- The paper demonstrates that GANs can synthesize data to train student networks when the original dataset is unavailable.
- It introduces innovative loss functions—one-hot, activation, and entropy losses—to ensure fidelity and balanced class representation.
- The approach achieves competitive accuracies on MNIST, CIFAR-10/100, and CelebA, indicating its potential for privacy-sensitive deployments.
Data-Free Learning of Student Networks
This essay examines the "Data-Free Learning of Student Networks," which presents a novel approach to deep neural network compression, targeting scenarios where direct access to the training dataset is unavailable. The primary focus of this work is the development of student networks utilizing generative adversarial networks (GANs) to generate training samples in the absence of the original data.
Introduction and Motivation
Deep neural networks (DNNs), specifically convolutional neural networks (CNNs), have become integral in various computer vision tasks, but their deployment on resource-constrained edge devices remains challenging due to substantial computational and memory requirements. The current methods in model compression and acceleration either presume availability of training datasets or demand complete knowledge of network architectures, both of which are frequently impracticable due to privacy concerns and limited transmission capabilities.
Core Methodology
The proposed method leverages a GAN framework where the pretrained, high-capacity teacher network functions as a fixed discriminator. The generator is iteratively trained to create images that maximize the teacher network's response, simulating a distribution that closely mirrors the unseen original dataset.
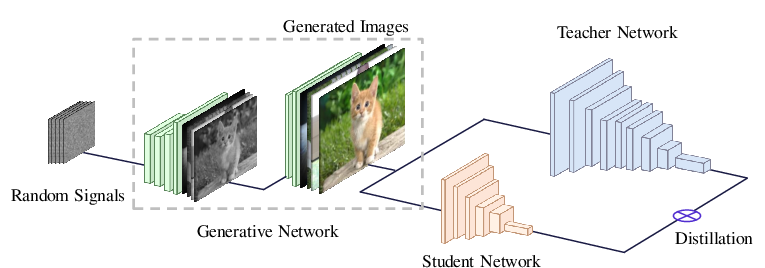
Figure 1: The diagram of the proposed method for learning efficient deep neural networks without the training dataset. The generator is trained for approximating images in the original training set by extracting useful information from the given network. Then, the portable student network can be effective learned by using generated images and the teacher network.
Generative Adversarial Networks for Data Generation
The GAN setup inverts its typical application by treating the teacher network as the discriminator, which remains unaltered during training. The generator produces synthetic images that the network perceives as legitimate representatives of its original training set. Key loss components introduced include:
- One-hot Loss: Aligns outputs of synthetic samples to emulate the one-hot encoded nature of true class labels.
- Activation Loss: Drives activations in intermediate network layers to enhance representation fidelity.
- Entropy Loss: Balances the distribution of generated images across classes, ensuring uniform class representation.
Experimental Evaluation
The efficacy of the proposed data-free learning approach is evaluated across datasets including MNIST, CIFAR-10, CIFAR-100, and CelebA. The student networks trained through data-free methodologies closely approach accuracies of those retrained with original data, owing to the effective synthesis and utility of GAN-generated samples.
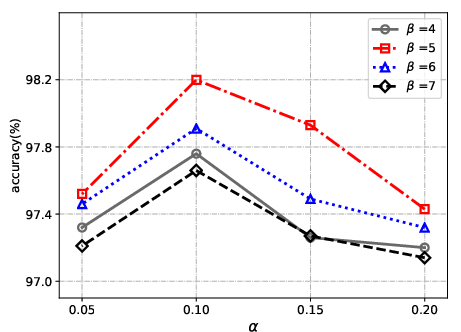
Figure 2: The performance of the proposed method with different parameters alpha and beta on the validation set of MNIST.
Key Results and Analysis
- MNIST: Achieved student network accuracy of 98.20% using LeNet-5 architecture in comparison to the teacher model's 98.91%, demonstrating substantial retention of classification capability.
- CIFAR Datasets: The proposed method resulted in resilient student accuracies of 92.22% for CIFAR-10 and 74.47% for CIFAR-100, with the teacher models' accuracies recorded at 95.58% and 77.84%, respectively. These indicate strong generalization even with absent original datasets.
- CelebA: Without original data, the student network reached 80.03% accuracy, leveraging GAN-created data, nearing the teacher's performance of 81.59%.




Figure 3: Visualization of averaged image in each category (from 0 to 9) on the MNIST dataset.
Conclusion
The study introduces a cutting-edge approach for training competitive student networks without available training data. By crafting a GAN-driven surrogate data generation pipeline, it bypasses traditional data reliance, presenting a significant step toward practical deployment of efficient networks in privacy-restricted environments. Future advancements may investigate optimized generator architectures or enhanced objective functions for even more accurate data approximation, potentially broadening applicability to varied neural network architectures and more complex datasets.