- The paper introduces MS-ASL, the first large-scale real-world ASL dataset with over 25K videos and 1000 sign classes, addressing challenges in signer independence and variability.
- The paper benchmarks multiple state-of-the-art recognition architectures, finding that 3D CNNs (I3D) achieve top-1 accuracies up to 81.9% compared to other models.
- The results underscore the impact of data scale and pretraining on model performance, highlighting the need for enhanced keypoint extraction for fine-grained sign distinctions.
MS-ASL: Establishing a Large-Scale Benchmark for American Sign Language Recognition
Introduction and Motivation
The "MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language" paper addresses the long-standing deficit of large, diverse, and realistically acquired datasets for American Sign Language (ASL) recognition. The work is motivated by the requirements posed by modern deep learning architectures, which demand extensive annotated datasets to facilitate generalization, especially in tasks involving high degrees of inter- and intra-class variability such as sign language recognition. The lack of such resources for ASL had precluded meaningful progress on signer-independent recognition and hindered the application of state-of-the-art computer vision models in this field.
MS-ASL Dataset Design and Characteristics
The paper introduces MS-ASL, the first large-scale, real-world ASL dataset, comprising over 25,000 manually annotated video samples representing 1000 sign classes demonstrated by 222 unique signers. The dataset is constructed through automated mining and expert curation of online ASL teaching and student videos. This methodology introduces substantial variability in background, lighting, camera viewpoint, signer clothing, and performance style. This variability is further amplified by the intrinsic linguistic and dialectal diversity of ASL, including synonymy and polysemy at the gloss level.
The dataset addresses key deficiencies of prior resources by ensuring:
- Substantial class count (up to 1000 different signs), enabling scaling experiments.
- Large signer count and strict signer-independence splits (distinct sets for training, validation, and testing), directly targeting the generalization gap.
- Unconstrained, real-world recording settings.
- Accurate manual annotation and trimming, especially of long or low-frame videos, to minimize irrelevant context and label noise.
The resulting distribution of video durations, with a mean of ~60 frames and a Poisson-like profile, reflects the complexity and variability of real-world sign production.
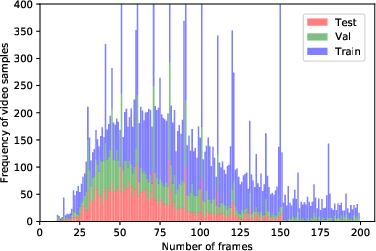
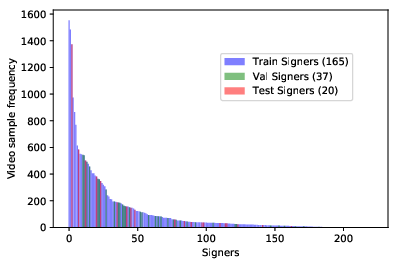
Figure 1: Histogram of frame numbers for ASL1000 video samples, indicating the distribution and duration variability of real-world signing instances.
Four subsets are provided for benchmarking: ASL100, ASL200, ASL500, and ASL1000, containing the 100, 200, 500, and 1000 most frequent signs, respectively. Each split is strictly signer-independent, enabling robust experimental design for generalization-centric studies.
Baseline Architectures and Experimental Protocol
The paper benchmarks four representative recognition paradigms:
- 2D CNN + LSTM: Framewise feature extraction (e.g., VGG16 or GoogleNet) followed by temporal modeling with LSTMs (256-512 hidden units), reflecting the action recognition pipeline of the previous decade.
- Body Key-Point Networks (HCN): Skeleton-based models using 137 keypoints per frame (including hands and face) extracted with state-of-the-art pose estimators [cao2017realtime, simon2017hand]. Input shape is [64×137×3] (per video window) capturing spatial, temporal, and confidence components.
