with human scores were moderate, aligning with MT findings which indicated that current automatic metrics might not adequately reflect human evaluations at the sentence level.
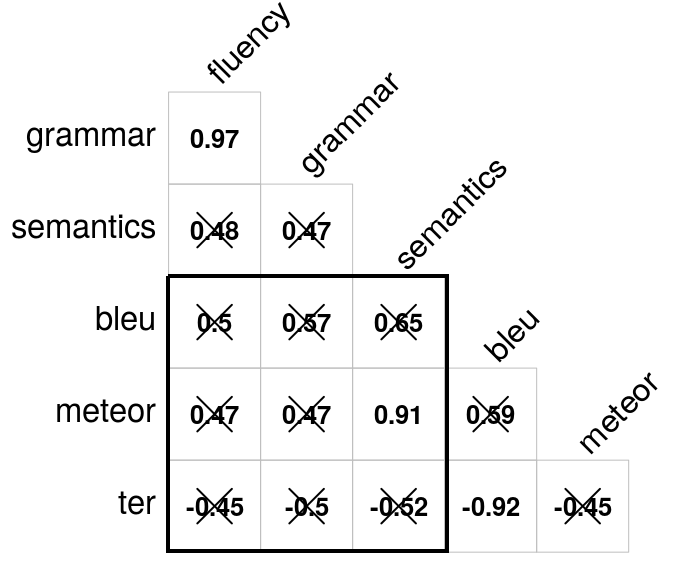
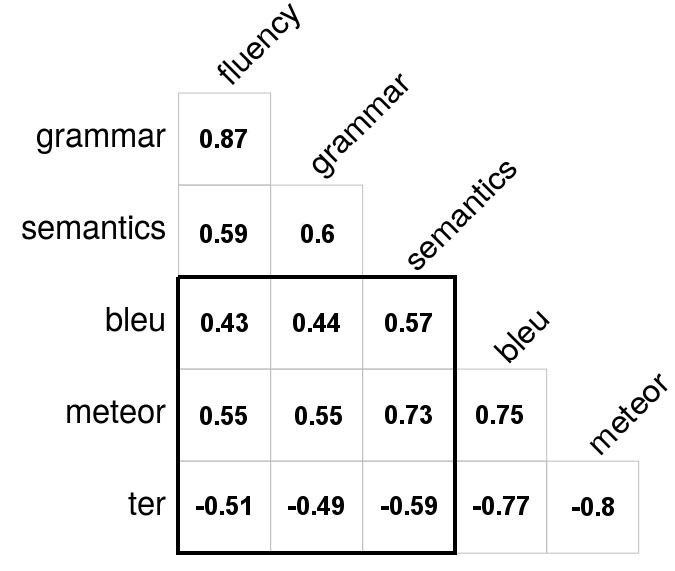
Figure 1: System- and sentence-level correlation analysis.
Practical Implications
The discrepancy in correlation strength between system-level and sentence-level measures suggests a need for revising evaluation strategies. Traditional NLG evaluations often mirror MT practices, focusing on system-level analysis. However, sentence-level correlation provides better fidelity for error analysis. The paper advocates for refined or new metrics that accurately reflect human judgment at the sentence level, thereby enhancing the fidelity of evaluations in NLG systems.
Conclusion
The study underlines a core issue in NLG evaluations—discrepant correlation results at different levels of analysis—echoing challenges noted in MT. The findings suggest an urgent need to develop refined automatic metrics with improved correlation with human scores at the sentence level. Future research should focus on exploring advanced metrics or hybrid evaluation approaches that bridge existing gaps and offer consistent insights across varied analytical dimensions. This will not only benefit NLG but also provide implications for broader applications in AI-driven communication technologies.