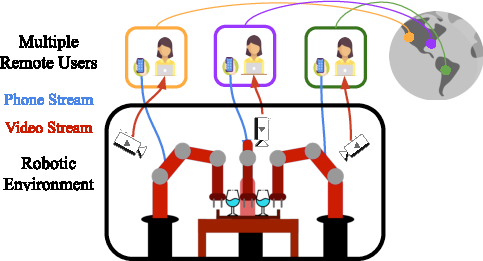
- The paper introduces MART, a platform enabling multiple remote users to collaboratively teleoperate robotic arms for complex manipulation tasks.
- It evaluates various policy architectures and demonstrates that combining centralized and decentralized strategies enhances coordination and robustness.
- The base-residual policy framework, showcased in r-HBC and rd-HBC variants, outperforms traditional methods on five challenging multi-arm manipulation tasks.
Learning Multi-Arm Manipulation Through Collaborative Teleoperation
This paper introduces Multi-Arm RoboTurk (MART), a multi-user data collection platform designed to facilitate imitation learning (IL) for multi-arm manipulation tasks. The core innovation lies in enabling multiple remote users to simultaneously teleoperate a set of robotic arms, thereby overcoming the cognitive burden associated with single-operator multi-arm control. The authors demonstrate the effectiveness of MART by collecting demonstrations for five novel two-arm and three-arm tasks, and subsequently analyze various policy architectures with different levels of centralization to address the challenges posed by mixed coordination requirements in multi-arm manipulation. The paper concludes by proposing a base-residual policy framework that combines centralized and decentralized control strategies, achieving superior performance compared to purely centralized or decentralized approaches.
System Design and Implementation
The MART system builds upon the existing RoboTurk platform, extending its capabilities to support collaborative teleoperation. Key features of the system include:
Addressing Mixed Coordination Challenges
The paper identifies a critical challenge in multi-arm manipulation: many tasks do not require continuous global coordination but rather exhibit phases of independent operation interspersed with periods of tight synchronization (Figure 2).

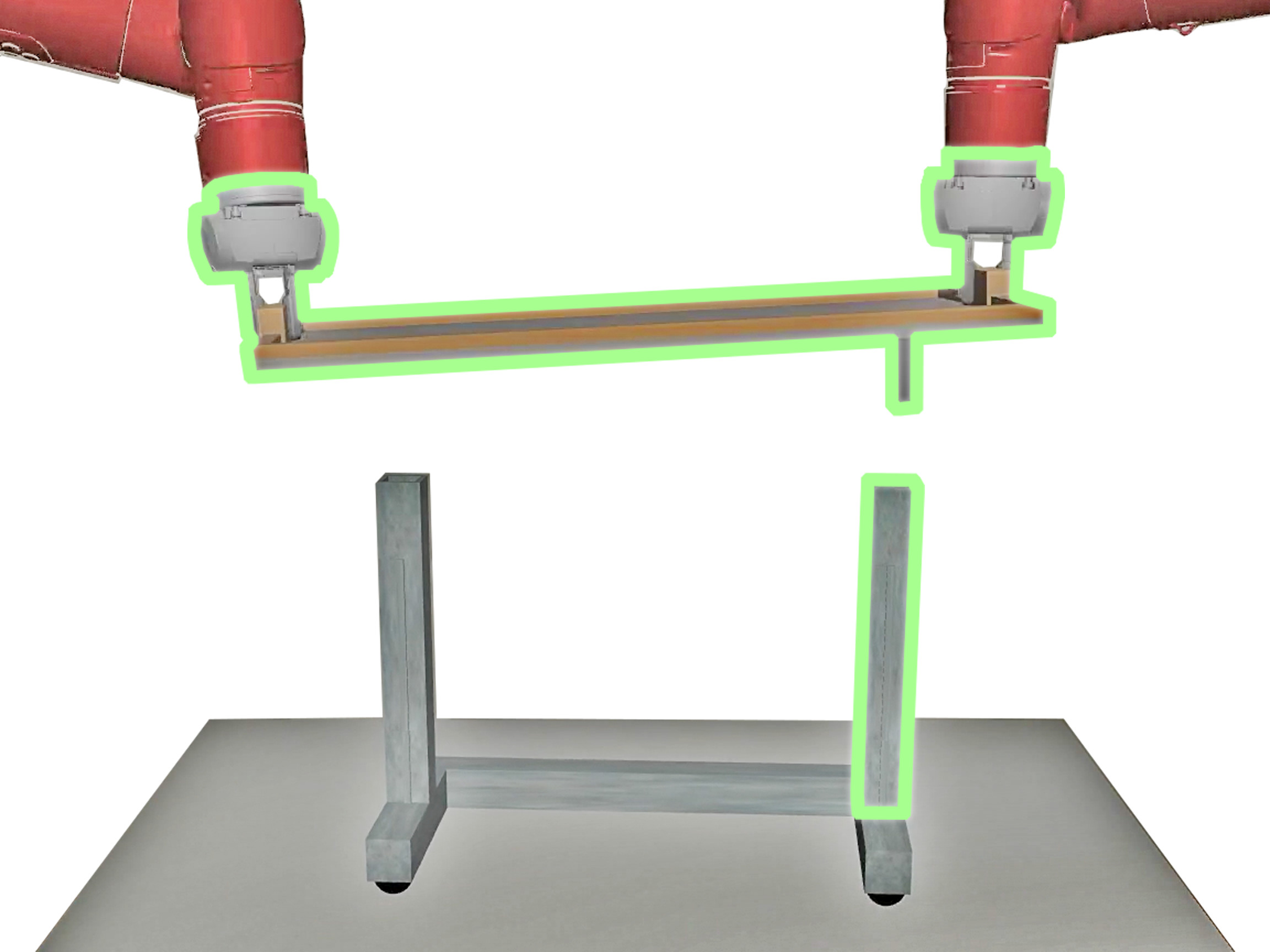
Figure 2: Multi-Stage Multi-Arm Manipulation with Mixed Coordination, exemplified by table assembly where independent column assembly precedes coordinated tabletop alignment.
To address this, the authors conduct a comprehensive study of different policy architectures, including:
- Centralized Agents: Utilize the entire state space to generate actions for all robots, enabling explicit coordination but potentially overfitting to spurious correlations.
- Decentralized Agents: Generate robot-specific actions based solely on local observations, avoiding overfitting but struggling with tasks requiring synchronization.
- Hierarchical Behavioral Cloning (HBC): Employs a high-level policy to predict subgoals and a low-level policy to execute actions, providing temporal abstraction and improved learning from offline demonstrations.
