- The paper's main contribution is integrating self-supervised learning with adversarial training by maximizing mutual information between clean and adversarial examples.
- It demonstrates superior robustness on benchmarks like CIFAR-10 and STL-10, outperforming traditional supervised adversarial methods with higher defense success rates.
- The proposed SAT framework efficiently alternates between adversarial sample generation and MI maximization, offering a scalable, label-free approach to boost model robustness.
Self-supervised Adversarial Training
Introduction
The susceptibility of deep neural networks (DNNs) to adversarial examples has prompted extensive research into improving model robustness. Conventional approaches such as adversarial training (AT) have been beneficial, but a novel perspective involves the use of self-supervised learning (SSL) to enhance model robustness. "Self-supervised Adversarial Training" explores this concept by integrating SSL with adversarial training to maximize mutual information (MI) between clean and adversarial examples, thereby fortifying the model against adversarial attacks.
Methodology
Self-supervised Representation
The primary objective is to leverage self-supervised features for classification using k-Nearest Neighbour (kNN). SSL intrinsically focuses on learning robust, semantic embeddings by predicting parts of the data from itself. This process inherently aligns with the goals of adversarial robustness, as SSL is designed to discern invariant features that are less susceptible to perturbations inherent in adversarial examples.
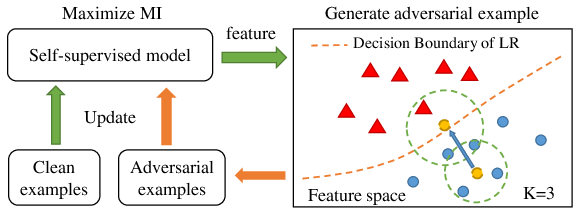
Figure 1: The diagram of self-supervised adversarial training.
Self-supervised Adversarial Training (SAT)
SAT advances the robustness of self-supervised models by maximizing MI between feature representations of clean images and their adversarial counterparts. This involves two key components: the generation of adversarial samples and the optimization of MI.
- Adversarial Sample Generation: Building on the Projected Gradient Descent (PGD) method, adversarial examples are crafted by iteratively adjusting the input image to maximize perturbation within an ϵ-ball constraint.
- Maximizing Mutual Information: By employing a noise contrastive estimator (NCE), MI between the feature representations of clean and adversarial examples is computed. The objective is to minimize the contrast loss, defined as the negative estimated MI, thereby ensuring robust feature alignment.
Algorithm Implementation
The SAT framework iteratively fine-tunes a pre-trained self-supervised model by alternating between adversarial sample creation and MI maximization. This process does not require labeled data, thus maintaining the self-supervised premise.
Experiments
Using AMDIM as a benchmark, self-supervised representations (SSL) demonstrated superior robustness compared to supervised counterparts (SUP), especially on CIFAR-10 and STL-10 datasets. For instance, on CIFAR-10, SSL's Defense Successful Rate (DSR) significantly eclipsed that of SUP, validating the enhanced robustness imparted by self-supervised learning.
