- The paper introduces a projection neural network framework that uses a novel smoothing function to approximate the L0 penalty in sparse regression.
- It rigorously proves global existence, uniqueness, and convergence of the neural ODE system while maintaining tangible support recovery and thresholding properties.
- Empirical results demonstrate competitive performance in compressed sensing and high-dimensional regression, yielding lower MSE and effective variable selection.
Projection Neural Network for Sparse Regression with Cardinality Penalty
Sparse regression with explicit cardinality (L0) penalization is a canonical yet notoriously challenging problem in signal processing, statistical learning, and compressed sensing. Traditional convex relaxations (e.g., L1, Lp penalties, SCAD, MCP) either introduce substantial estimation bias or struggle with controllable approximation to the combinatorial nature of support selection. Recent progress in neural dynamical systems for continuous optimization inspires exploration of neural network-based solvers for nonconvex and discontinuous objectives, but previous designs largely omit direct treatment of cardinality penalization.
The paper proposes an explicit neural network implementation for the sparse regression objective
minx∈Xf(x)+λ∥x∥0
with box constraints X={x∈Rn:0≤x≤v}, and f convex and continuously differentiable. The authors introduce a smoothing function Θ(x,μ) to approximate the non-differentiable ∥x∥0, enabling the formulation of a globally well-behaved dynamical system whose equilibrium points connect to solutions of the original objective.
Smoothing Function Design
