- The paper introduces a dual-module system that integrates graphical models for segmentation proposal generation with a novel ConvNet, SegNet, for proposal ranking.
- It employs a surrogate UOI loss to maintain strong gradient signals, thereby directly optimizing segmentation metrics like IOU.
- Experimental validation on PASCAL VOC 2012 demonstrates a mean IOU of 52.5%, surpassing contemporary methods and highlighting the method’s robustness.
Integrating Graphical Models and ConvNets for Semantic Segmentation
Overview
The paper "Combining the Best of Graphical Models and ConvNets for Semantic Segmentation" (1412.4313) proposes a two-module framework for semantic segmentation in which the complementary strengths of graphical models and convolutional neural networks (ConvNets) are exploited synergistically. In this architecture, graphical models generate a compact set of diverse, high-quality segmentation proposals, which are subsequently ranked using a novel ConvNet, termed SegNet, optimized for segmentation-specific losses. The authors emphasize direct optimization of corpus-level performance metrics, specifically PASCAL's Intersection-over-Union (IOU), and introduce Union-over-Intersection (UOI) as a surrogate objective with improved gradient properties. The framework produced a mean IOU of 52.5% on the PASCAL 2012 segmentation challenge, matching or exceeding the state of the art.
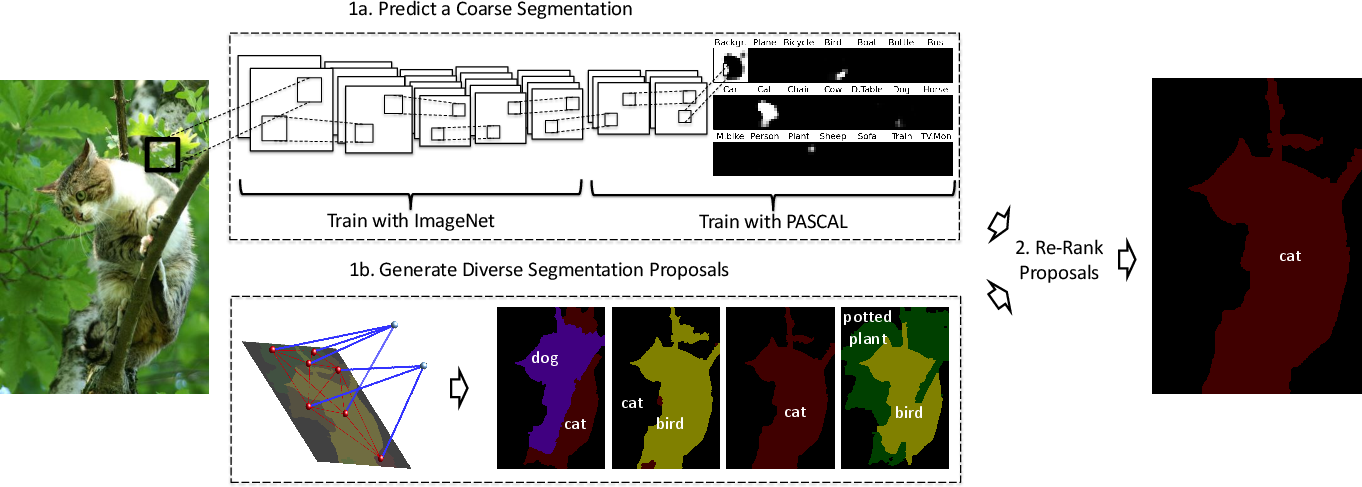
Figure 1: The proposed architecture: 1a depicts direct coarse semantic segmentation from SegNet; 1b, parallel CRF-based generation of segmentation proposals; (2) SegNet-based ranking of proposals.
Technical Contributions
The SegNet Architecture
SegNet departs from typical patch-level classification pipelines by producing a coarse semantic segmentation of the entire image. The architecture consists exclusively of convolutional layers, eliminating fully connected layers, thereby reducing parameter count and mitigating overfitting risks for data regimes with limited pixel-level supervision (e.g., PASCAL 2012). The initial convolutional layers are transferred from ImageNet-pretrained AlexNet models, after which additional task-specific layers are learned using segmentation data. Output is a set of class probabilities for each spatial position in a coarse (13×13) grid, providing a holistic prediction of object presence across the scene.
