- The paper introduces a novel ESN model that employs a self-normalizing activation function projecting neuron states onto a hyper-sphere, reducing chaotic dynamics.
- The model maintains universal approximation properties and robust memory capacity, excelling in nonlinear systems like Lorenz and Mackey–Glass time-series prediction.
- By operating stably at the edge of criticality, the approach minimizes hyper-parameter tuning, paving the way for efficient and adaptable recurrent network designs.
Echo State Networks with Self-Normalizing Activations on the Hyper-Sphere
Introduction
Echo State Networks (ESNs) have gained attention due to their training simplicity and efficiency. Traditional ESNs, however, are highly sensitive to hyper-parameter settings, often requiring them to operate near the edge of criticality (EoC) to avoid chaotic behaviors and maximize performance. This paper introduces a novel ESN model employing self-normalizing activation functions, which maintains stability across a wide range of hyper-parameter values, thereby eliminating the risk of chaotic states while preserving the network's ability to approximate nonlinear systems.
Proposed Model and Activation Function
The proposed ESN model is characterized by a self-normalizing activation function that projects each neuron’s activation onto a hyper-sphere, ensuring the system's stability and avoiding chaotic behavior. This approach maintains rich dynamics and a memory capacity comparable to linear networks.
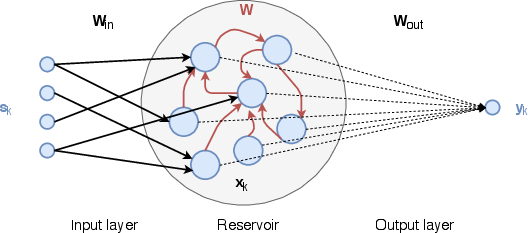
Figure 1: Schematic representation of an Echo State Network (ESN) with a hyper-spherical activation structure.
The key elements of this model include modifying the activation function to globally affect neuron states simultaneously, calculated as:
xk=r∥ak∥ak
This transformation ensures that the activations are normalized over the hyper-sphere of radius r, providing robustness irrespective of the input type or hyper-parameter settings.
Stability Analysis and Universal Approximation
The paper demonstrates that the proposed ESN model is a universal function approximator, retaining the Echo State Property (ESP) under broad conditions. The derived Jacobian matrix for the activation reveals that the system cannot exhibit positive Lyapunov exponents, which precludes chaotic dynamics:
Jij=∥a∥2Wij∥a∥(1−∥a∥2aiaj)
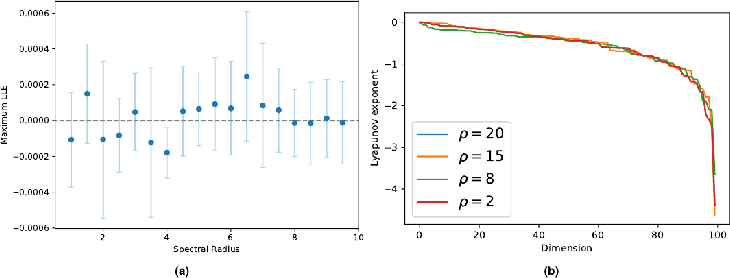
Figure 2: Panel (a) shows local Lyapunov exponents (LLE) for various spectral radius values, emphasizing the non-chaotic behavior.
This characteristic allows the network to always operate at the EoC, hence maximizing performance over typical configurations.
Memory Capacity and Nonlinearity
The network's memory capacity was rigorously tested against several benchmarks, showcasing superior performance in memory-intensive tasks while effectively managing nonlinearity:
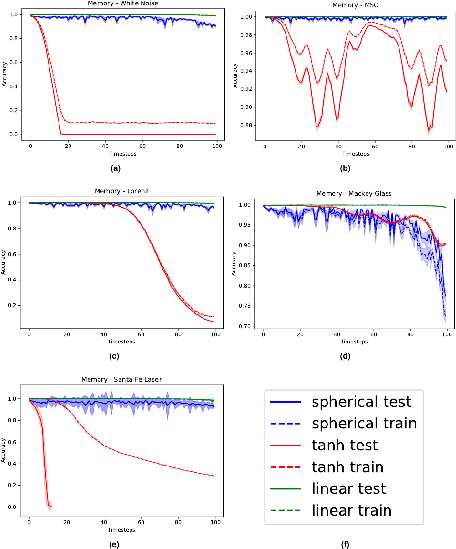
Figure 3: Results of memory tasks on different benchmarks illustrating the model's proficiency in retaining past inputs.
The spherical activation function helps achieve a balance between memory retention and nonlinear operations, outperforming both linear and hyperbolic tangent-based networks in tasks demanding both attributes.
Experimental Results
The proposed model's experimental validation involved various time-series prediction tasks, such as the Lorenz and Mackey-Glass systems. Comparisons with traditional ESNs and those employing linear activation functions revealed that spherical ESNs consistently deliver robust performance across a spectrum of scenarios.