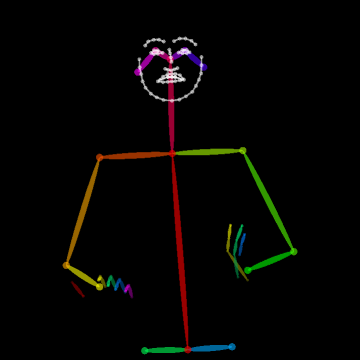
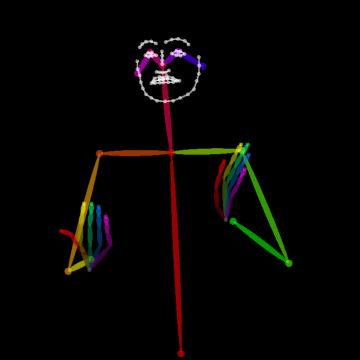
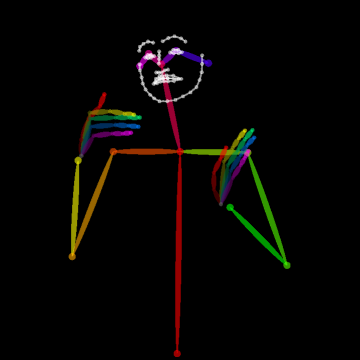
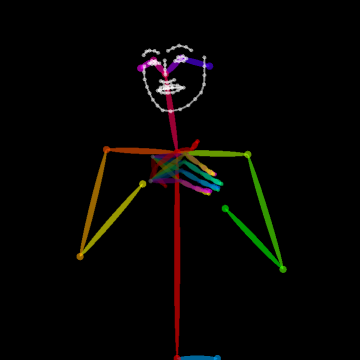
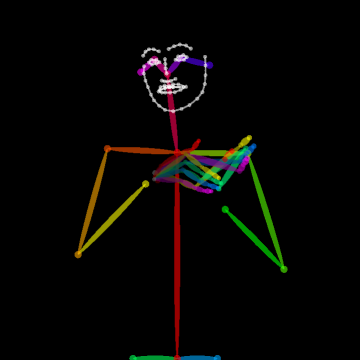
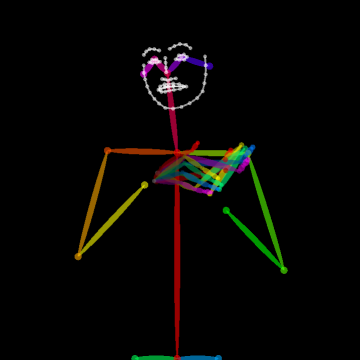
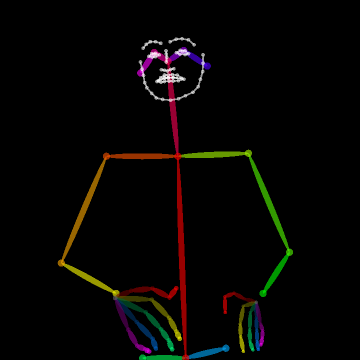
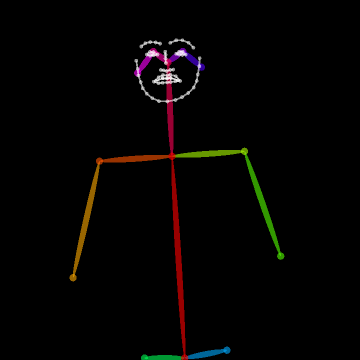
Figure 2: Example of the extracted 137 body key-points for a video sample from MS-ASL, capturing hand, facial, and body articulation critical to sign disambiguation.
- CNN-LSTM-HMM hybrid ("Re-Sign"): End-to-end deep sequence models combining CNNs, bidirectional LSTMs, and HMMs to align visual features with gloss sequences.
- 3D CNNs (I3D): Inflated 3D convolutional networks (I3D), initialized from large-scale action datasets (ImageNet + Kinetics), directly operating on 64×224×224 RGB input cubes to jointly capture spatial and motion cues.
Key aspects:
- Input normalization: Detected bounding box extraction (via SSD), bounding box jittering, resizing, and horizontal flipping (exploiting ASL’s handedness invariance).
- Temporal sampling: Fixed-length (64 frames) random clips, with undersized videos padded by frame repetition.
- No use of optical flow for any baseline to isolate the effect of RGB cues and architectural choices.
Empirical Results and Analysis
Quantitative Results
I3D achieves the highest performance, with top-1 per-class accuracy of 81.8%, 81.9%, 72.5%, and 57.7% for ASL100, ASL200, ASL500, and ASL1000 respectively, and top-5 per-class accuracy reaching 95.2% on ASL100 and 81.1% on ASL1000. These values are substantially higher than those of 2D CNN + LSTM, keypoint-only, or hybrid HMM architectures.