Unlike prior approaches which typically employ post-hoc graphical models or CRFs to smooth CNN predictions, the proposal mechanism here is upstream: proposals are generated by graphical models and then scored using the global, task-aware CNN. This strategy enables SegNet to leverage the full context of an image for ranking, unconstrained by the resolution limitations imposed by deep architectures.
Loss Function and Optimization
The central segmentation metric, mean IOU, is non-decomposable and defined at the corpus level. Directly optimizing IOU is shown to exhibit poor convergence properties due to vanishing gradients when the number of errors increases. To circumvent this, the authors introduce minimization of UOI as a training target; its gradient maintains stronger signals in more errorful regimes.
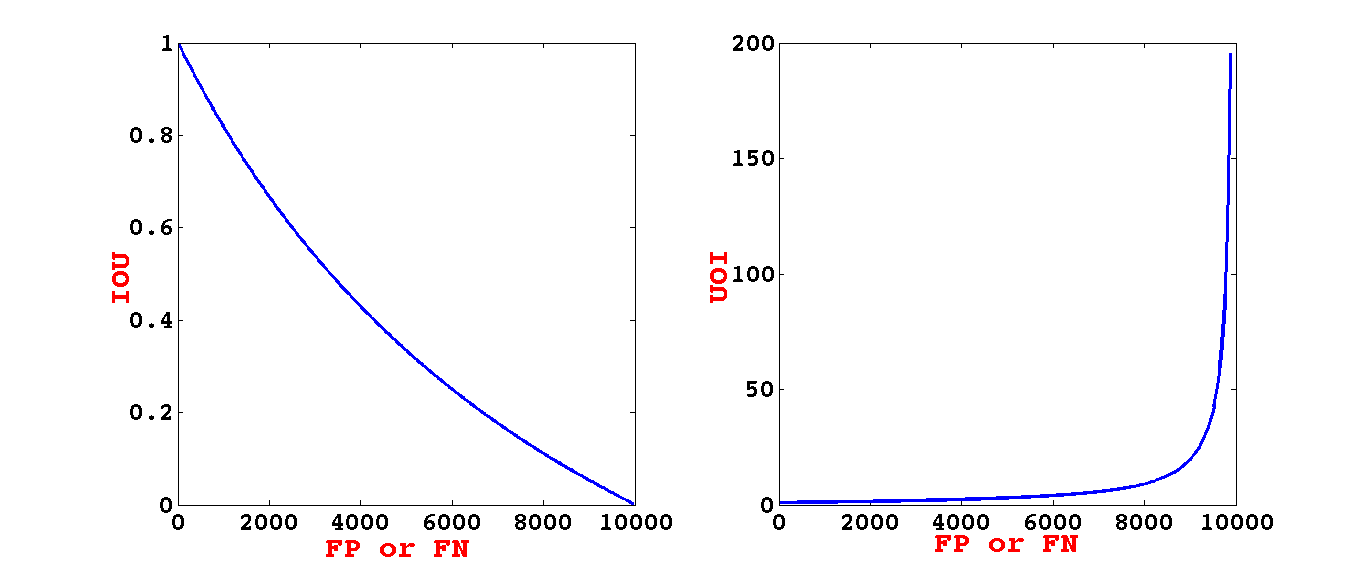
Figure 2: IOU and UOI loss behaviors under synthetic error injection: UOI retains higher gradients across error regimes, facilitating optimization.
Moreover, the UOI objective is proven to tightly lower-bound IOU, ensuring that improvement in the surrogate leads directly to improvement in the actual evaluation metric.
Segmentation Proposal Generation and Ranking
The proposal generation system adopts the O2P + DivMBest pipeline, which assembles approximately 10–30 diverse, full-image segmentations via second-order pooled features and greedy pasting, followed by diversity maximization. SegNet then re-ranks these segmentation proposals, either via KL-divergence-based scoring against its own coarse predictions, or more comprehensively with a learned SVM using rich features (SegNet-based, classification SVM, and hand-engineered proposal descriptors).
