- The paper introduces DiffMPC, a GPU-accelerated differentiable MPC framework that exploits time-induced sparsity to speed up optimal control problem solving.
- It uses a custom preconditioned conjugate gradient solver with tridiagonal preconditioning and implicit differentiation to enhance computational efficiency.
- Empirical evaluations show 2x to 7.3x speedups on RL and IL benchmarks, with improved robustness in real-world vehicle control tasks.
Differentiable Model Predictive Control on the GPU: Algorithmic Innovations and Empirical Evaluation
Introduction and Motivation
The paper presents DiffMPC, a GPU-accelerated differentiable model predictive control (MPC) framework designed to address the computational bottlenecks inherent in differentiable optimal control. Traditional differentiable MPC solvers are limited by sequential optimization routines, which restrict parallelization and scalability on modern hardware. DiffMPC leverages problem structure—specifically, the time-induced sparsity of optimal control problems (OCPs)—to enable efficient parallelization via a custom preconditioned conjugate gradient (PCG) solver with tridiagonal preconditioning. The implementation in JAX facilitates integration with machine learning pipelines, supporting large-scale reinforcement learning (RL) and imitation learning (IL) tasks.
Algorithmic Framework
DiffMPC solves and differentiates through OCPs of the form:
z=(x,u)mint=0∑Tctx,θ(xt)+t=0∑T−1ctu,θ(ut)s.t.ftθ(xt+1,xt,ut)=0,x0=xsθ
where costs, constraints, and initial conditions are parameterized by θ (e.g., neural network weights, physical parameters).
Forward Pass: Sequential Quadratic Programming (SQP)
The non-convex OCP is solved via SQP, which iteratively approximates the problem as a parametric quadratic program (QP) with linearized dynamics and quadratic costs. The KKT system for the QP is constructed, exploiting block-sparse structure for parallel evaluation of matrices over time steps. The solution is obtained by solving the KKT system:
[GH⊤ H0][z λ]=[−b d]
Backward Pass: Implicit Differentiation
Gradients with respect to θ are computed using the implicit function theorem, requiring the solution of a linear system with the same KKT matrix as the forward pass. This enables efficient computation of vector-Jacobian products (VJP) for downstream learning tasks.
GPU-Accelerated Linear Solves
DiffMPC employs a PCG routine with symmetric stair (tridiagonal) preconditioning to solve the Schur complement system arising from the KKT conditions. This approach exposes parallelism over time steps and supports warm-starting, which is critical for MPC applications with repeated solves.
Implementation Details
- Line Search: A parallelized merit function-based line search is used for robust SQP convergence.
- Warm-Starting: Both forward and backward passes can be warm-started, leveraging previous solutions for faster convergence.
- Parallelism: All matrix evaluations and PCG iterations are parallelized over time steps and batch instances.
Empirical Evaluation
RL and IL Benchmarks
DiffMPC is benchmarked against state-of-the-art differentiable solvers: Theseus, mpc.pytorch, and Trajax. On GPU, DiffMPC achieves 4x speedup over the fastest baseline for RL tasks with batch sizes as low as 64. On nonlinear attitude stabilization, DiffMPC achieves a 7.3x speedup over Trajax for the backward pass.
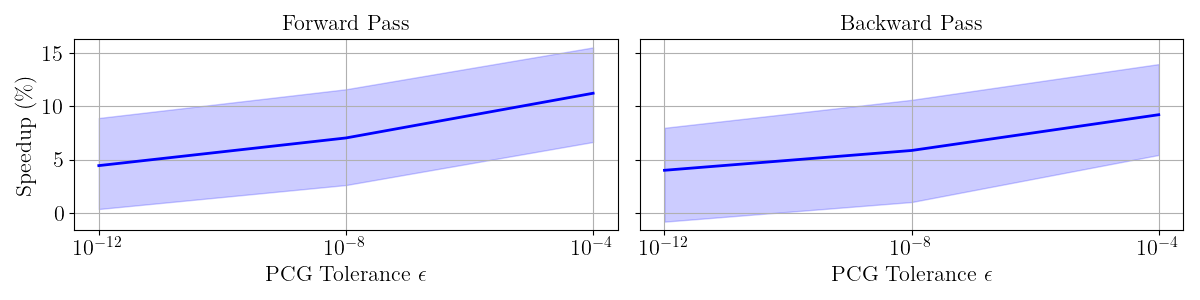
Figure 1: RL with DiffMPC: Speedups from warm-starting SolveTimecoldSolveTimecold−SolveTimewarm for different PCG exit tolerances, with ±2 standard deviation intervals.
