- The paper introduces a novel gated fully fusion method that selectively integrates multi-level features to improve detection of small and thin objects.
- It incorporates a Dense Feature Pyramid module that leverages contextual information to refine large object segmentation and boundary delineation.
- The method achieves state-of-the-art results, recording 82.3% mIoU on the Cityscapes test set while outperforming standard fusion strategies.
Overview of Gated Fully Fusion for Semantic Segmentation
The paper "Gated Fully Fusion for Semantic Segmentation" (1904.01803) introduces a novel method for improving semantic segmentation, particularly focusing on the challenges related to small and thin object detection and boundary delineation. The proposed approach, termed Gated Fully Fusion (GFF), aims to selectively fuse multi-level features in a convolutional neural network using a gating mechanism, enhancing the ability to capture both high-level semantics and fine-grained details, thus achieving state-of-the-art performance across various datasets.
Introduction
Semantic segmentation involves assigning categorical labels to each pixel in an image, a task crucial for applications like autonomous driving and medical imaging. The challenge lies in accurately segmenting diverse objects with varying scales and in different contexts (Figure 1). High-level features obtained from deep convolutional neural networks, while effective at capturing overall semantics, often lack the resolution needed for small or thin objects and boundaries. A straightforward fusion of multi-level features can introduce a semantic gap, drowning useful signals in noise.
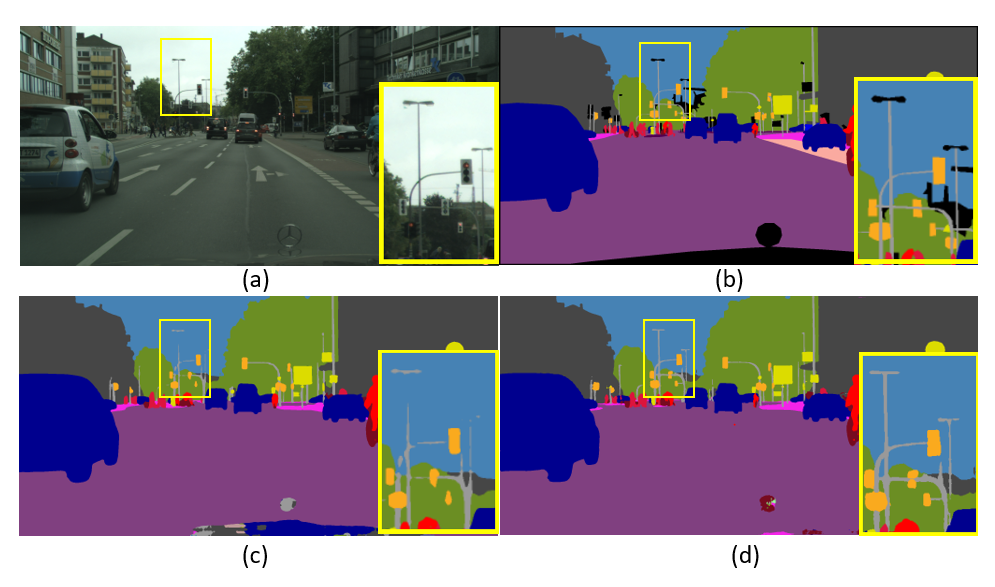
Figure 1: Illustration of challenges in semantic segmentation. Our method performs better on small patterns like distant poles.
Methodology
Gated Fully Fusion (GFF)
The GFF architecture introduces gates to control the fusion of features across different levels. Each level of the feature maps is regulated by gate maps that determine whether information should be sent out or aggregated based on its usefulness. This fully connected gating mechanism mitigates the semantic gap and selectively propagates relevant information throughout the network (Figure 2).
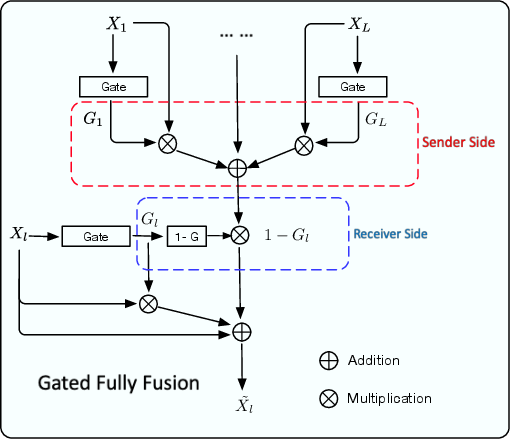
Figure 2: The proposed gated fully fusion module. Gates control feature propagation, allowing selective sending and receiving based on feature usefulness.