The final segmentation is selected via SVM ranking, which takes as input both SegNet-based score features and a variety of proposal- and classification-derived statistics.
Experimental Results
The framework is evaluated on the PASCAL VOC 2012 segmentation benchmark. The results demonstrate that the SegNet+SVM pipeline achieves an average IOU of 52.5%, outperforming contemporary baselines such as SDS and UDS, and achieving a notable gain over best-prior pipeline methods. Performance ablation indicates that each component—SegNet features, classification SVM features, and hand-crafted proposal features—contributes positively, and their combination is necessary for maximal predictive accuracy. Direct coarse upsampling or simple superpixel-based upsampling of SegNet predictions is found to be insufficient, with proposal reranking yielding large absolute gains.
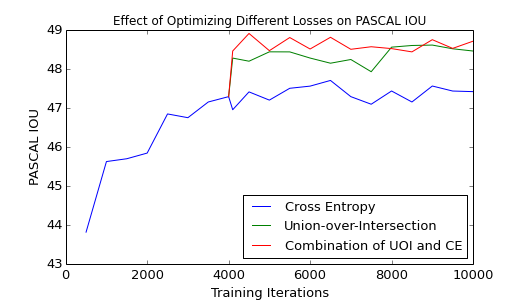
Figure 4: Comparison of SegNet reranking performance using models trained with cross-entropy, UOI, and a linear combination; joint loss yields best results.
Furthermore, optimizing the combination of UOI and cross-entropy losses provides additional performance benefits, suggesting complementarity in traditional and structured losses.
Qualitative Analysis
SegNet outputs, even at coarse resolution, reflect strong scene-level recognition and effective size/scale reasoning. However, coarse predictions struggle with fine object localization and discriminating among closely spaced instances, motivating the necessity of the proposal reranking stage.
Figure 5: The SVM ranker supplements SegNet’s recognition in challenging localization cases and compensates for proposal set coverage deficiencies.

Figure 6: SegNet’s probabilistic soft outputs enable reasonable object scale selection, even when ground-truth objects are small or ambiguous.
Practical and Theoretical Implications
This work reframes semantic segmentation pipelines by demonstrating that, for structured vision problems, global context from CNNs can be harnessed effectively in proposal ranking rather than generation. The approach enables the CNN to model semantic relationships at the image level, alleviates dependency on high-capacity upsampling architectures, and—by focusing only on proposal scoring—avoids trade-offs between context and localization. The use of a structured surrogate loss (UOI) for end-to-end training presents a template for other structured prediction tasks where first-order optimization of non-decomposable metrics is challenging. Practically, this pipeline is able to achieve highly competitive results with relatively modest data volumes, owing to careful network parameterization and transfer learning.
Theoretically, the integration of large-field CNNs and graphical model proposals opens a pathway for the co-evolution of structured and deep methods. It further exposes limits on what CNNs can learn from limited (pixel-wise) supervision and highlights the continued relevance of graphical models and hand-engineered feature representations.
Future Directions
Further gains are expected from larger, denser datasets (e.g., COCO) and more sophisticated proposal mechanisms. The bottleneck of hard proposal set coverage persists—missed proposals limit even perfect rankers. Integrating proposal generation more tightly with CNN-based scoring, e.g., learning proposal features jointly with ranking, is a promising avenue. Additionally, a path forward lies in eliminating hand-engineered features via fully, or partially, end-to-end architectures capable of jointly optimizing all stages, given sufficient data and computational resources.
Conclusion
The proposed two-module system—graphical models for proposal generation, SegNet for holistic, structured proposal ranking—exemplifies a pragmatic fusion of model families for scene segmentation. The direct optimization of a segmentation-aware surrogate loss and the architecture's robustness to limited data undergird its strong empirical results. The work delineates both the promises and remaining challenges of integrating structured and deep representations for pixel-wise semantic tasks, offering a foundation for future methodological and architectural innovations.