Full-Order Sampling-Based MPC for Torque-Level Locomotion Control via Diffusion-Style Annealing
Abstract: Due to high dimensionality and non-convexity, real-time optimal control using full-order dynamics models for legged robots is challenging. Therefore, Nonlinear Model Predictive Control (NMPC) approaches are often limited to reduced-order models. Sampling-based MPC has shown potential in nonconvex even discontinuous problems, but often yields suboptimal solutions with high variance, which limits its applications in high-dimensional locomotion. This work introduces DIAL-MPC (Diffusion-Inspired Annealing for Legged MPC), a sampling-based MPC framework with a novel diffusion-style annealing process. Such an annealing process is supported by the theoretical landscape analysis of Model Predictive Path Integral Control (MPPI) and the connection between MPPI and single-step diffusion. Algorithmically, DIAL-MPC iteratively refines solutions online and achieves both global coverage and local convergence. In quadrupedal torque-level control tasks, DIAL-MPC reduces the tracking error of standard MPPI by $13.4$ times and outperforms reinforcement learning (RL) policies by $50\%$ in challenging climbing tasks without any training. In particular, DIAL-MPC enables precise real-world quadrupedal jumping with payload. To the best of our knowledge, DIAL-MPC is the first training-free method that optimizes over full-order quadruped dynamics in real-time.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a four-legged robot to move skillfully and safely in real time—like walking, jumping, and climbing—by directly controlling the torque (the twist force) at each joint. The authors introduce a new control method called DIAL-MPC that combines a popular planning technique (Model Predictive Control) with ideas from diffusion models (the kind used in AI image generation). The big goal: make real-time robot control fast, reliable, and training-free, even for very complex movements.
What is the paper trying to figure out?
To make this easy to understand, here are the main questions the paper explores:
- How can a robot plan its movements quickly and safely when the problem is very complicated?
- How can we avoid getting stuck in bad local solutions (like choosing a nearby step that’s easy but leads to a dead end)?
- Can a training-free method (no long learning process) be as good as or better than reinforcement learning (RL) for hard tasks like jumping onto small platforms or climbing?
How did they do it? Methods in simple terms
The challenge
Legged robots are hard to control because:
- They have many joints (high-dimensional).
- They touch and leave the ground (contacts), which makes the math non-smooth.
- They’re underactuated (they can’t control everything directly).
Traditional controllers often simplify the robot’s model to make the math easier, but that can hurt performance. The authors want to use the full robot model and still run fast in real time.
Sampling-based control (MPPI) in plain words
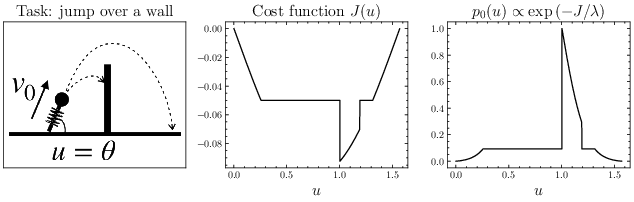
Think of planning a robot’s next few moves as picking a sequence of actions. MPPI (Model Predictive Path Integral) tries lots of slightly different action sequences (samples), simulates what happens for each, and then nudges the current plan toward the better ones.
Analogy: Imagine you’re trying to throw a ball to a target and you try lots of small variations—longer throw, higher arc, slightly left or right—and you keep the adjustments that reduce the miss.
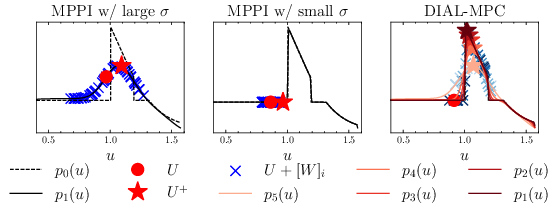
Problem: If the random changes are too big, you explore widely but miss precise good answers. If they’re too small, you might get stuck in a nearby bad choice.
Diffusion-style annealing: starting blurry, getting sharper
Diffusion models (used in image AI) start with a noisy, blurry version and gradually remove noise to make a clear picture. The authors noticed a neat connection: MPPI’s sampling and weighting looks like doing one “denoising” step. So they add a diffusion-style process: start with bigger randomness (to explore) and then reduce it step by step (to refine).
Analogy: Start with a wide flashlight beam to find the general area, then switch to a focused beam to see fine details.