The key technical device is the construction of the smoothing function Θ(x,μ), which closely tracks the ℓ0 penalty while affording differentiability and Lipschitz properties required for the neural network analysis:
Θ(x,μ)=∑i=1nθ(xi,μ),
where θ(s,μ) is a low-complexity piecewise-defined function linear for s<31μ, quadratic for s∈[31μ,μ], and flat for s>μ. This design preserves exact zeros, induces a hard threshold at the scale of μ, and is strictly smoother than popular nonconvex relaxations such as SCAD or capped-L1.
The function θ(⋅,μ) and its parameter sensitivity are illustrated for varying μ and s, elucidating the soft-to-hard threshold transition as μ↓0 (Figure 1).
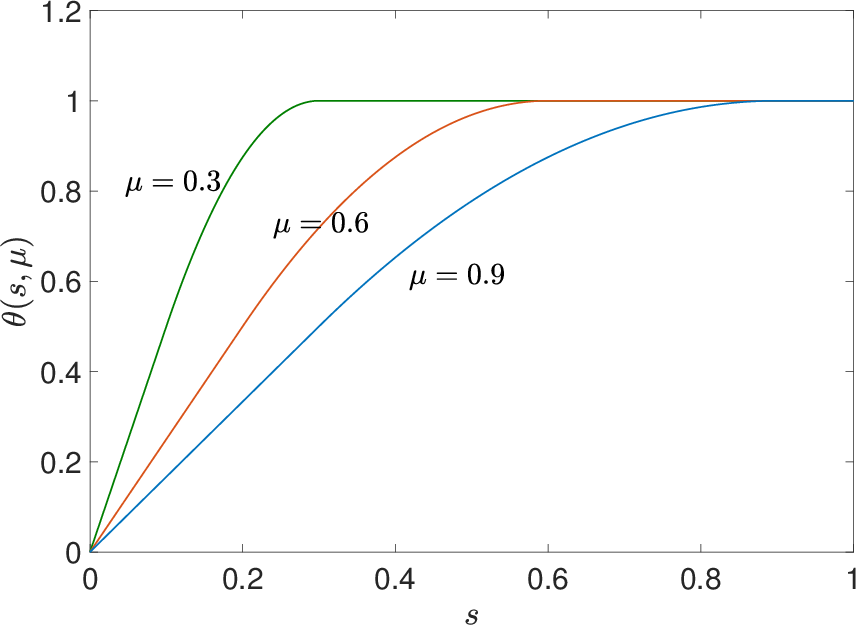
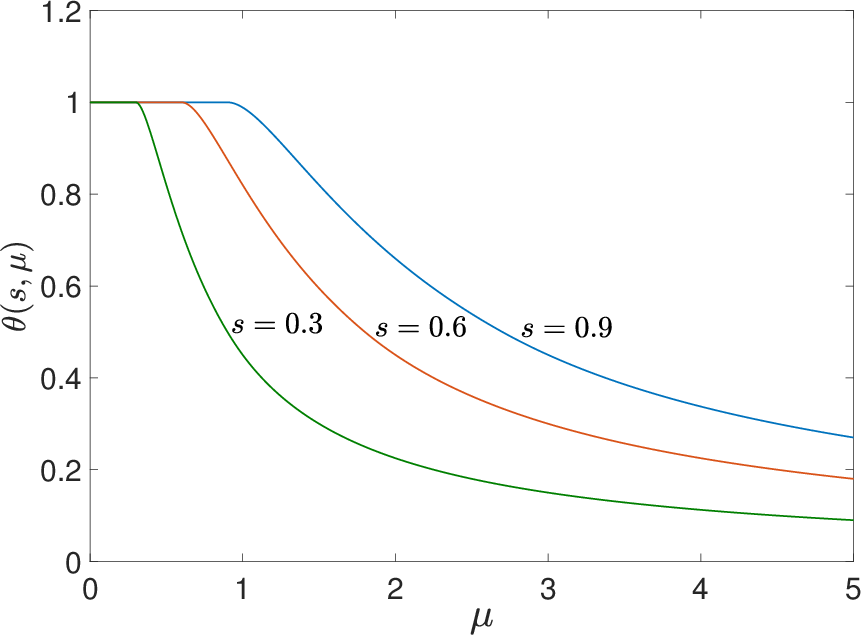
Figure 1: (a) The smoothing function θ(⋅,μ) with μ=0.3,0.6,0.9; (b) θ(s,⋅) for s=0.3,0.6,0.9.
The paper rigorously proves that this smoothing preserves continuity and global Lipschitz continuity of the gradient—a critical property for the existence, uniqueness, and convergence of solutions to the neural ODE system.
Projection Neural Network Construction
The authors construct a neural ODE of the form
x˙(t)=γ[−x(t)+PX(x(t)−∇f(x(t))−λ∇xΘ(x(t),μ(t)))],
driven by an annealed smoothing parameter μ(t), and initialized arbitrarily inside the box. This is a projection-type neural network, leveraging the explicit projector to enforce constraints at all times. In the limit μ(t)→0 as t→∞, the system's equilibrium connects to the stationary points of the original ℓ0 penalized objective.
A detailed schematic block diagram of the neural network's architecture is presented, indicating practical feasibility for hardware or parallel implementation.
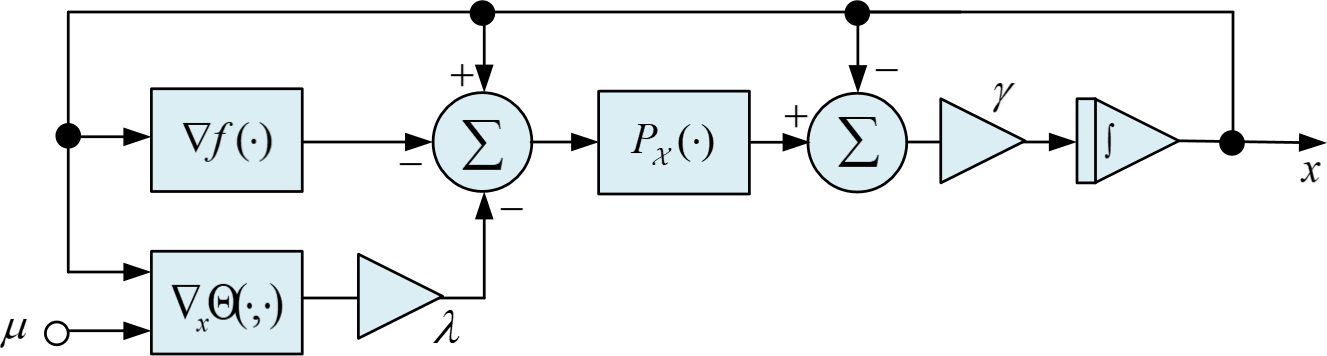
Figure 2: Schematic block structure of neural network for sparse regression with cardinality penalty.