Warm-starting yields additional speedups, especially for relaxed PCG tolerances, with up to 11% improvement for the forward pass at ϵ=10−4.
Imitation Learning
On a cart-pole IL benchmark, DiffMPC trains 2x faster than Trajax, demonstrating superior end-to-end training efficiency for nonlinear dynamics.
Robust Drifting via RL and Domain Randomization
DiffMPC is applied to RL-based tuning of an MPC controller for drifting a Toyota Supra through water puddles. Domain randomization is used to vary tire friction and initial conditions, enabling the learned controller to robustly handle model mismatch and disturbances.
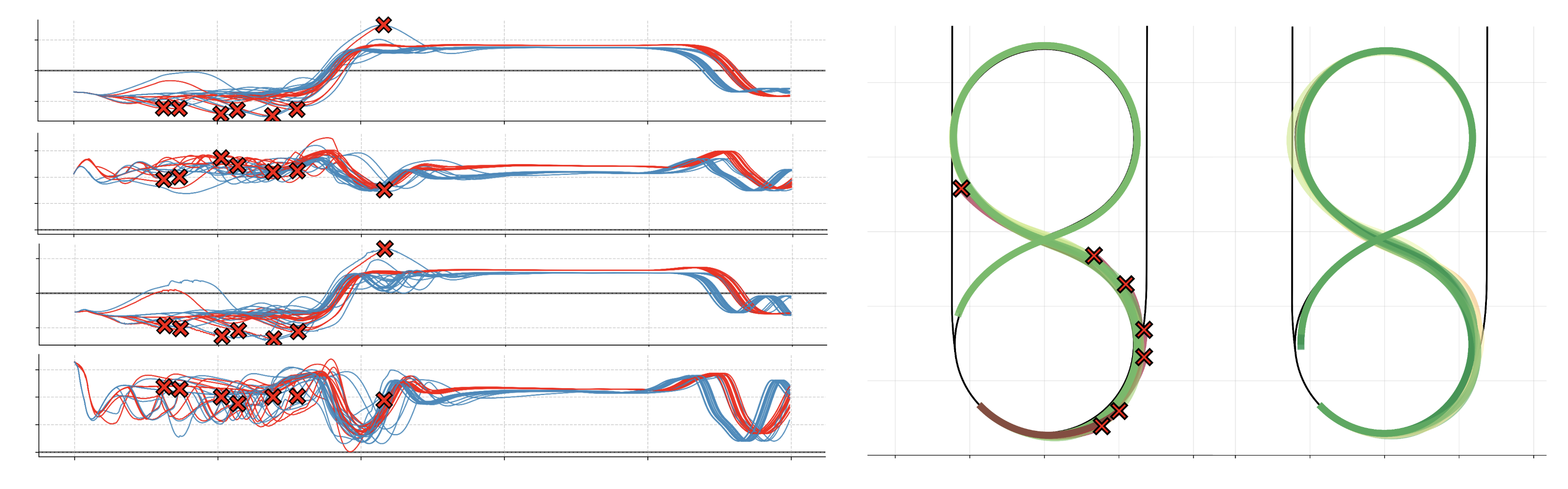
Figure 2: Vehicle states (left) and position trajectories (right) when drifting a figure 8 with puddles.
The learned policy achieves 100% success rate in simulation compared to 70% for the baseline, selecting lower steering angles and engine torques to maintain controlled sideslip and avoid spinouts.


