- The paper introduces a framework that uses synthetic data from adversarial networks to enable data-free quantization.
- It leverages batch normalization statistics and categorical entropy constraints to ensure synthetic data represents original distributions.
- The method achieves state-of-the-art results on datasets like SVHN, CIFAR-10, and CIFAR-100 with minimal accuracy degradation.
Data-Free Network Quantization With Adversarial Knowledge Distillation
The paper "Data-Free Network Quantization With Adversarial Knowledge Distillation" presents a novel framework for quantizing neural networks without access to the original training data. The proposed method leverages synthetic data generated by adversarial networks and performs knowledge distillation (KD) to facilitate efficient model compression while preserving accuracy.
Problem Context
Quantization is pivotal in deploying deep neural networks on resource-constrained mobile and edge devices. Traditional approaches often require access to original datasets, which becomes untenable with emerging data privacy regulations and massive datasets. The paper introduces a data-free solution using adversarial knowledge distillation (AKD) that eliminates dependency on original datasets by utilizing synthetic data.
Adversarial Knowledge Distillation Framework
The authors propose a generator-based adversarial framework to produce synthetic examples for KD. A generator, trained to produce adversarial examples, drives the AKD process by maximizing the divergence between outputs of a teacher network and a student network trained on the synthetic data. Additionally, the generator is constrained using the statistics from batch normalization layers of the teacher network to ensure that synthetic data remains representative of the original dataset distribution.
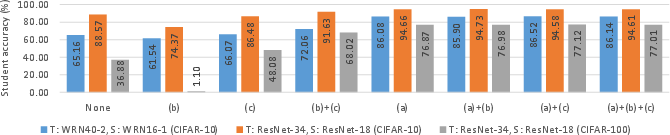
Figure 1: Ablation study on the three terms in the auxiliary loss~L_\psi.
Auxiliary Loss Terms
Three additional loss terms constrain the generator:
- Batch Normalization Statistics: The generator aims to match statistics from the teacher's batch normalization layers using KL-divergence between Gaussian distributions, promoting similarity to original training data.
- Instance Categorical Entropy: Minimizing entropy of synthetic samples' predictions ensures sharp class predictions, emphasizing true sample associations.
- Batch Categorical Entropy: Maximal entropy of averaged predictions over batches enforces diversity across generated samples.
Implementation Details
The proposed data-free AKD framework is implemented with multiple generators and students to enhance diversity and robustness. The strategy involves a pre-training phase for generators focused on aligning batch normalization statistics, followed by adversarial training combined with KD.
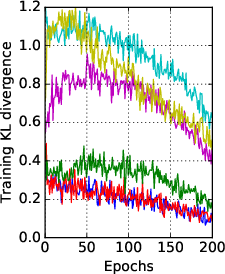
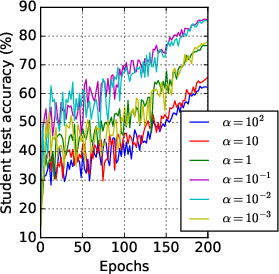
Figure 2: Training KL divergence and student test accuracy of data-free KD for different values of α.
The framework demonstrates state-of-the-art results in both data-free KD and quantization. Experiments were performed on several datasets, including SVHN, CIFAR-10, CIFAR-100, and Tiny-ImageNet. The results indicated minimal accuracy degradation compared to models trained with original data.
The methodology also extends to data-free quantization-aware training, achieving comparable accuracy to conventional data-dependent methods, underscoring the efficacy of synthetic data substitution for quantization.
Implications and Future Work
The proposed framework addresses critical privacy concerns, allowing model compression without data exposure. The AKD approach opens avenues for data-free model optimization, crucial for deploying models across devices with varying resource capabilities. Future research can explore broader applications, scalability to larger networks, and further optimization of generator constraints.
Conclusion
This research presents a compelling solution to quantize and compress neural networks in data-restricted environments. By innovatively integrating adversarial learning and KD, the study circumvents traditional data dependence, achieving sufficiency in representative synthetic data generation. This work forms a foundation for advancing secure and privacy-preserving AI deployment techniques.