Theoretical Analysis
The main theoretical contributions include:
- Global Existence, Uniqueness, and Boundedness: The system is globally well-posed and solutions remain inside the constraint box for all time.
- Convergence: The objective value f(x(t))+λΘ(x(t),μ(t)) is non-increasing along solution trajectories, and the velocity x˙(t)→0, ensuring convergence to stationary points.
- Common Support and Lower Bound: All accumulation points have a unified support and a strict lower bound on nonzero entries, proportional to the final μ∗ parameter.
The dynamical behavior is concretely illustrated via numerical simulations on small-scale test problems, showing monotonic convergence to global minimizers and decrease in objective values along the trajectories.
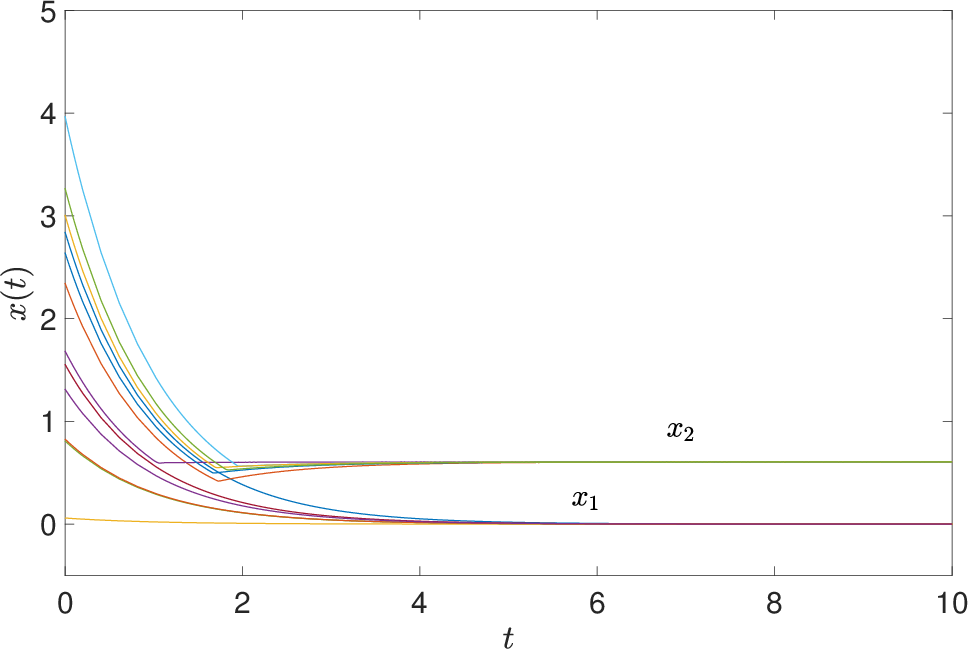
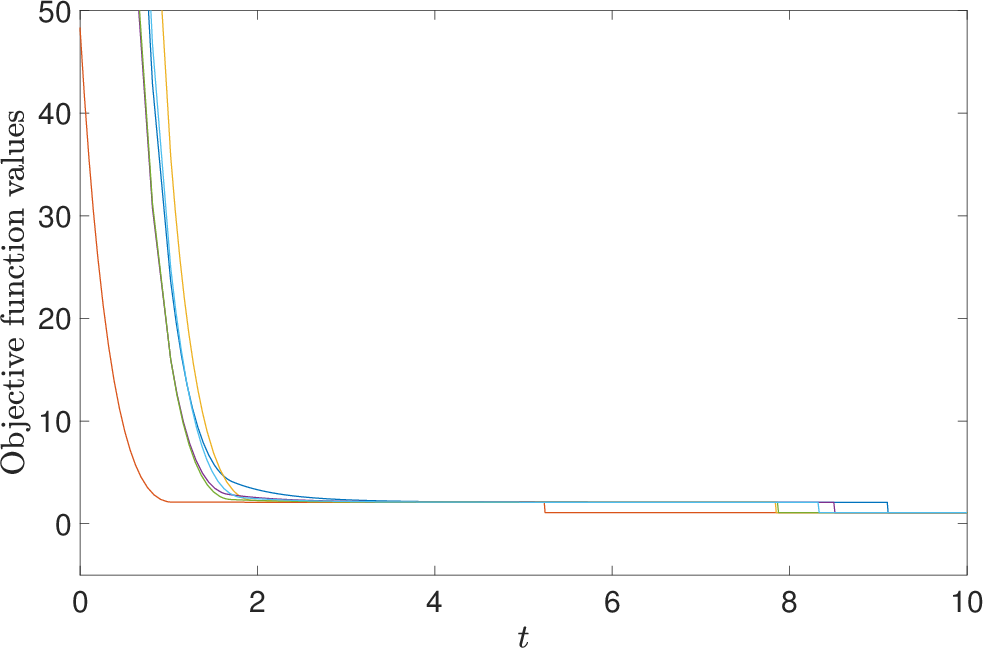
Figure 3: (a) State trajectories and (b) objective function values along neural network solutions.
Correction Method for Support Refinement
When accumulation points lie close to the threshold (i.e., with ambiguous support), a correction stage is employed. The method hard-thresholds at μ∗/2 to zero, then solves a convex subproblem over the fixed support to achieve a true local minimizer of the original sparse regression problem. The correction neural network is a standard projection neural network over the reduced support.
Extension to Sign-Free Regression