Dense Feature Pyramid (DFP)
In addition to GFF, the paper proposes a Dense Feature Pyramid to further incorporate contextual information, which is crucial for segmenting large-scale patterns. The DFP module utilizes dense connections that enhance feature propagation and reuse contextual information from one layer to another. This module is designed to work in conjunction with GFF, leveraging PSPNet and enhancing its context modeling capabilities (Figure 3).
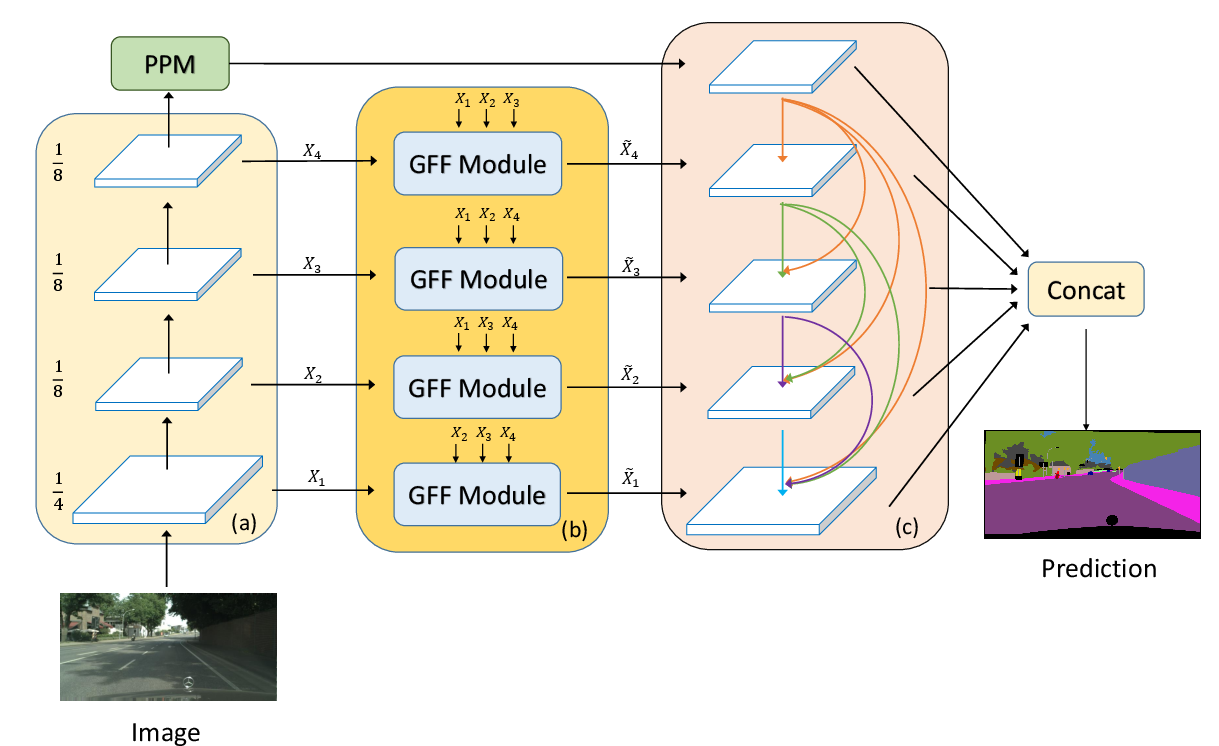
Figure 3: Illustration of the overall architecture integrating GFF and DFP modules.
Experimental Results
The effectiveness of GFF is demonstrated through extensive experiments conducted on several benchmark datasets, including Cityscapes, Pascal Context, COCO-stuff, and ADE20K. The proposed method achieves superior performance metrics, notably achieving 82.3% mIoU on the Cityscapes test set, outperforming previous methods in terms of both accuracy and computational efficiency (Figure 4).

Figure 4: Visualization of segmentation results showing GFF's ability to refine object boundaries and capture distant missing objects.
Comparative Analysis
GFF was compared to other fusion strategies like concatenation, addition, and FPN. The gated approach demonstrated substantial improvements over these methods, highlighting the effectiveness of selective fusion enabled by the gating mechanism. Furthermore, additional enhancements through DFP and multi-scale inference further boosted mIoU scores, establishing the proposed approach as a leading method in semantic segmentation.
