- The paper introduces a method leveraging RNNs to approximate causal states, linking bisimulation with predictive state representations for optimal policy learning.
- It presents a gradient-based algorithm that minimizes prediction errors to derive robust state abstractions in both discrete and continuous environments.
- Empirical results show superior learning speed and stability in RL across gridworlds, VizDoom, and Atari games, validating the theoretical framework.
Learning Causal State Representations of Partially Observable Environments
Introduction
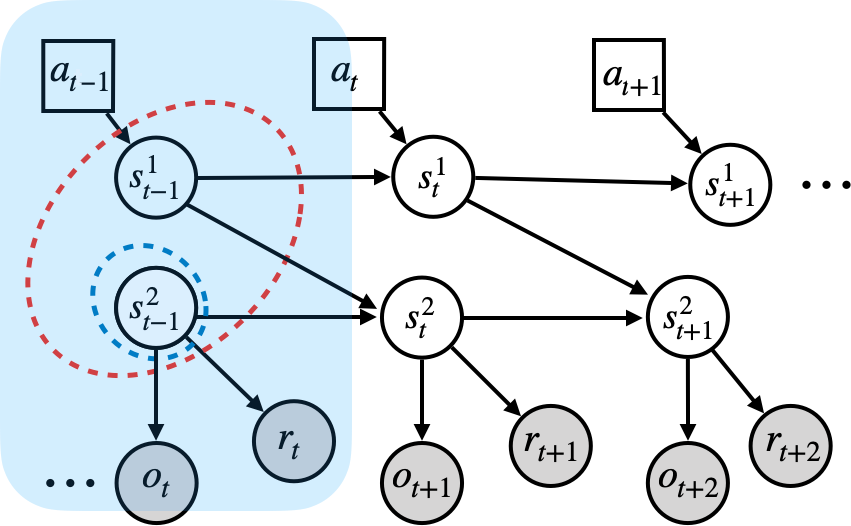
The paper "Learning Causal State Representations of Partially Observable Environments" (1906.10437) presents an approach to improve the efficiency of reinforcement learning (RL) in complex environments by leveraging task-agnostic state abstractions. The authors propose approximating causal states, which represent the coarsest partition of action and observation histories in partially observable Markov decision processes (POMDPs). Using recurrent neural networks (RNNs), the proposed method predicts subsequent observations based on historical data, thereby learning state representations that facilitate efficient policy learning in RL problems with rich observation spaces.
Methodology
Central to the paper is the novel connection between predictive state representations (PSRs) and bisimulation through causal states. Causal states derive from the computational mechanics literature as the minimal partitions of past histories that maximize predictability of future observations. The paper formalizes this connection by equating causal states to bisimulation relations, which are abstractions that preserve behavioral equivalence in systems. With this theoretical underpinning, the authors develop a gradient-based algorithm that learns causal state representations, ensuring optimal policy derivation for RL tasks by minimizing prediction errors.
Theoretical Contributions
The paper offers several critical theoretical insights:
- Bisimulation and Causal States: It establishes that causal states are equivalent to the coarsest bisimulation partition, ensuring a robust abstraction of environment dynamics.
- Value Function Bounds: By linking causal states to bisimulation metrics, the work provides lower bounds on the optimal value function—quantifying the suboptimality of learned representations relative to the true environment.
- Causal Feature Sets: The connection to causal inference literature situates causal states within a broader context of invariant prediction, implicating certain interventionist requirements for training data diversity to learn causal predictors effectively.
Empirical Evaluation
Empirically, the method is validated across discrete and continuous environments:
Practical Implications
Practically, this research advances RL in partially observable environments by enhancing the agent's ability to retain and utilize historical information optimally. This capability is vital for decision-making in complex, high-dimensional settings like autonomous navigation and strategic game playing. Bisimulation-based bounds facilitate deployment in real-world applications by offering guarantees on the action-value functions derived from learned representations.
Conclusion
This work pioneers a methodologically rigorous approach for RL in partially observable contexts by harnessing causal state abstractions. While the empirical implementations face challenges in discrete optimization and rich observation settings, the groundwork laid by this paper—specifically the unification of causal states, bisimulation, and invariant prediction—proposes a novel paradigm for learning representations that are both theoretically grounded and practically applicable. Future developments could explore end-to-end solutions and alternative discretization strategies to further solidify the robust deployment of causal states in RL applications.