Efficacy of SAT
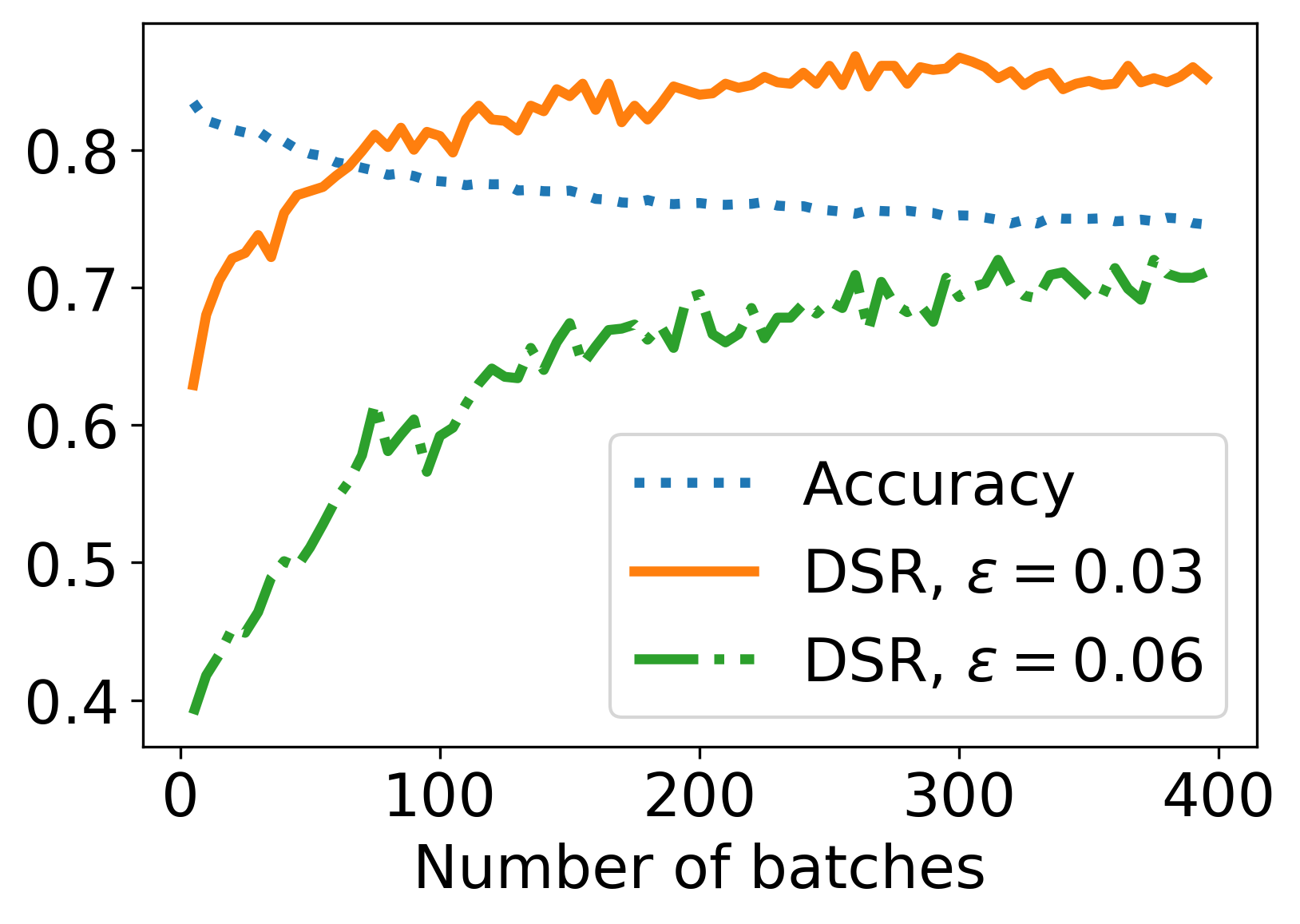
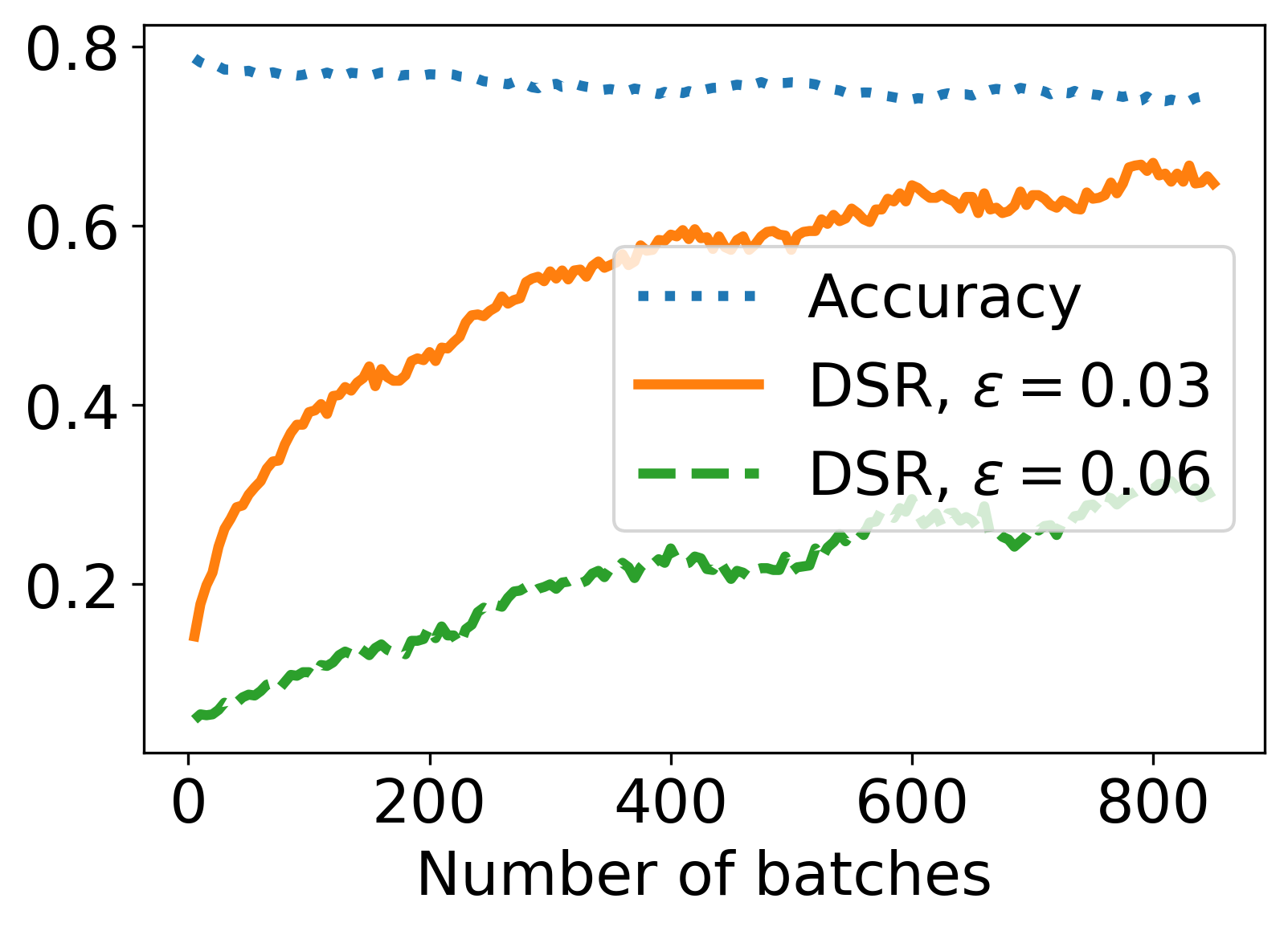
Figure 2: The defense results of AMDIM and NPID using SAT on CIFAR-10.
