- The paper introduces Diffusion Model Predictive Control (D-MPC) that integrates diffusion-based dynamics modeling with action proposal generation.
- The paper demonstrates enhanced performance on the D4RL benchmark by efficiently adapting to novel reward functions and dynamic environmental changes.
- The paper highlights future research directions focusing on optimizing computational complexity and extending D-MPC to high-dimensional sensory inputs.
Diffusion Model Predictive Control: An Expert Analysis
Introduction
The paper presents a novel approach called Diffusion Model Predictive Control (D-MPC). This method combines diffusion models to create more efficient and flexible MPC systems, achieving impressive performance on the D4RL benchmark. D-MPC can adapt to novel reward functions and dynamic environments, offering a significant advantage over traditional policy-based reinforcement learning methods that are typically constrained by the reward functions they are trained on.
Methodology
D-MPC employs diffusion models to address key challenges in MPC: the accuracy of the dynamics model and the effectiveness of the action planning algorithm. The diffusion-based dynamics model, learned from offline trajectory data, predicts the future states of the system over a defined horizon. Concurrently, an action sequence proposal distribution, also learned through diffusion models, suggests potential action sequences.
Diffusion models are noted for their capabilities in flexible probabilistic modeling, which is crucial for generating realistic multi-step trajectory-level representations. This setup creates the foundation for D-MPC's Sample, Score, and Rank (SSR) method, a simplified variant of the random shooting planning method. The SSR approach leverages the generated action proposals, scores them against the learned dynamics model, and selects the most promising sequence.
D-MPC demonstrates superiority in handling novel reward functions by utilizing the SSR method to optimize those during runtime, an ability most RL methods lack due to their rigid reward function optimization during training. This flexibility is reinforced by D-MPC's robust performance across various tasks within the D4RL benchmark. Notably, the approach manages to outperform prevalent model-based and model-free methods by maintaining dynamic adaptability and leveraging efficient offline learning.
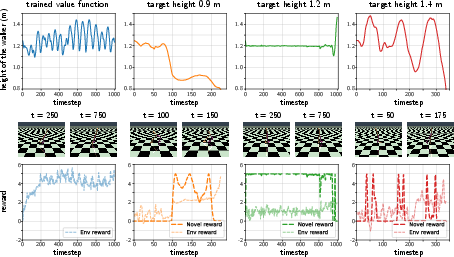
Figure 1: Novel reward functions can generate interesting agent behaviors.
One of the core strengths of D-MPC is its ability to manage dynamics in environments with changing conditions, such as partial system failures or unplanned shifts. By fine-tuning the dynamics model with new data, D-MPC can adapt swiftly without the need for extensive retraining of policies. As shown in (Figure 1), where it demonstrates novel behavior generation based on unrehearsed reward functions, highlighting its real-time adaptability and dynamic response efficiency.
Ablation Studies and Comparisons
A series of ablation studies illustrate that each component of D-MPC—namely the multi-step action proposals, diffusion dynamics models, and the SSR planning method—contributes significantly to overall performance. Multi-step dynamics reduce compounding prediction errors, a common issue in traditional one-step methods, thereby sustaining long-horizon planning accuracy (Figure 2).
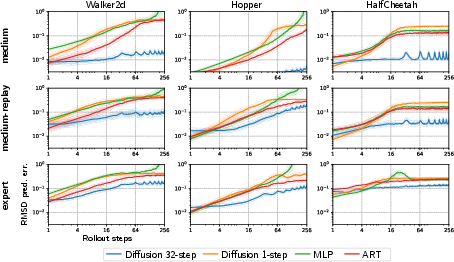
Figure 2: Accuracy of long-horizon dynamics prediction.
Moreover, the integration of diffusion models improves the robustness of action proposals by generating a diverse set of action trajectories. This facilitates more effective planning and decision-making processes compared to single-step deterministic proposals.
Implications and Future Directions
The implications of D-MPC extend beyond typical reinforcement learning scenarios, offering potential applications in robotics where adaptability to novel tasks and environmental changes is essential. The successful implementation of D-MPC in such applications could revolutionize how adaptive control systems are structured.
However, the computational complexity associated with diffusion models—especially in real-time applications—points to the need for optimized sampling techniques. Future research could explore accelerated diffusion model sampling and distillation methods to enhance the real-time applicability of D-MPC.
Additionally, while this paper focused on low-dimensional state information, there is potential for extending D-MPC to handle high-dimensional sensory inputs, such as images. Integrating representation learning techniques with D-MPC could pave the way for its application in more complex and perceptually rich environments.
Conclusion
Diffusion Model Predictive Control is a robust and adaptable approach that addresses several long-standing challenges in model predictive control. Its capability to perform competitively with state-of-the-art methods while offering greater flexibility in reward function adaptation and environment dynamics response highlights its potential as a formidable tool in the field of control systems and reinforcement learning.
In conclusion, D-MPC represents a significant step forward in blending diffusion-based probabilistic modeling with predictive control frameworks, opening new avenues for exploration and application in AI-driven adaptive systems.