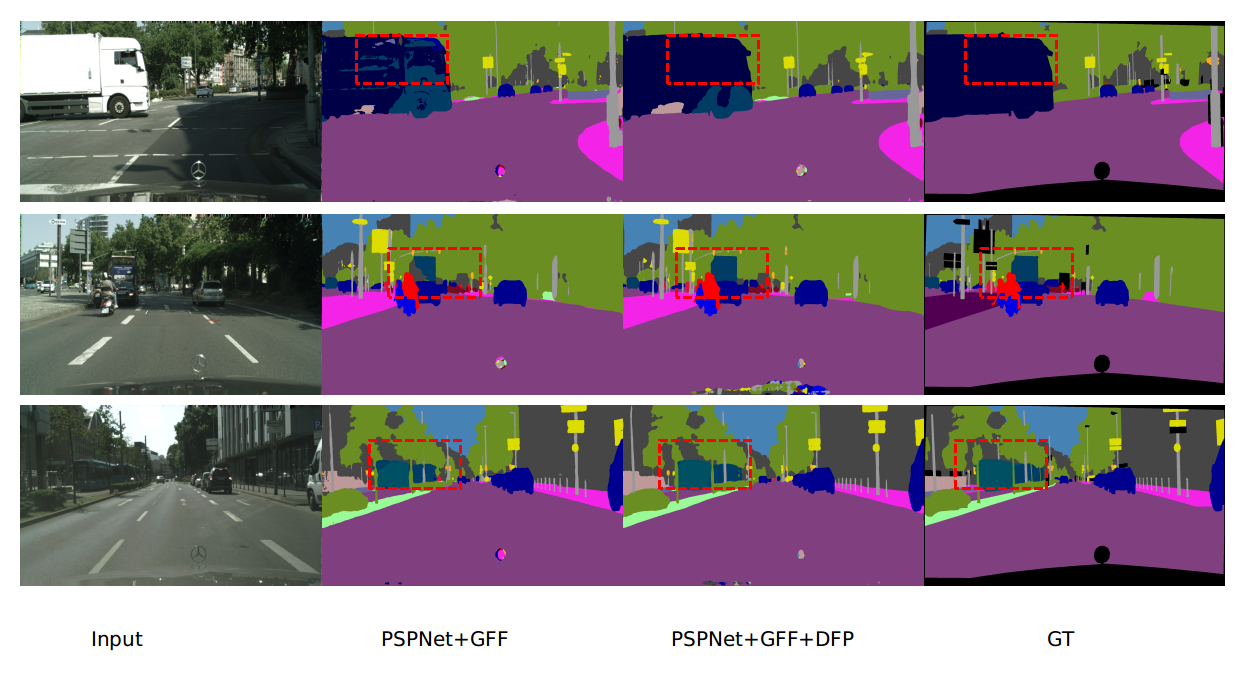
Figure 5: DFP enhances segmentation results for large-scale objects, generating consistent results.
Conclusion
The Gated Fully Fusion (GFF) method represents a significant advancement in semantic segmentation by addressing the limitations of existing approaches in capturing small and thin objects within complex scenes. By implementing a gating mechanism for selective feature fusion and augmenting contextual modeling through DFP, the method not only achieves state-of-the-art performance but also sets a foundation for future work in improving pixel-level annotations in diverse image datasets.
The implications of this research extend beyond theoretical developments, offering practical enhancements for vision-based systems in fields like autonomous navigation and real-time video analysis. Future work might explore the integration of GFF with more compact architectures for efficiency on resource-constrained platforms, expanding its applicability across broader AI domains.
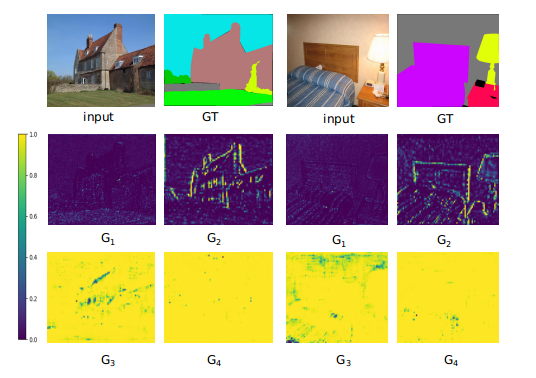
Figure 6: Visualization of learned gate maps, demonstrating effective control over information propagation.