To encompass box constraints of the form −l≤x≤u (sign-free problems), the paper uses variable splitting x=x+−x− (with x+,x−≥0), reformulating the problem as an equivalent sparse regression in $2n$ variables. A proof of equivalence for local minimizers is supplied. The entire analysis and neural scheme transfer unchanged to this broader setting.
Empirical Evaluation
The algorithm demonstrates competitive empirical performance on:
- Synthetic Test Problems: Convergence to known global minima under various initializations.
- Compressed Sensing: High-accuracy signal recovery with low MSE, insensitivity to initialization, and preservation of true sparse support structure.
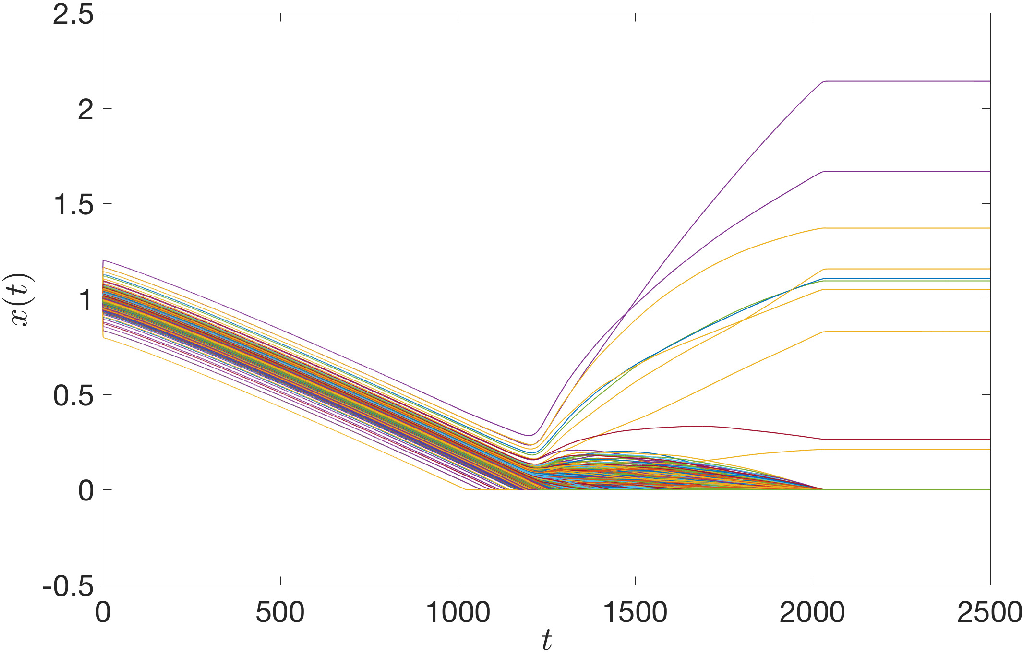
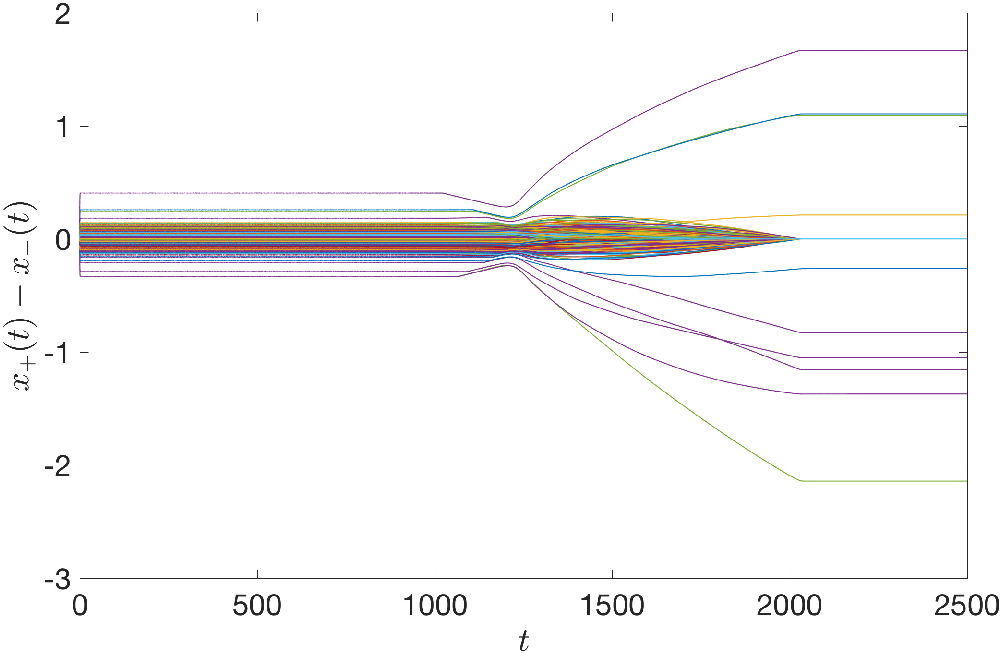
Figure 4: State trajectory x(t) and difference x+(t)−x−(t) during compressed sensing recovery.