The study reveals that centralized agents perform poorly compared to distributed variants due to "hallucinating" incorrect correlations, while distributed agents struggle with synchronization.
Base-Residual Policy Framework
To overcome the limitations of purely centralized or decentralized approaches, the paper introduces a base-residual policy framework. This framework combines a base policy, which can be either centralized or decentralized, with a residual policy that learns to perturb the actions of the base policy. The guiding principle is that the base policy dictates the dominant behavior (coordinated or decoupled), while the residual policy encourages complementary traits.
The framework includes two variants:
- r-HBC: A decentralized HBC base policy is augmented with a centralized residual network, improving coordination in tasks requiring synchronization.
- rd-HBC: A centralized HBC base policy is augmented with a decentralized residual network, mitigating overfitting and encouraging generalization.
The residual network outputs a small correction to the action:
a=aˉ+δ,δ=ρ(aˉ,s),∣∣δ∣∣2<ϵ
where aˉ is the action from the pretrained policy, δ is the correction from the residual network ρ, and ϵ is a small constant to prevent the residual network from dominating the overall policy behavior.
Experimental Evaluation
The effectiveness of the proposed framework is demonstrated through experiments on five novel multi-arm manipulation tasks in simulation: Multi-Cube Lifting, Drink Tray Lifting, Table Assembly, Pick-Place Handover, and Lifting Wiping (Figure 3).





Figure 3: Multi-Cube Lifting task showing two robot arms independently lifting blocks.
The tasks are designed to showcase real-world scenarios requiring varying levels of coordination between agents. The results show that the base-residual policy framework consistently outperforms purely centralized or decentralized baselines across all tasks, highlighting its ability to adapt to mixed coordination settings. Specifically, r-HBC excels in complex, multi-stage tasks, while rd-HBC performs best in shorter-horizon tasks. The framework also demonstrates robustness to varying demonstration quality, maintaining performance improvements even with noisy training data.
Conclusion
The paper presents a valuable contribution to the field of multi-arm manipulation by introducing a scalable data collection system and a novel policy framework that effectively addresses the challenges of mixed coordination. The MART system lowers the barrier to entry for exploring multi-arm tasks, while the base-residual policy framework offers a promising approach for learning complex manipulation skills from demonstration data. This work opens avenues for future research in areas such as improving performance on challenging tasks like assembly and exploring novel emergent properties underlying multi-arm manipulation.