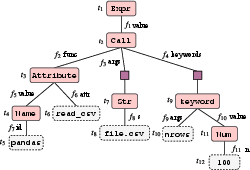
- The paper demonstrates TRANX’s effectiveness in transforming natural language into AST-based representations for semantic parsing and code generation tasks.
- It employs a transition system with discrete actions (ApplyConstr, Reduce, GenToken) that simplifies adaptation to various domain-specific grammars.
- Experimental results on datasets like GEO, ATIS, Django, and WikiSQL illustrate its high accuracy and potential for practical applications.
TRANX: Overview and Methodology
The paper "TRANX: A Transition-based Neural Abstract Syntax Parser for Semantic Parsing and Code Generation" (1810.02720) introduces a system named \model/, aimed at translating natural language (NL) utterances into formal meaning representations (MRs). \model/ uses a transition system based on abstract syntax description language (ASDL) to represent the MRs, enhancing its applicability across different domains due to its high accuracy and generalizability.
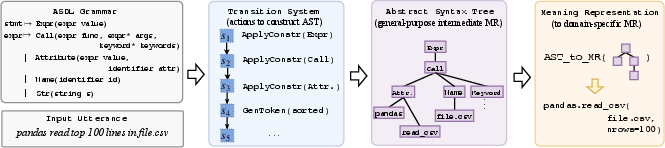
Figure 1: Workflow of \model/.
Generalization, Extensibility, and Effectiveness
The core strengths of \model/ are its generalization ability, extensibility, and effectiveness:
- Generalization Ability: \model/ utilizes Abstract Syntax Trees (ASTs) as an intermediate form of meaning representation, allowing it to parse across various domain-specific grammars.
- Extensibility: It employs a simple transition system, which makes it easy to extend and adapt for parsing tasks that involve domain-specific information with minimal engineering effort.
- Effectiveness: The system has demonstrated strong performance on several benchmarks, often surpassing existing neural network-based parsers across multiple datasets.
Methodology and Transition System
The methodology underpinning \model/ involves converting an NL utterance into a structured representation through a series of actions governed by a transition system.
Neural Architecture for Action Prediction
\model/ is implemented as a neural encoder-decoder system with augmentations to reflect ASTs' topology. Here are the technical specifics:
- Encoder: Utilizes a bidirectional LSTM network to encode the input sequence, producing a vectorial representation that aids in sequential decoding.
- Decoder: Also an LSTM, it iteratively generates tree-constructing actions by maintaining embeddings for each action type and leveraging attention mechanisms for context.
- Parent Feeding: This module incorporates information about each node's parent to enhance the prediction of syntactically complex constructs like those in programming languages.
\model/ has been evaluated comprehensively across different tasks:
Semantic Parsing
The system showed robust performance on datasets such as \geo/ and \atis/, proving its capacity to handle both simple and complex logical forms. It consistently outperformed existing models by incorporating parent feeding enhancements.
Code Generation
For code generation tasks, \model/ showcased its adaptability and precision. On the \django/ dataset, it achieved state-of-the-art results, while its application to the \wikisql/ dataset demonstrated its extensibility with the introduction of minimal task-specific modifications.
Conclusion
\model/ establishes itself as a versatile framework for mapping natural language to formal representations, underscoring its significance in semantic parsing and code generation contexts. Its modular architecture allows for adaptation across tasks requiring domain-specific parameters, highlighting future prospects in AI as systems become increasingly specialized and domain-adaptable.