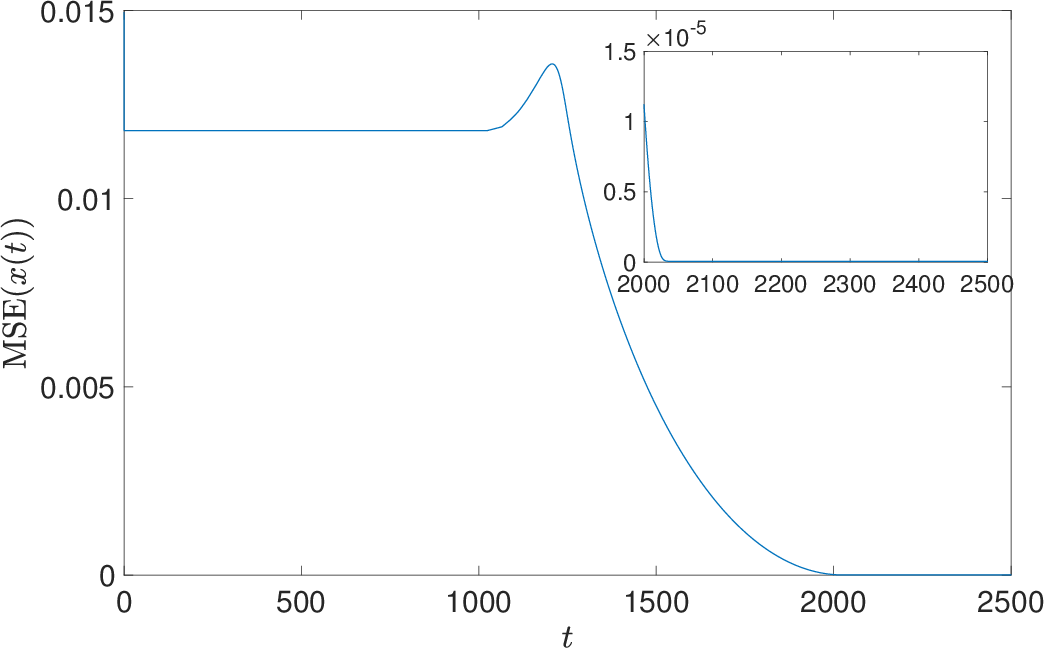
Figure 5: Evolution of mean squared error during compressed sensing.
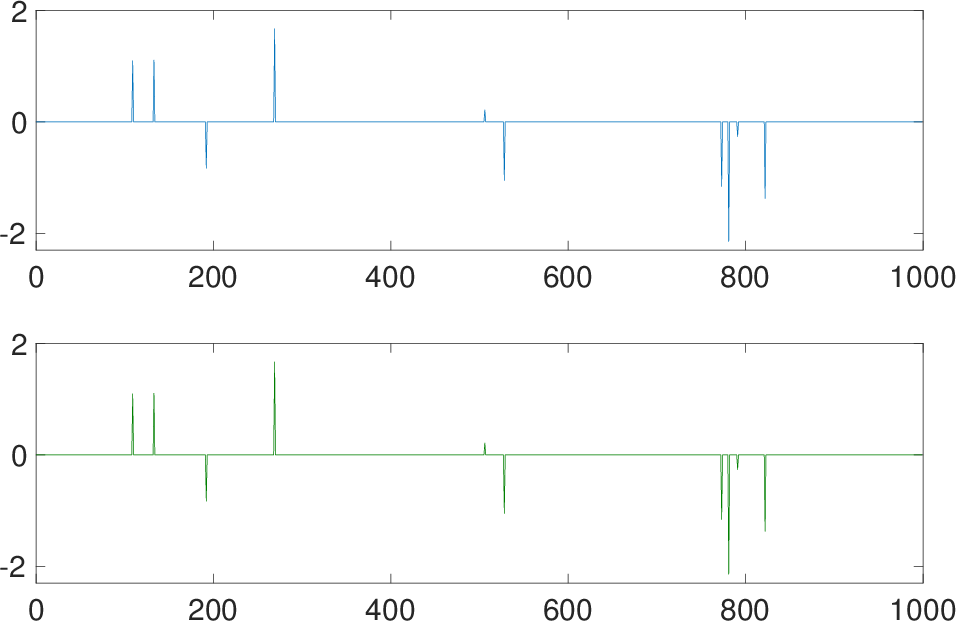
Figure 6: Comparison of true signal and reconstructed signal via neural network.