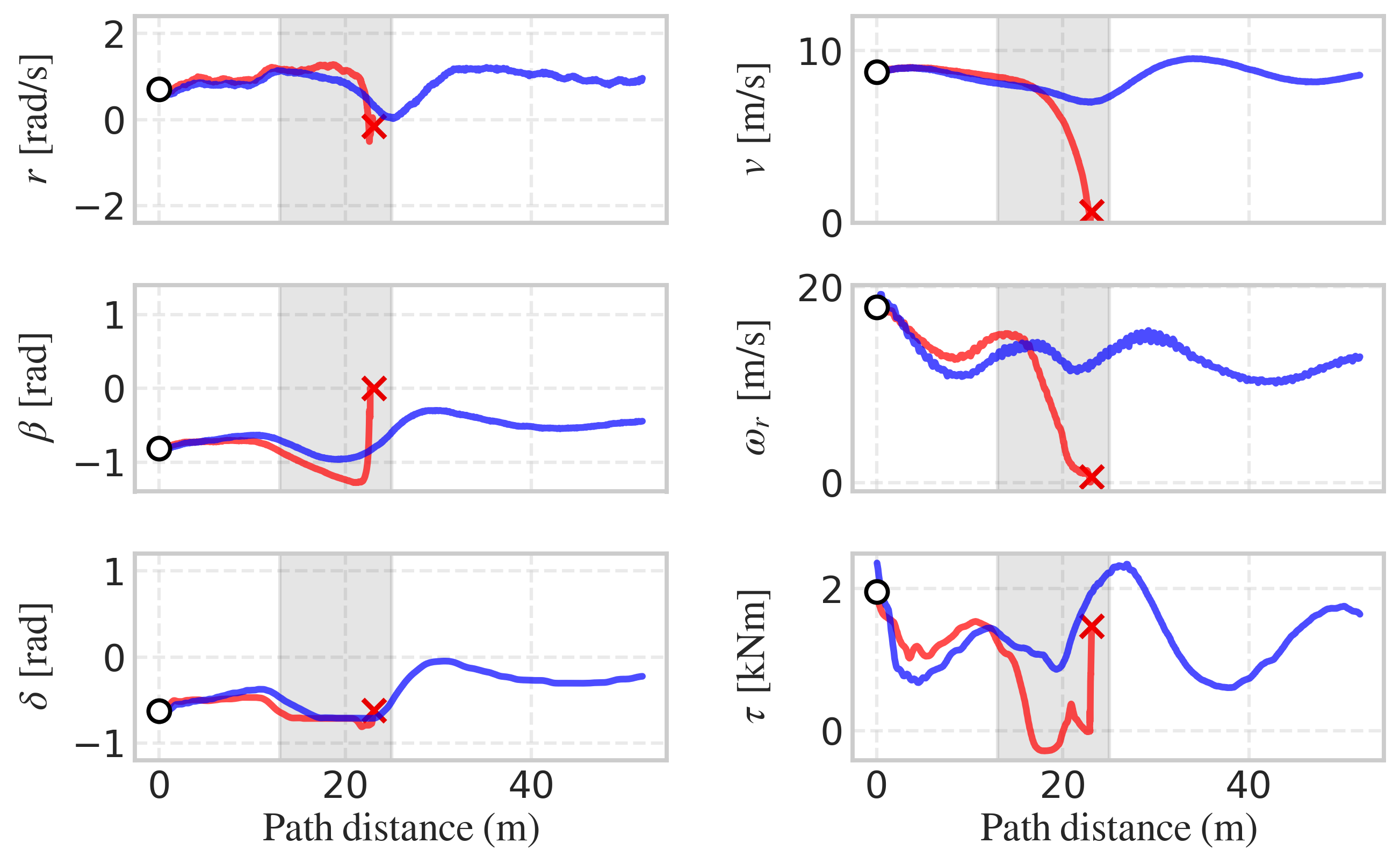
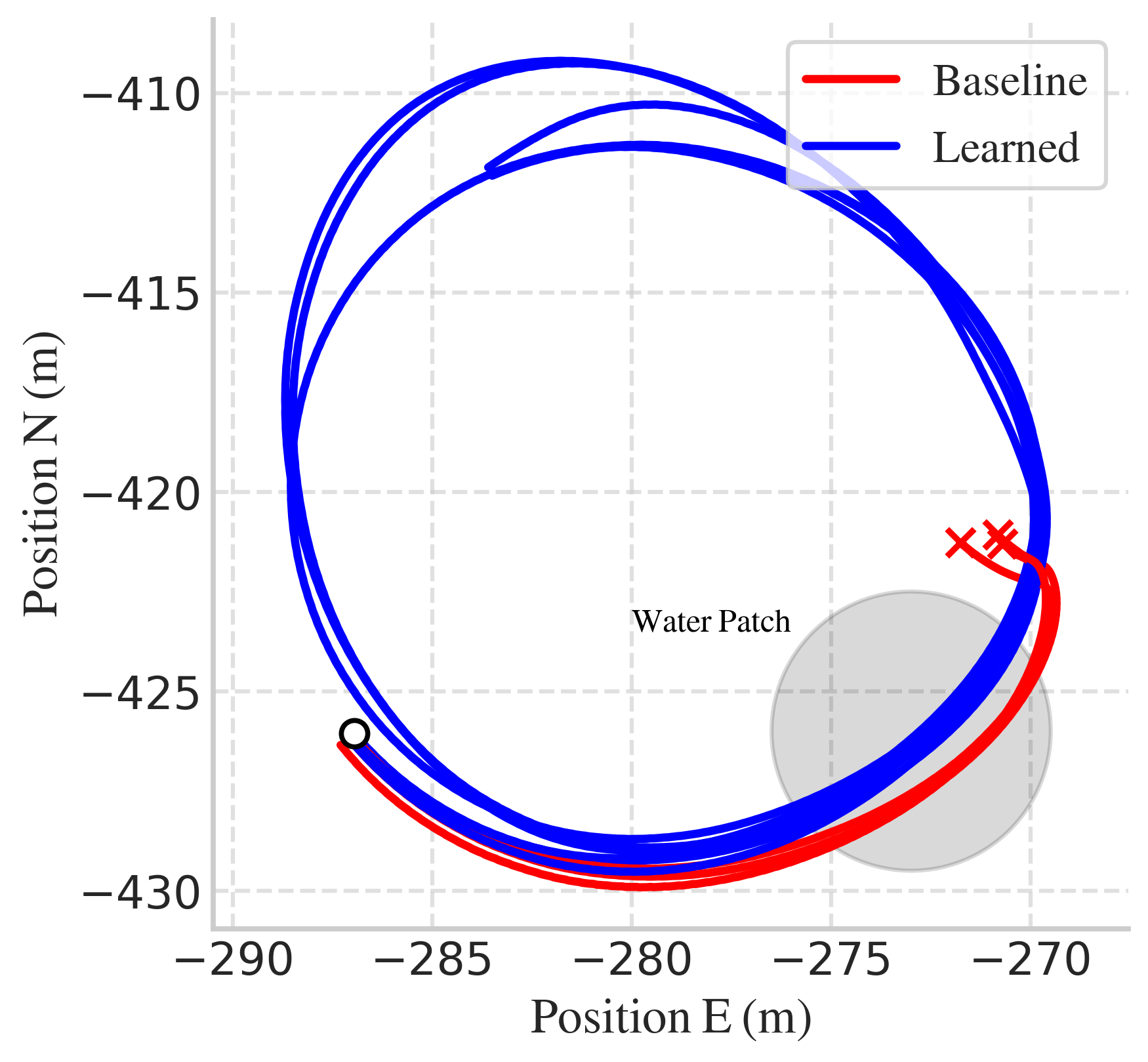
Figure 3: Vehicle drifting through a water puddle: top view (left) and center view (right). The Supra robustly drifts despite variations in friction, which requires carefully selecting actions and sideslip.
On-vehicle experiments confirm transferability: the learned policy generalizes from figure-8 training to donut trajectories without additional tuning, maintaining robustness in the presence of water puddles.
