- The paper introduces Hardware as Policy (HWasP) that jointly optimizes mechanical design and control by integrating hardware parameters into the reinforcement learning policy.
- It models mechanical components, such as tendon-driven transmissions in robotic hands, as differentiable functions for gradient-based optimization.
- HWasP outperforms traditional methods like CMA-ES by achieving superior learning efficiency and design quality in high-dimensional parameter spaces.
Hardware as Policy: Mechanical and Computational Co-Optimization using Deep Reinforcement Learning
Introduction
In "Hardware as Policy: Mechanical and Computational Co-Optimization using Deep Reinforcement Learning," the authors propose a novel framework that unifies the optimization of both hardware and computational control policies for robotic systems within a single reinforcement learning (RL) architecture. The paper introduces the concept of modeling robot hardware as an integral part of the policy, termed a "hardware policy", facilitating joint optimization of mechanical and computational elements. This approach leverages the power of Deep Reinforcement Learning (Deep RL) to efficiently solve complex co-design problems, traditionally handled by separate optimization processes.
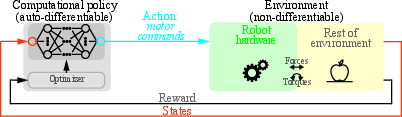

Figure 1: Traditional perspective --- Reinforcement Learning with a purely computational policy.
Methodology
The core innovation of the paper is the transformation of hardware parameters into differentiable components of the RL policy. By incorporating the mechanical model of the robot into a computational graph, the framework enables gradient-based optimization of hardware parameters alongside the computational control strategy. This integration is achieved by modeling the mechanical properties—such as tendon-driven transmissions in robotic hands—as differentiable functions within the learning algorithm.
The proposed Hardware as Policy (HWasP) method builds upon traditional Policy Optimization techniques, such as Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). It diverges from classical approaches by considering the hardware as part of the agent, allowing the environment to be modeled more abstractly, focusing only on the remaining non-hardware interactions.
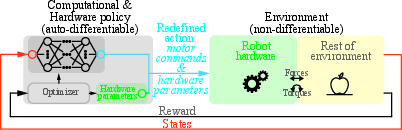
Figure 2: Hardware as Policy-Minimal.
Case Studies
Mass-spring Toy Problem
The paper first demonstrates HWasP using a mass-spring toy problem. In this one-dimensional setup, two masses connected by springs are controlled by a motor subject to optimization. HWasP is enacted by modeling spring stiffness as part of the action space, allowing reinforcement learning to optimize both the spring constants and the motor control policy concurrently.

Figure 3: Problem descriptions, left: HWasP, right: HWasP-Minimal.
Underactuated Hand Design
In a more complex scenario, the method is applied to designing an underactuated robotic hand. Here, the hand, driven by a single motor through tendon mechanisms, is optimized for versatile grasping tasks. The hardware parameters, including pulley radii and tendon elasticities, are adjusted alongside the computational policy that guides the hand movement. The paper showcases simulations that highlight the effectiveness of HWasP in achieving high-quality hand designs that are validated through sim-to-real transfer techniques.

