- The paper introduces a Stereo R-CNN framework that simultaneously detects and associates objects using stereo images, enhancing 3D localization.
- It extends Faster R-CNN with a stereo region proposal network and dense photometric alignment, achieving approximately 30% higher detection precision on KITTI.
- The methodology eliminates the dependency on LiDAR by leveraging both semantic and geometric cues for robust autonomous driving applications.
Stereo R-CNN based 3D Object Detection for Autonomous Driving
Introduction to Stereo R-CNN
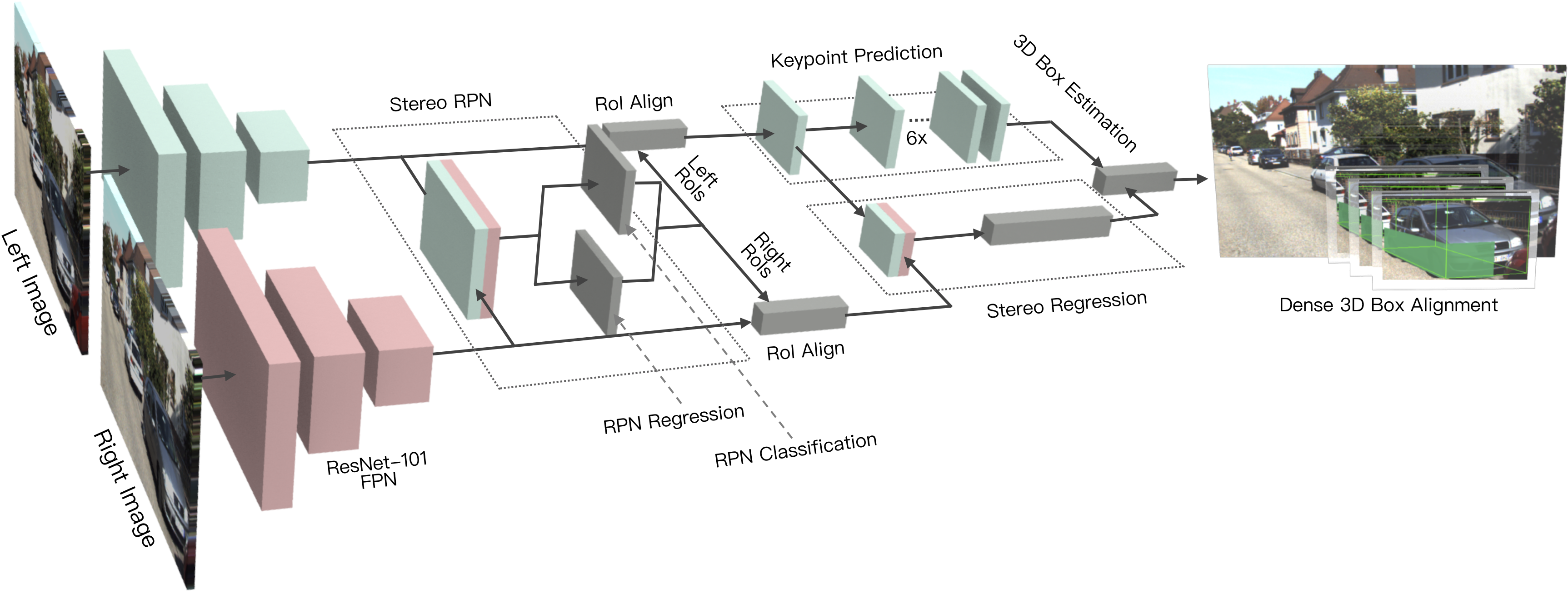
The paper introduces an innovative Stereo R-CNN approach aimed at enhancing 3D object detection for autonomous driving. By leveraging stereo imagery, the method offers an alternative to LiDAR, which is commonly used but has limitations such as high cost and sparse information. Stereo R-CNN is designed to exploit both semantic and geometric information from stereo images, enabling it to effectively detect and associate objects in left and right images concurrently.
Network Architecture
The proposed Stereo R-CNN network architecture is shown to extend the existing Faster R-CNN framework to handle stereo inputs. The network consists of three main components:
Key Contributions
The Stereo R-CNN introduces several key innovations:
- Simultaneous Detection and Association: The framework detects and associates objects in stereo images simultaneously, leveraging a unique classification and regression target assignment.
- 3D Box Estimator: Utilizes both keypoints and stereo box constraints to enhance 3D bounding box prediction.
- Photometric Alignment for 3D Localization: A dense alignment strategy ensures accurate object localization, outperforming traditional methods that require depth information.
- Evaluation and Results: Tested on the KITTI dataset, the method surpasses state-of-the-art stereo-based techniques, providing approximately 30% higher average precision in both 3D detection and localization tasks.
The proposed method was evaluated on the KITTI benchmark, demonstrating significant improvements over existing image-based and stereo-based 3D detection approaches. The method achieved superior performance in both average precision for bird’s-eye view and 3D bounding box metrics across easy, moderate, and hard difficulty levels.
Practical Implications and Future Work
While Stereo R-CNN outperforms several existing methods, its practical applications extend beyond current achievements. Future developments could involve extending the model for multi-object tracking and integrating instance segmentation for more precise RoI selections.
Concluding, the research presents Stereo R-CNN as a viable, cost-effective alternative in autonomous driving applications, offering robust performance without the dependency on depth inputs. This framework not only enhances current 3D object detection capabilities but also lays the groundwork for future enhancements and applications in diverse environments.