- The paper introduces a dual-branch DETR that combines monocular and stereo branches to enhance 3D object detection accuracy and speed.
- It details a novel depth sampling strategy that manages occlusions without relying on extra annotations, ensuring precise depth estimation.
- Experimental results on the KITTI benchmark show significant improvements by reducing inference time to 17.6 ms while excelling in pedestrian and cyclist detection.
Introduction
StereoDETR presents an innovative approach to stereo-based 3D object detection, designed to offer significant improvements in computational efficiency and inference speed, while maintaining high accuracy. This framework leverages the Disentangled Transformer (DETR) architecture tailored for integrating binocular vision, thereby achieving superior performance compared to both existing monocular and stereo methods in various aspects of 3D detection tasks.
Methodology
Architecture Overview
StereoDETR operates through dual branches: a monocular DETR branch and a stereo branch. This design integrates cross-view disparity features with DETR's object-centric coarse depth estimations, facilitating precise 3D localization.
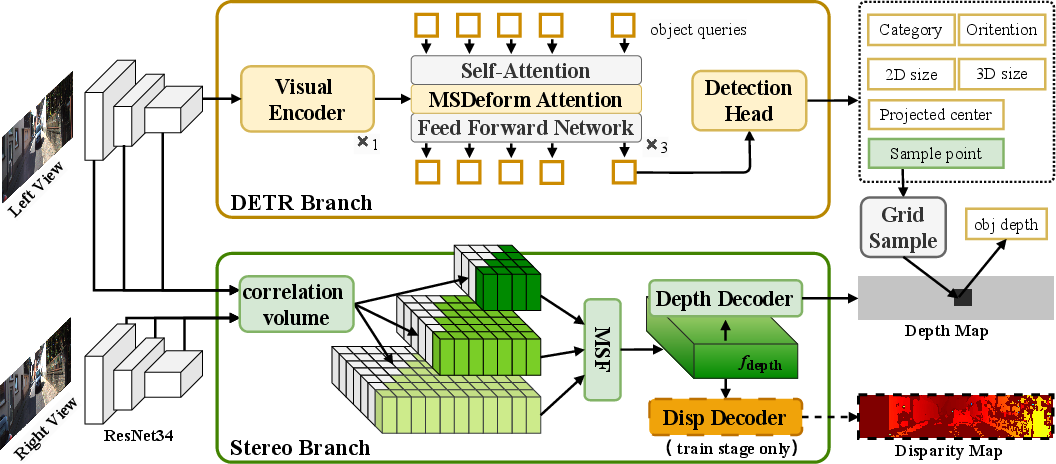
Figure 1: Overview of StereoDETR architecture.
DETR Branch
The monocular DETR branch extends traditional 2D detection frameworks by including elements for predicting object scale, orientation, and depth sampling points. Adopting a simplified version of MonoDETR and MonoDGP architectures, this branch decouples depth prediction, eliminating additional encoders typically required for depth feature fusion.
Stereo Branch
StereoDETR's stereo branch computes correlation volumes and performs multi-scale fusion using lightweight disparity features. This approach transforms stereo image pairs into efficient depth maps, overcoming the latency challenges commonly associated with stereo vision methods.
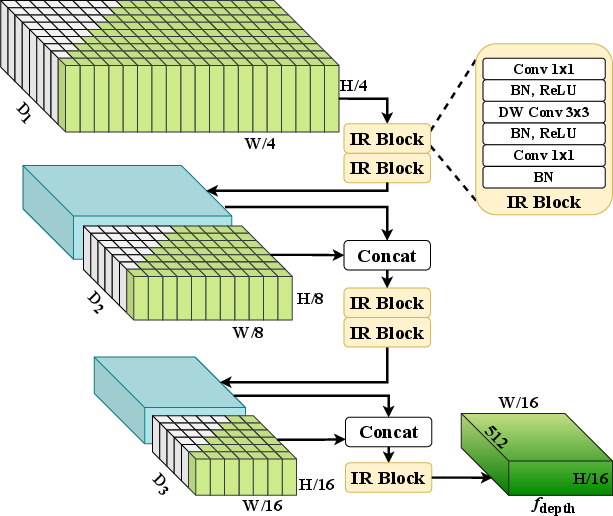
Figure 2: Multi-Scale Fusion module: transforms multi-scale correlation volumes into depth features.