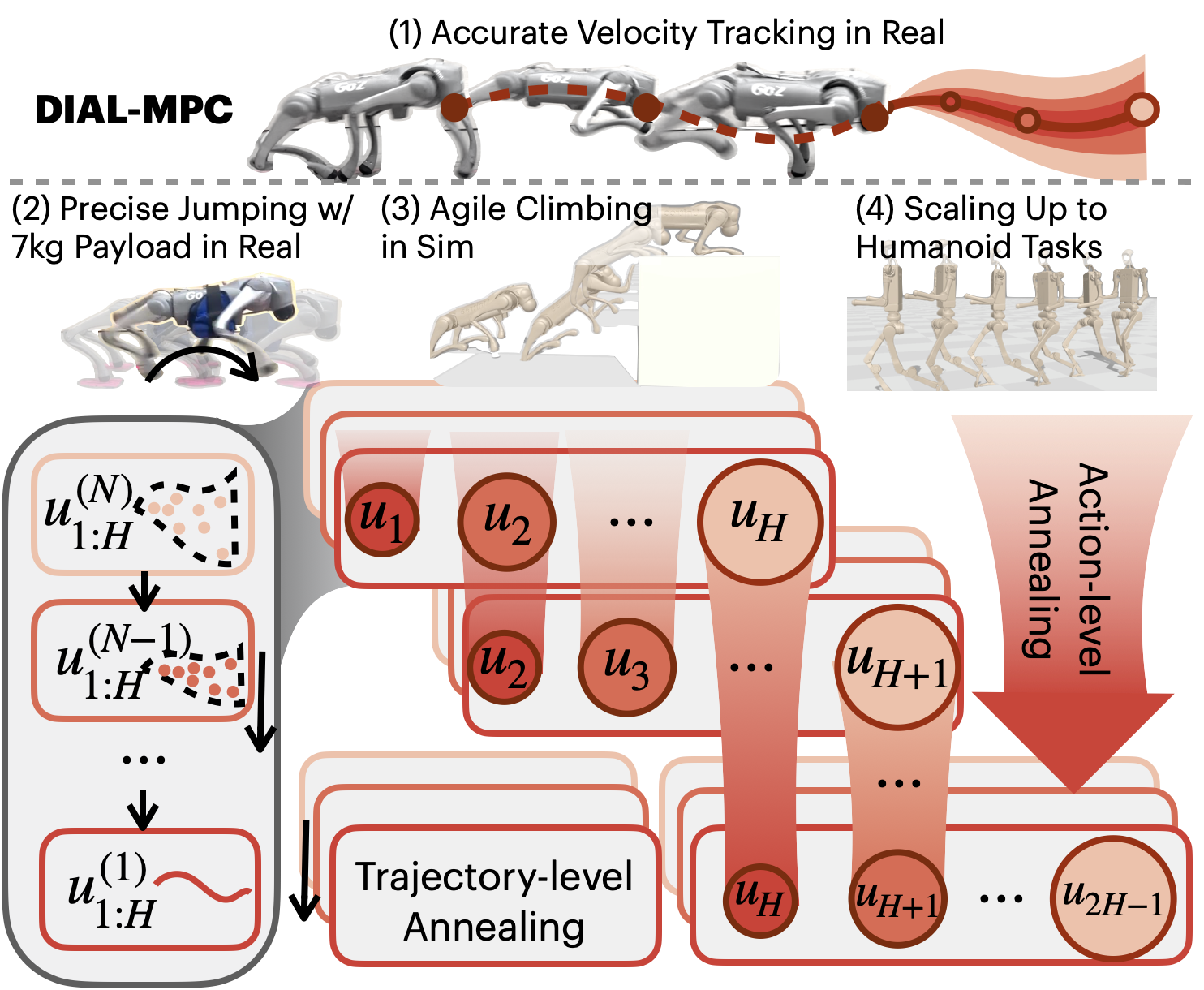
Two-step annealing: across the whole plan and per action
The robot plans over a short future (a horizon), like the next 0.4 seconds split into small steps. DIAL-MPC reduces randomness in two coordinated ways:
- Trajectory-level (outer loop): across repeated updates, it gradually lowers the overall noise for the whole plan. This balances exploration first and precision later.
- Action-level (inner loop): it uses more noise for actions further into the future (because they’ve been refined fewer times) and less noise for actions happening sooner. This makes near-term commands stable and far-term ones flexible.
Together, this “dual-loop” annealing helps cover the global search space and still converge to a good local solution.
Running in real time
They implement this on a GPU using fast physics simulation and control at 50 Hz (50 times per second). The robot uses torque commands directly, which is harder but allows more precise, dynamic motions like jumping.
What did they find?
Across several tough tasks, DIAL-MPC did very well:
- Walking and tracking: DIAL-MPC reduced tracking error by about 13.4x compared to standard MPPI. It also beat a strong RL policy trained for 31 minutes in fast parallel simulation.
- Sequential jumping: The robot had to jump onto small circular platforms, quickly and repeatedly. DIAL-MPC achieved the highest contact score among all methods.
- Crate climbing: The robot climbed onto a crate more than twice its own height. DIAL-MPC succeeded in 90% of trials, while other sampling methods struggled.
- Generalization with payload: With a 10 kg weight added, DIAL-MPC still tracked well and jumped effectively, while the RL policy performed poorly.
- Real-world demos: On a Unitree Go2 robot, DIAL-MPC achieved precise walking and jumping with a 7 kg payload—using direct torque control—without any training.
In short: it ran in real time, required no training, handled full robot dynamics, and outperformed both standard sampling methods and RL in several scenarios.
Why is this important?
- Training-free: No long training process or special data collection. You can deploy it immediately.
- Works with full complexity: It uses the full robot physics model, not a simplified one, which improves accuracy.
- Better balance of exploration and precision: The diffusion-style annealing avoids getting stuck while still finding sharp, high-quality solutions.
- Real-world ready: It works on real robots and handles model changes like added weight.
Implications and potential impact
This approach could change how we control legged robots in real time:
- Faster deployment: Robots can be set up for new tasks without retraining.
- Safer and more reliable planning: Better ability to handle tricky contact-rich moves, like jumping or climbing.
- Bridges AI and control: Using ideas from diffusion models helps solve hard control problems.
- Future directions: The authors suggest speeding up longer plans by combining this method with lightweight learned components (like a small helper policy or a learned model), staying efficient while keeping robustness.
Overall, DIAL-MPC shows a practical, powerful way to control agile legged robots in the real world, combining smart sampling with a “blurry-to-sharp” refinement strategy.
Collections
Sign up for free to add this paper to one or more collections.