Impact of Dataset Scale
Expanding the number of classes from 100 to 1000 yields a moderate degradation in accuracy, whereas the drop is less severe when more training samples per class are available. In cross-subset transfer, I3D models pretrained on larger subsets transfer effectively to smaller subsets, outperforming ImageNet+Kinetics pretraining by >3.5%.
Data Efficiency and Frequency
Model performance exhibits a clear dependency on the per-class sample count. For classes with >40 training samples, accuracy plateaus at ~80% or above; for lower frequencies, recognition degrades rapidly—highlighting sample efficiency limits even of powerful video models.
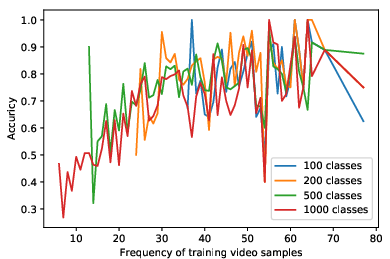
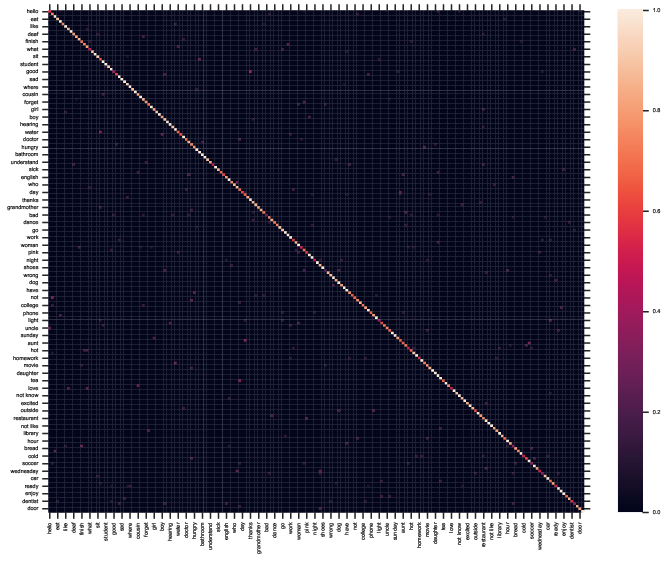
Figure 3: The accuracy of trained models as a function of the frequency of training samples per class, demonstrating that performance is strongly sample-limited for rare classes.
Qualitative and Error Analysis
Analysis of confusion matrices reveals that most misclassifications arise from intrinsic ASL ambiguities (e.g., signs for "good" and "thanks” often are visually minimal pairs), dialectal variation, or context-dependent polysemes. Residual errors in large-sample classes are often due to linguistic ambiguity rather than model capacity, underscoring the need for multimodal integration with LLMs or context disambiguation.
Keypoint-based representations
While keypoint-based recognition (HCN) surpasses classical 2D CNN-LSTM in accuracy, its performance is ultimately capped by the robustness of hand and finger keypoint estimation—currently limiting fine-grained sign discrimination in unconstrained settings.
Implications and Future Directions
The publication of MS-ASL marks a pivotal improvement in the empirical rigor and real-world relevance of sign recognition research. It fills a critical gap for benchmarking deep models under high signer, environmental, and linguistic variability and enables reproducible comparison for a range of approaches. Key takeaways:
- 3D CNNs with large video datasets and discriminative pretraining are state-of-the-art for signer-independent, large-vocabulary sign classification from RGB.
- Pretraining on in-domain video (sign) data decisively outperforms generic action recognition initialization.
- Keypoint-based methods require advances in pose extraction, especially for fine hand gestures, to close the gap with spatiotemporal convolutional approaches.
Practically, MS-ASL facilitates new research on transfer learning, data augmentation, adaptation to unseen signers or dialects, multi-modal fusion, and context-based re-scoring for sign language understanding pipelines. The dataset design strategy, including the use of openly available video sources and scalable annotation refinement, is also widely generalizable to other low-resource gestural languages and modalities.
Conclusion
The MS-ASL dataset and benchmark represent a substantial advance in the field of sign language recognition, providing an empirically challenging task with rigorous signer-independence, significant environmental and linguistic variability, and the scale necessary for modern deep architecture development. The accompanying baseline experiments clearly substantiate the superiority of I3D-based video models for signer-independent large vocabulary ASL recognition and provide a reference point for future work. The dataset's public availability will foster accelerated progress on robust, scalable, and inclusive sign language understanding systems.