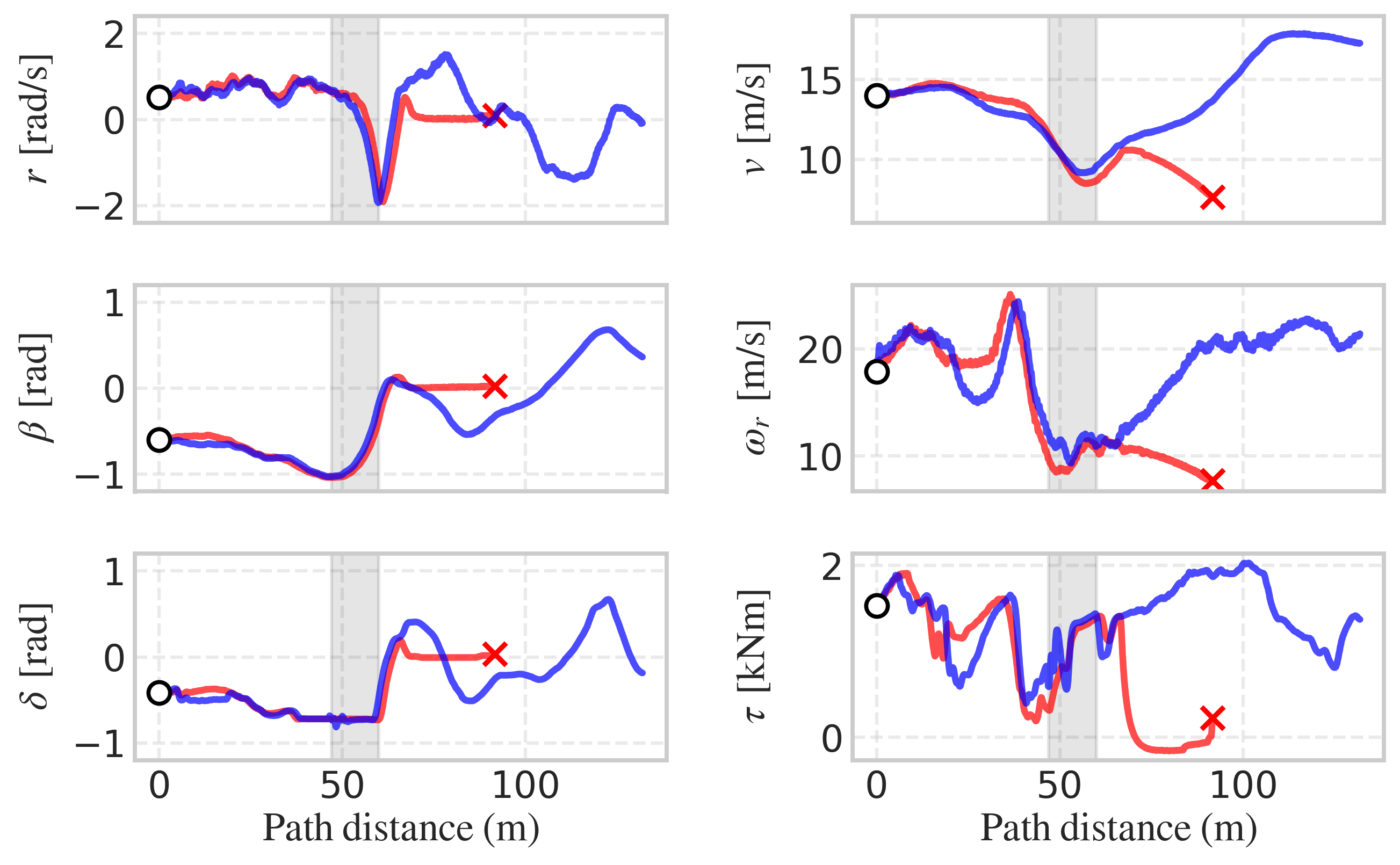
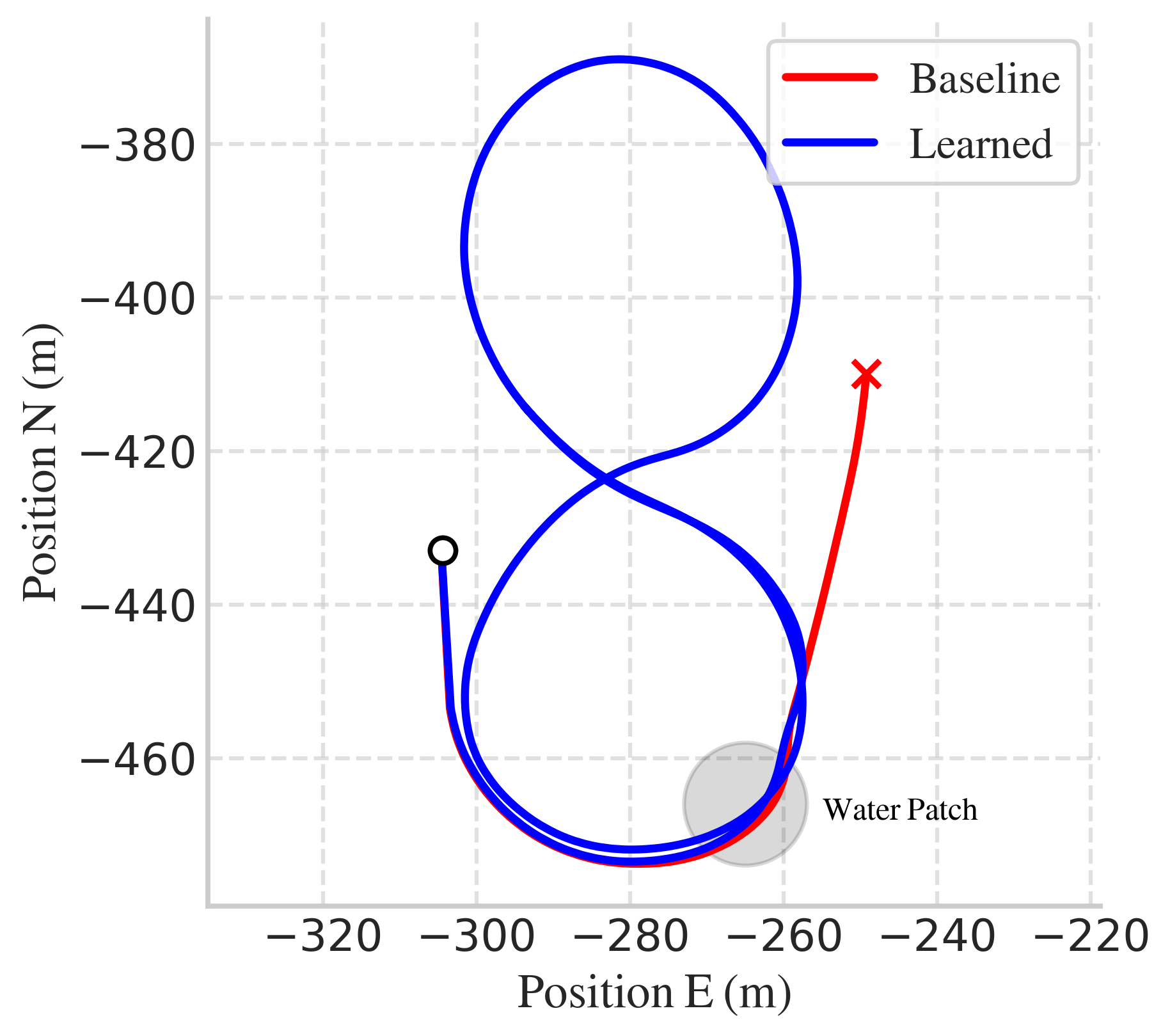
Figure 4: On-vehicle test for drifting a figure 8 trajectory with a water puddle in the first turn. Closed-loop response task with the baseline (red) and the learned controller (blue).
Theoretical and Practical Implications
DiffMPC demonstrates that exploiting time-induced sparsity and parallelism in OCPs enables scalable differentiable optimization on GPUs, supporting large-batch RL and IL. The framework provides strong inductive biases via model-based control, facilitating robust policy learning in safety-critical domains. The use of implicit differentiation and PCG-based linear solves is extensible to other structured optimization problems.
Limitations
- Inequality constraints are not natively supported; handling via augmented Lagrangian or interior-point methods may improve solution quality but introduces challenges in differentiability.
- CPU performance is suboptimal compared to GPU; Riccati-based solvers may be preferable for small-scale or CPU-only deployments.
- Hyperparameter tuning (e.g., PCG tolerance) is not automated.
- Poor initializations can cause solver divergence, motivating future work on robust initialization strategies.
Future Directions
Potential extensions include:
- Incorporation of inequality constraints with differentiable solvers.
- C++/CUDA implementations for further speedups.
- Automated hyperparameter tuning via meta-learning.
- Application to broader classes of structured optimization problems in control and robotics.
Conclusion
DiffMPC provides a scalable, differentiable MPC framework that leverages GPU parallelism and problem structure for efficient learning and control. Empirical results demonstrate substantial speedups and improved robustness in challenging RL and IL tasks, including real-world vehicle drifting under uncertainty. The approach advances the integration of model-based control and data-driven learning, with implications for scalable, robust policy synthesis in complex dynamical systems.