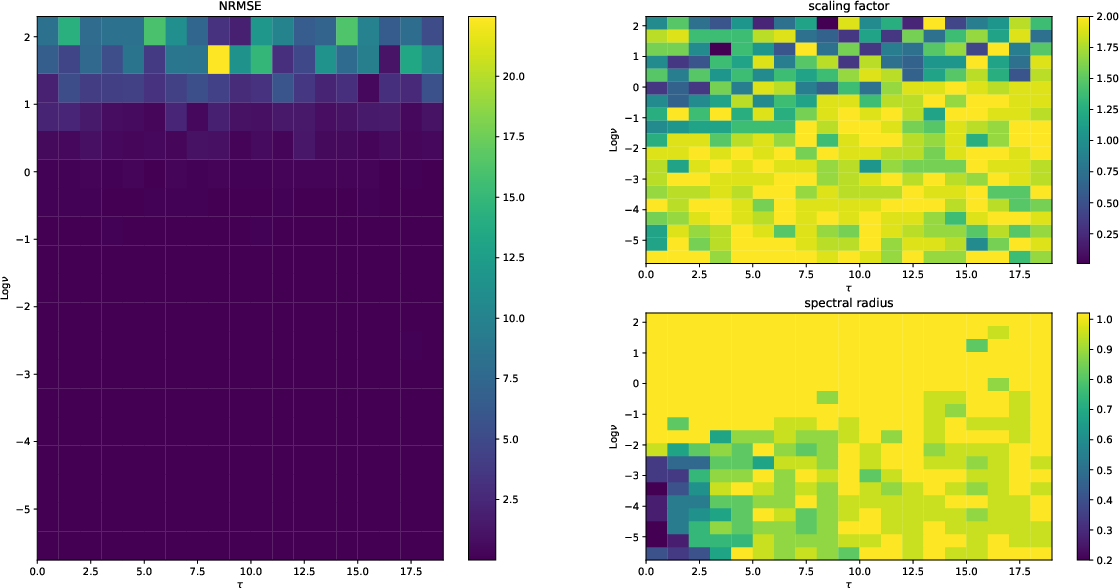
Figure 4: Performance of linear networks indicating high errors with increased nonlinearity.
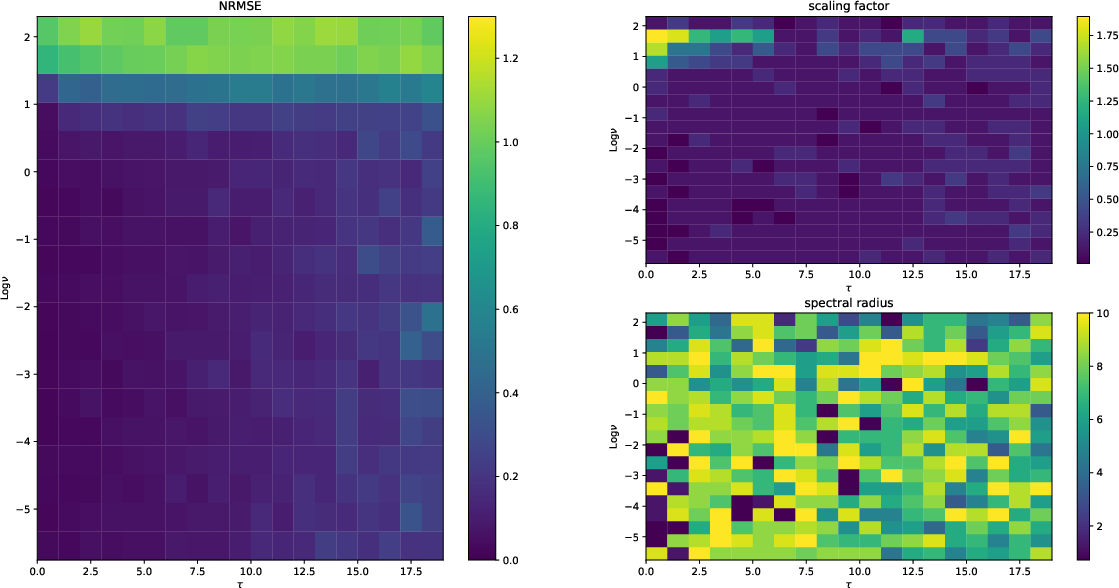
Figure 5: Performance of the proposed model demonstrating robustness across memory and nonlinearity dimensions.
Conclusion
The self-normalizing activation function over the hyper-sphere introduces a paradigm shift in ESN design by offering a stable yet dynamic framework for recurrent networks. This approach significantly alleviates hyper-parameter sensitivity, sustaining EoC-based optimization without risking chaotic interference and ensuring broad applicability across nonlinear computational tasks.
Ultimately, this work provides critical insights for future developments in ESN architectures, paving the way for more efficient and stable recurrent network designs that can be easily adapted to diverse machine learning contexts without extensive hyper-parameter tuning.