- High-Dimensional Regression (Variable Selection): Faster convergence and often lower MSE than contemporary neural network approaches for sparse regression.
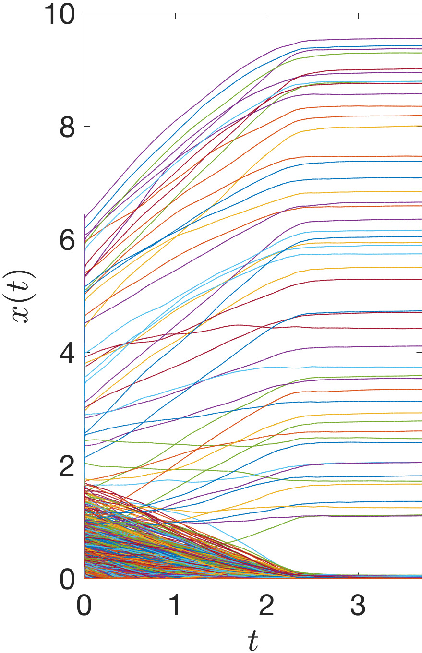
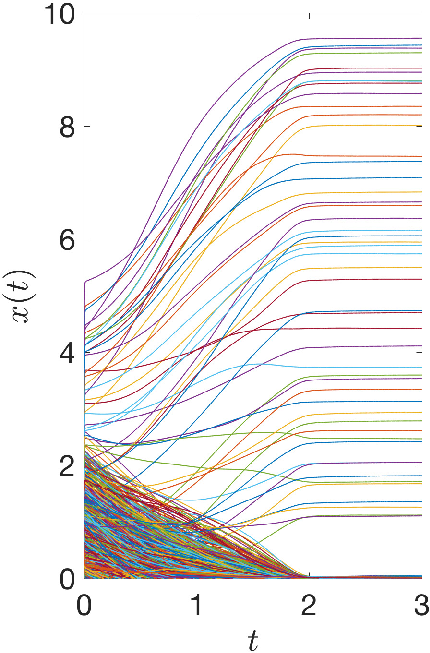
Figure 7: State trajectories of (a) proposed neural network, (b) SNN, and (c) LPNN for variable selection.
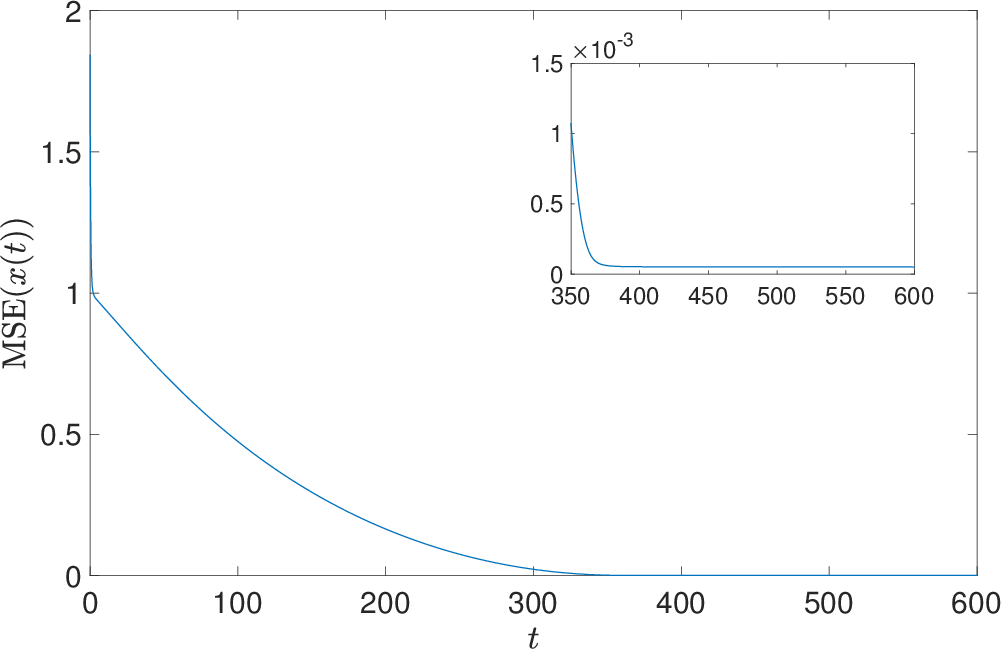
Figure 8: Mean squared error evolution for variable selection.