Depth Sampling Strategy
A novel depth sampling strategy addresses occlusions by supervising sampling points based on object visibility, leveraging constrained supervision to bypass additional annotations. This offset sampling method is key to achieving accurate depth estimation in occlusion-prone environments.
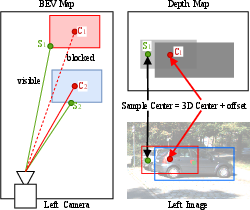
Figure 3: Depth sampling strategy designed to address occlusions challenge.
Experimental Results
StereoDETR sets new performance benchmarks on the KITTI dataset, showcasing leading accuracy for pedestrian and cyclist subsets, with significant improvements over both monocular methods and previous stereo approaches. This is achieved while notably reducing inference time to 17.6 ms per image, breaking the longstanding trade-off between speed and accuracy in 3D detection frameworks.
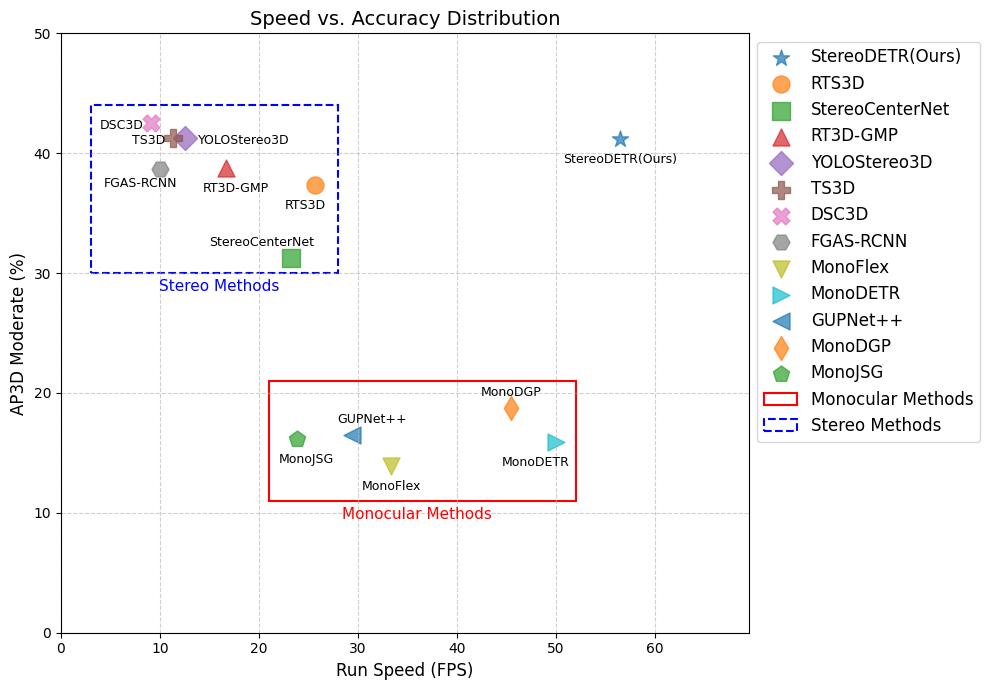
Figure 4: Comparison of accuracy and speed with existing camera-based methods on the KITTI test set (Car category, moderate difficulty).
Visualizations
StereoDETR's capability is further illustrated through visualization results of predicted 3D bounding boxes and depth maps, highlighting its robust performance in real-world scenarios.

Figure 5: Visualization results of predicted depth maps, 3D object centers, and non-occluded sampling points.

Figure 6: Visualization results of the predicted 3D bounding boxes and their corresponding representations in the Bird's-Eye View.
Conclusion
StereoDETR represents a groundbreaking stride in the stereo 3D detection domain, achieving real-time performance with unrivaled accuracy. By refining architectural simplicity and optimizing depth sampling, it paves the way for future advancements in 3D vision applications, including autonomous driving and beyond. This framework's potential to adapt to open-world detection scenarios signifies a substantial contribution to the evolution of intelligent machine perception systems.