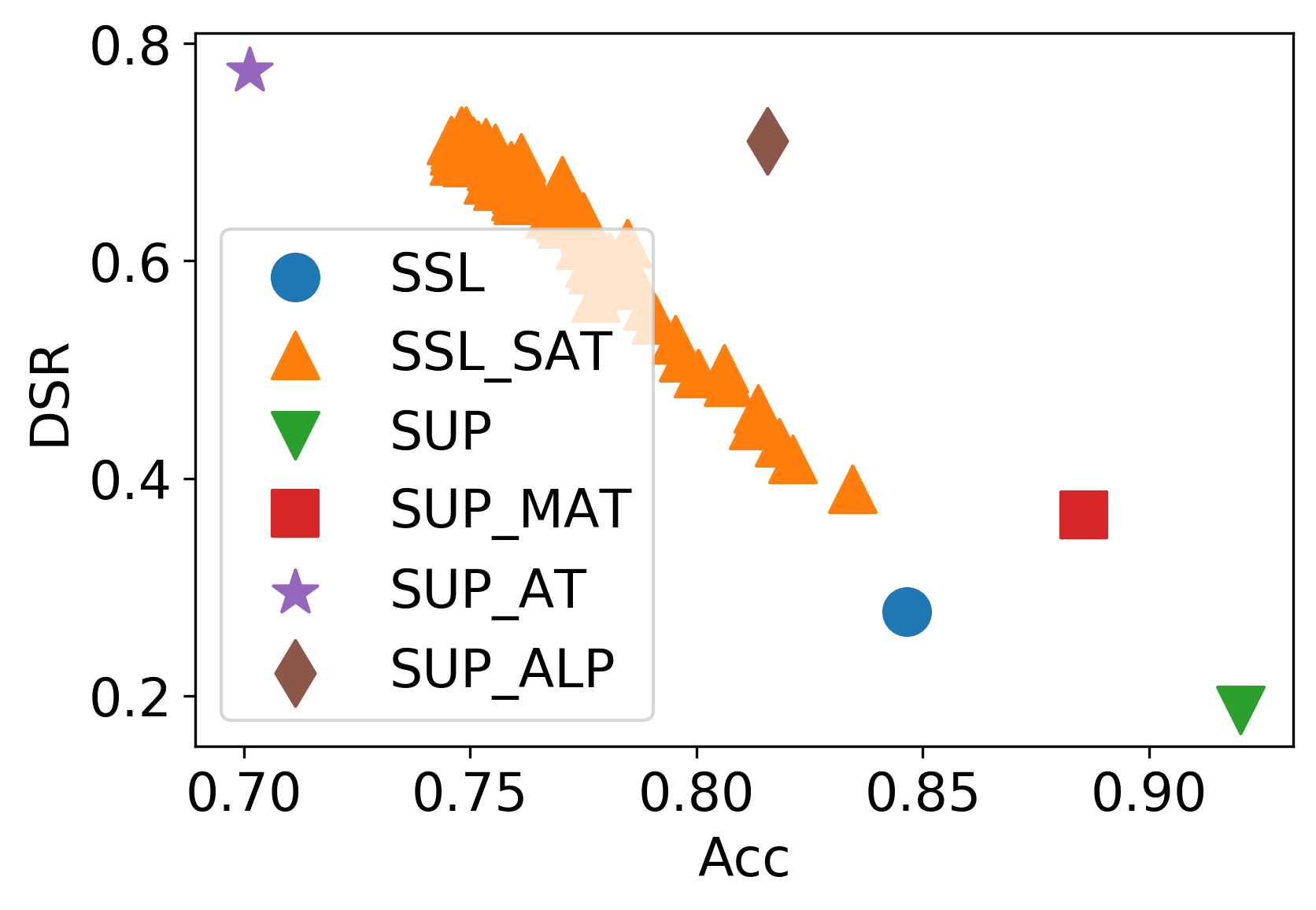
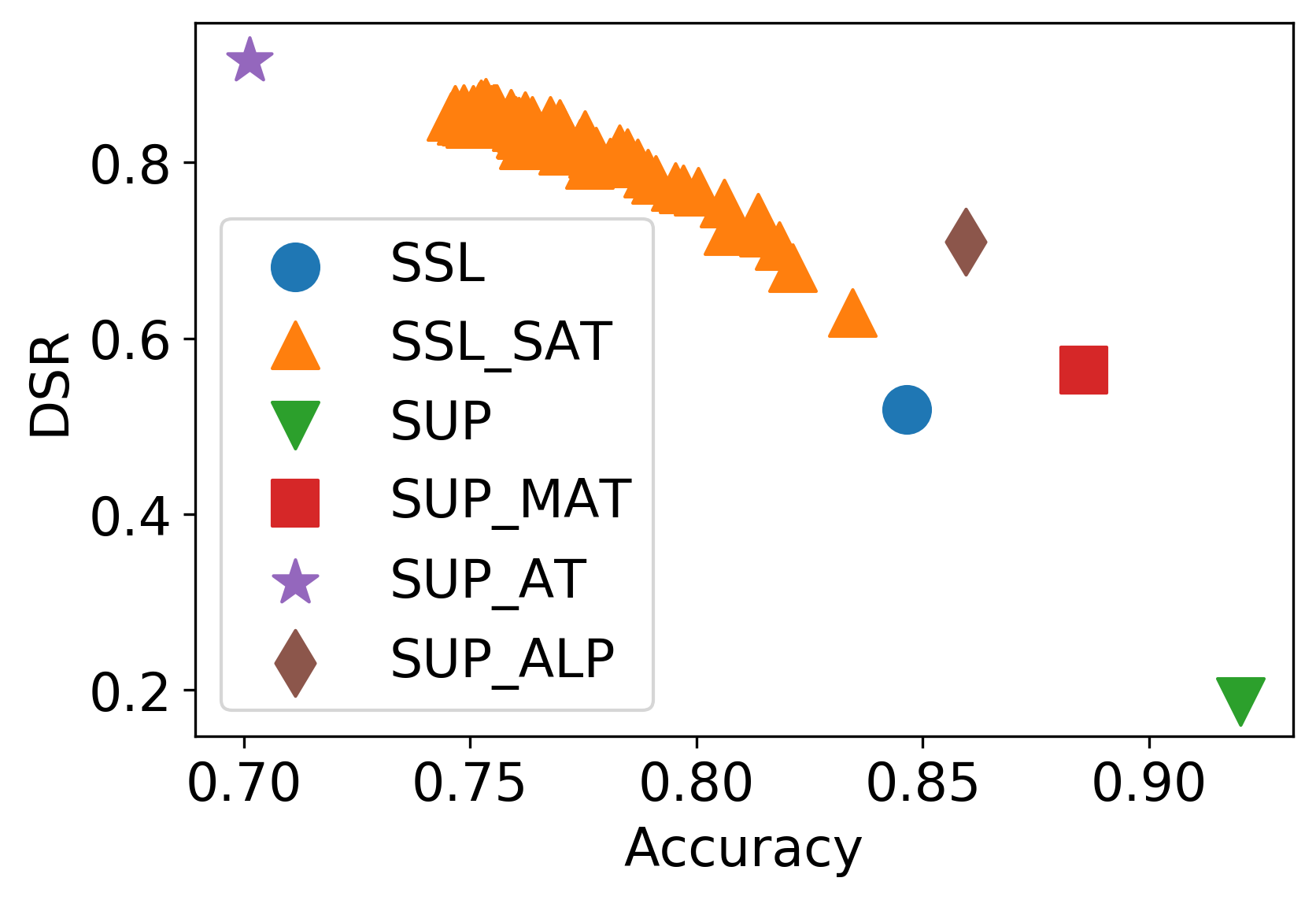
Figure 3: The defense results of among self adversarial training and supervised adversarial training on CIFAR-10. AMDIM is selected as the seed model, and SUP and SSL mean the supervised and self-supervised version.