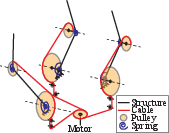

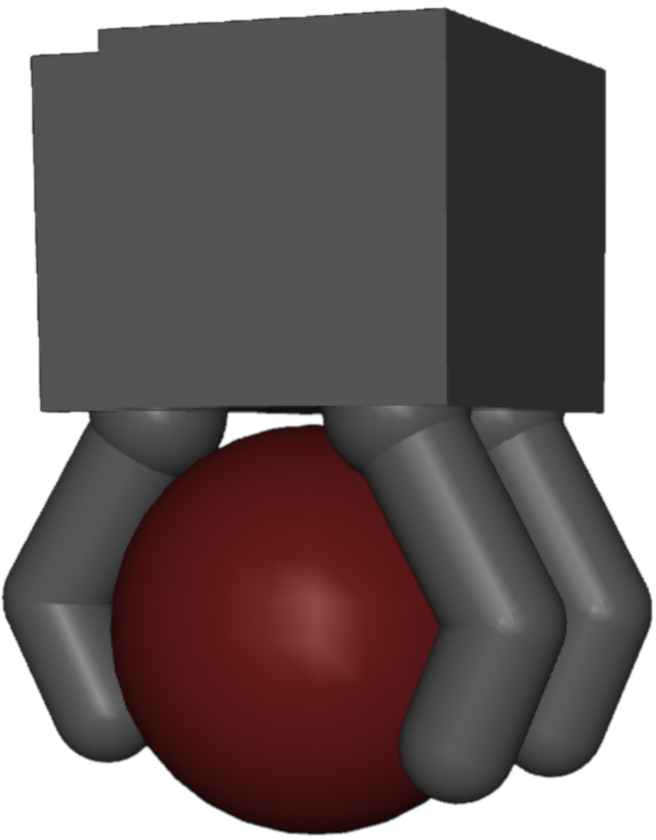

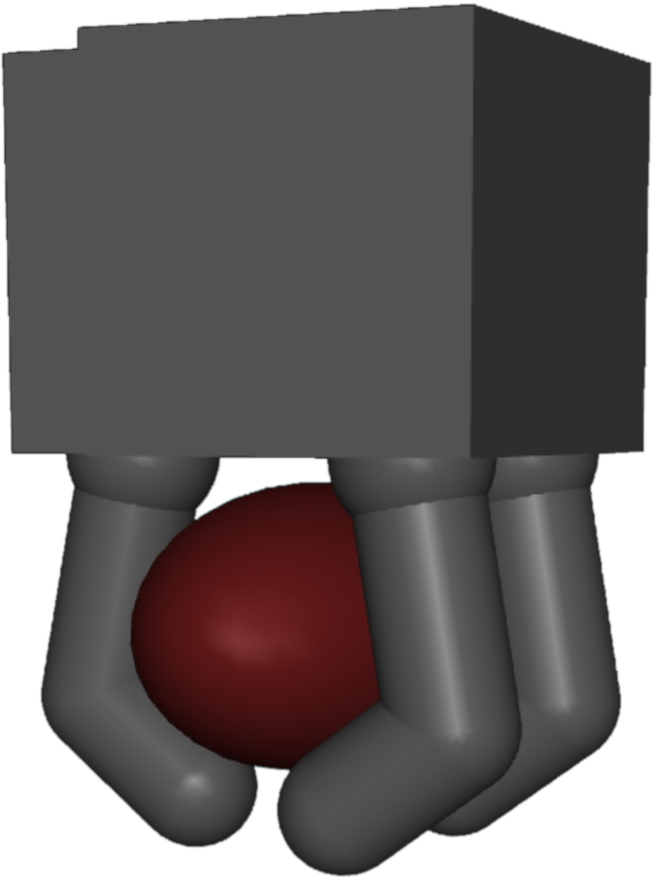




Figure 4: Hand design optimization problem. Left: hand kinematics, dimension, and tendon routing. Right: successful grasps executed in simulation and on a real hand prototype.
Comparative Analysis
The effectiveness of HWasP and its minimal version, HWasP-Minimal, is contrasted with traditional co-design approaches using evolutionary strategies like CMA-ES. The results indicate that HWasP exhibits superior learning efficiency and solution quality, especially in high-dimensional parameter spaces, due to its ability to use gradient-based methods.
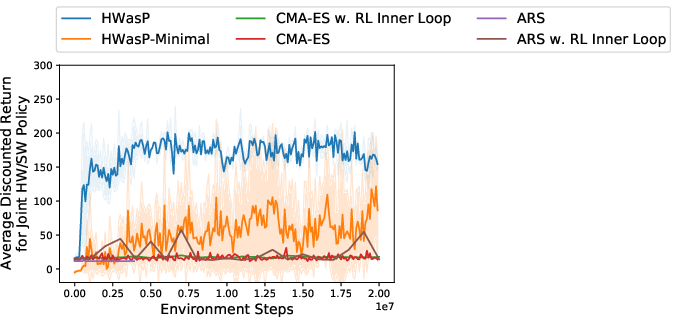
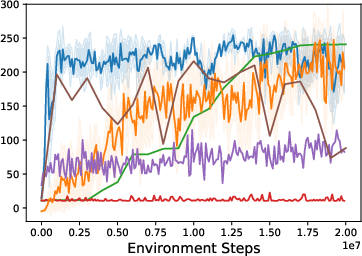
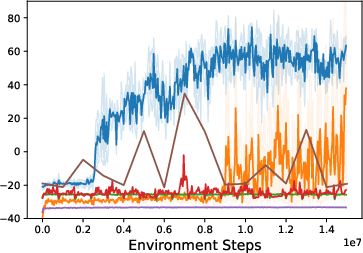
Figure 5: Training curves for the grasping problem. Left: Z-Grasp with a large hardware parameter search range. Middle: Z-Grasp with a small hardware search range. Right: 3D-Grasp with a small search range.
Conclusion
The paper presents a robust framework for simultaneous mechanical and computational optimization in robotic systems, offering significant improvements over traditional methods by using RL. The HWasP approach creatively integrates mechanical components into the policy structure, promising more effective and efficient co-design processes. The success in both toy and real-world problem setups suggests potential for broader applications in robotics, where complex interactions between hardware and control systems are frequent. Future work may expand on this framework to include broader aspects of hardware design and explore real-time adaptation in dynamic environments.