- The paper introduces MetricEval, a measurement theory-based framework that rigorously evaluates NLG metric reliability and validity using statistical tools.
- It quantifies key components such as metric stability, consistency, concurrent validity, and construct validity, providing detailed insights via a summarization case study.
- Results show that metrics like G-Eval with GPT-4 offer high reliability, while others like ROUGE-4 exhibit lower consistency, emphasizing the need for refined metric design.
Evaluating Evaluation Metrics: A Framework for Analyzing NLG Evaluation Metrics using Measurement Theory
The paper "Evaluating Evaluation Metrics: A Framework for Analyzing NLG Evaluation Metrics using Measurement Theory" (2305.14889) introduces MetricEval, a framework intended to scrutinize the reliability and validity of Natural Language Generation (NLG) evaluation metrics. This framework draws on principles from measurement theory, focusing on Metric Stability, Metric Consistency, Metric Construct Validity, and Metric Concurrent Validity. These components are rigorously quantified through statistical tools to provide more meaningful interpretations of evaluation results. Here's a detailed breakdown of the framework's components and application:
MetricEval Framework Components
Reliability
Reliability in the context of NLG metrics refers to their ability to provide consistent and dependable results across different implementations and evaluations. It addresses two main aspects:
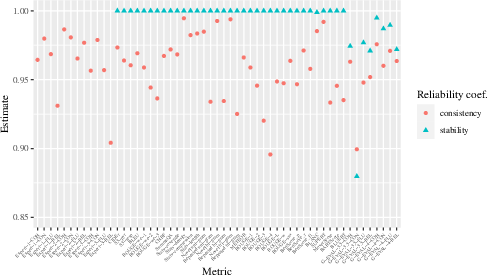
- Metric Stability: This measures the ability of a metric to yield consistent results when re-evaluating the same model outputs. Non-deterministic algorithms, such as those found in some LLM-based metrics (e.g., G-Eval 3.5 and G-Eval 4), may show fluctuations, thus affecting stability.
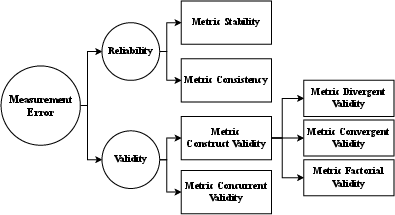
Figure 1: MetricEval: A framework that conceptualizes and operationalizes four main components of metric evaluation, in terms of reliability and validity.
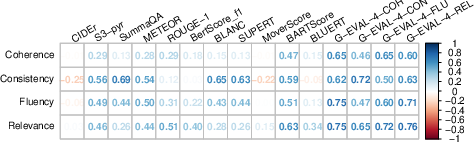
- Metric Consistency: This assesses how metric scores fluctuate with different datasets, aiming to measure intrinsic reliability across various data subsets. Statistical tools like the coefficient α provide a means to estimate this reliability coefficient.
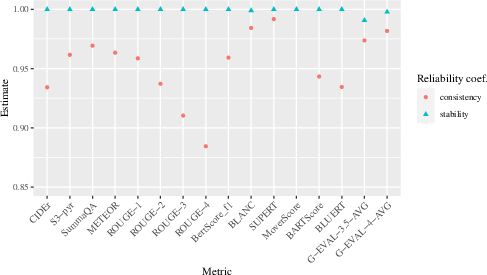
Figure 2: Estimated Metric Stability and Metric Consistency of popular NLG Metrics.
Validity
Validity examines whether metrics measure what they purport to measure and their applicability in making accurate inferences:
Case Study on Summarization Metrics
The paper illustrates the application of MetricEval through a case study on the SummEval dataset, consisting of summaries scored across 16 metrics. This study provided insights into both the stability and consistency of metrics.
Key Findings
Conclusion
MetricEval provides a comprehensive approach to evaluating NLG metrics' reliability and validity. By integrating measurement theory principles, it enables robust assessments of new and existing metrics' effectiveness, ultimately guiding improvements in NLG model evaluation practices. Future efforts could focus on expanding the framework to account for generalizability across diverse benchmarks and further refining evaluation criteria for distinct tasks.