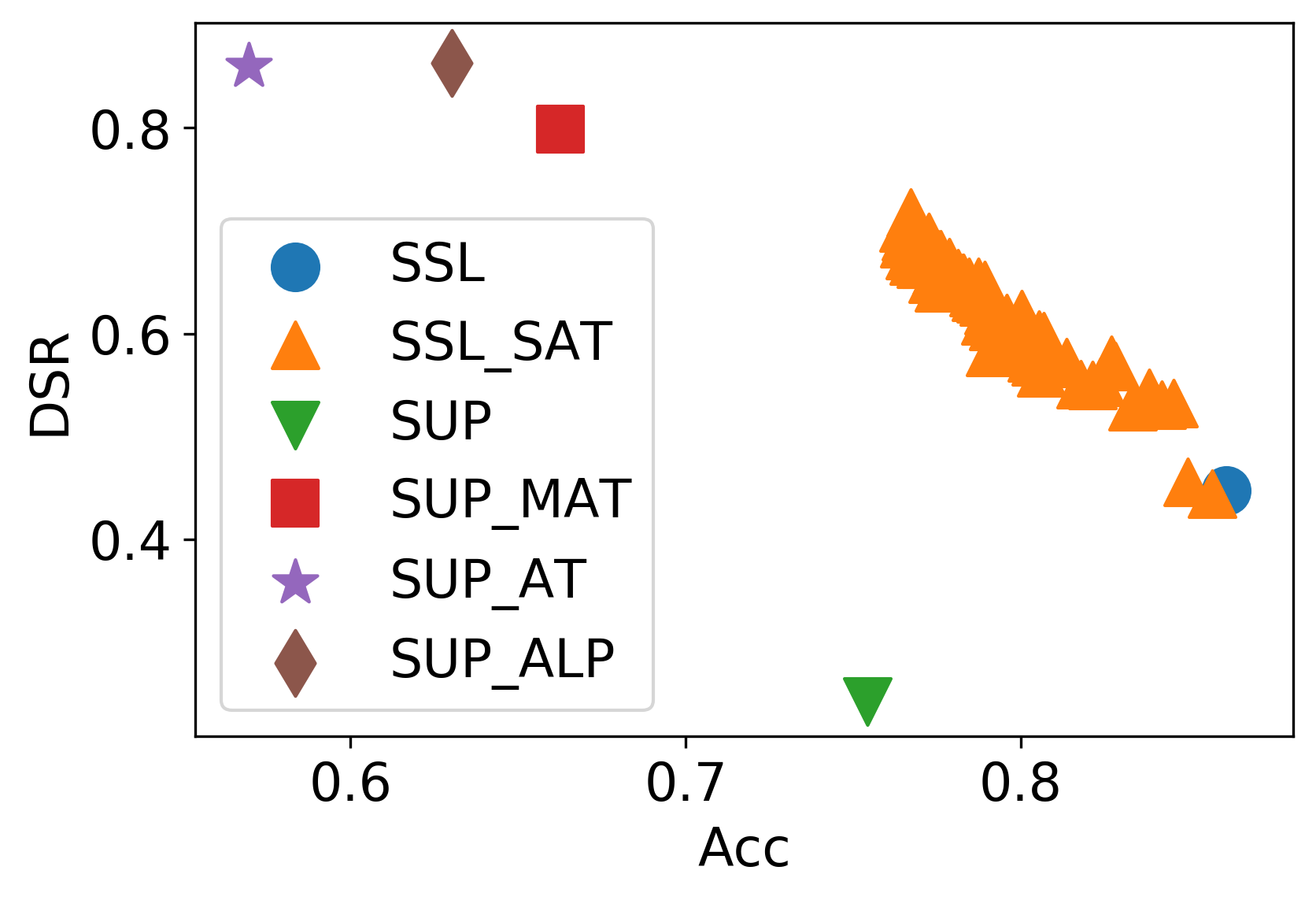
Figure 4: The defense results of among self adversarial training and supervised adversarial training on STL-10.
In SAT's efficacy trials, integrating NPID and AMDIM models, substantial improvements in DSR were observed across varying levels of perturbation. The time efficiency of SAT compared to traditional adversarial trainings, such as MAT and ALP, highlights its practical applicability in environments where labeled data is scarce or the computational budget is constrained.
Conclusion
The research bestows a promising augmentation to adversarial defenses by coupling self-supervised representations with adversarial training. Notably, self-supervised adversarial training offers a scalable, label-free method to boost model robustness against adversarial missteps. Future research avenues could explore self-supervised learning strategies that inherently account for adversarial dimensions during the training phase, potentially obviating the need for post-hoc adversarial reinforcement.