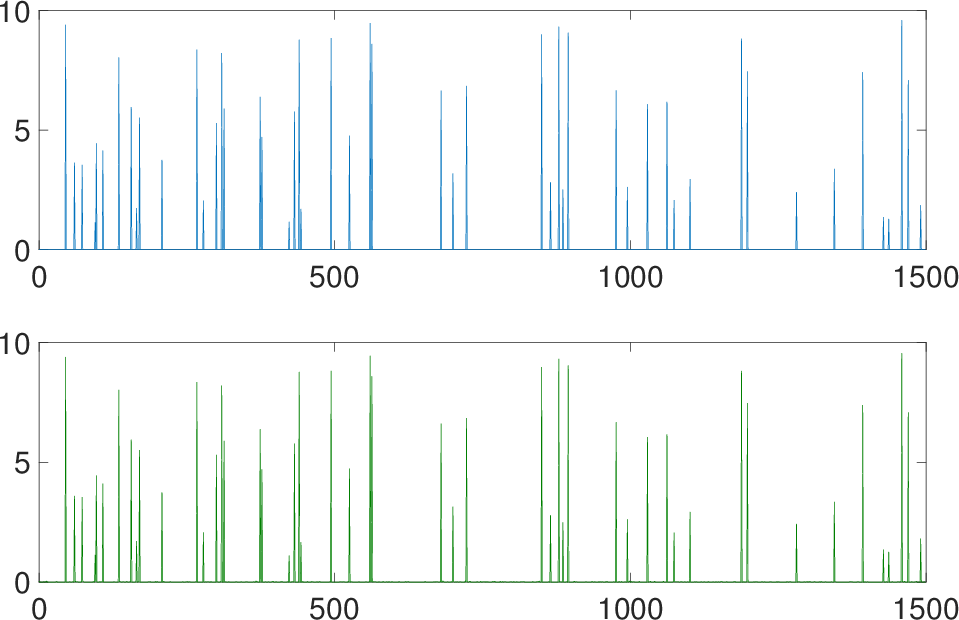
Figure 9: Comparison of original and predicted signals.
- Prostate Cancer Data: Lower test prediction error compared to Lasso, subset selection, and first-order iterative penalty solvers, with precisely three nonzero predictors matching substantive variable importance.
Implications and Future Directions
The methodology opens rigorous avenues for practical neural network solvers directly handling L0-penalized regression—enabling hardware acceleration, fast convergence, and compatibility with modern circuit or neuromorphic implementations. The smoothing technique balances strict adherence to combinatorial sparsity and analytical tractability within neural ODE frameworks. Extension to other nonconvex penalties, adaptive control of the smoothing schedule, and integration with neural architectures for unstructured or manifold constraints are promising directions for expansion.
From a theory perspective, the unified support property and provable lower bounds on nonzero entries address robustness, crucial in noisy or ill-posed regression. The seamless adaptation to split-variable (sign-free) models solidifies the practicality of the approach in diverse high-dimensional inference tasks.
Conclusion
The paper establishes a comprehensive framework for sparse regression with exact cardinality penalization via projection neural networks, introducing a principled smoothing function capable of bridging the gap between discontinuous combinatorial objectives and continuous-time dynamical optimization. Theoretical analysis guarantees global existence, convergence, support recovery, and competitive empirical performance, offering a viable alternative to convex relaxations for direct sparse modeling (2004.00858).