Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation
Abstract: Robotic loco-manipulation tasks often involve contact-rich interactions with the environment, requiring the joint modeling of contact force and robot position. However, recent visuomotor policies often focus solely on learning position or force control, overlooking their co-learning. In this work, we propose the first unified policy for legged robots that jointly models force and position control learned without reliance on force sensors. By simulating diverse combinations of position and force commands alongside external disturbance forces, we use reinforcement learning to learn a policy that estimates forces from historical robot states and compensates for them through position and velocity adjustments. This policy enables a wide range of manipulation behaviors under varying force and position inputs, including position tracking, force application, force tracking, and compliant interactions. Furthermore, we demonstrate that the learned policy enhances trajectory-based imitation learning pipelines by incorporating essential contact information through its force estimation module, achieving approximately 39.5% higher success rates across four challenging contact-rich manipulation tasks compared to position-control policies. Extensive experiments on both a quadrupedal manipulator and a humanoid robot validate the versatility and robustness of the proposed policy across diverse scenarios.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching legged robots (like four-legged “dog” robots and humanoids) to both move and handle objects safely and smartly at the same time. The key idea is a single “brain” (a control policy) that can control where the robot moves its body or hand and how hard it pushes, without needing special force sensors. This lets the robot do tricky, contact-heavy tasks like wiping a board, opening cabinets, and pulling drawers.
What questions did the researchers ask?
The researchers focused on simple but important questions:
- Can one policy control both position (where to move) and force (how hard to push) for a legged robot?
- Can a robot learn to “feel” contact forces using only its own motion and joint histories, instead of physical force sensors?
- Will this help robots perform contact-heavy tasks more reliably in the real world?
- Can this “force-aware” control also make demonstration data better for imitation learning (teaching robots by example)?
How did they do it?
To make this easy to imagine, think of the robot like a person using their hand to press a sponge on a wall while walking. You need to decide where to move the hand (position) and how hard to press (force), and you must stay soft and safe if something pushes back (compliance).
Here’s their approach, explained in everyday terms:
- The robot’s “brain” is a policy, which is just a set of rules that turn what the robot senses into actions (how to move its joints).
- Instead of giving the robot a real sense of touch, they taught it to guess the push/pull forces by looking at its recent movement and how it responds to contact. This guessing module is called a force estimator.
- They trained the policy in a fast simulator using reinforcement learning (like practicing a video game with trial-and-error):
- The robot is given different position goals (where to move its “hand”) and force goals (how hard to push).
- The environment sometimes “pushes back” with random disturbances, like someone nudging the robot or the tool getting stuck.
- The robot gets rewarded for following the position and force goals while staying stable and safe.
- The control idea mimics a spring and shock absorber:
- Spring: if the robot’s hand is pushed off target, it gently pushes back toward the target.
- Shock absorber (damping): it smooths out the motion so it’s not jerky.
- This style is known as impedance control, and it makes the robot naturally compliant (safe and cushioned) in contact.
- A single unified policy learns to:
- Track positions accurately when needed.
- Apply specific forces when needed.
- Blend both at the same time (hybrid control).
- Stay soft and safe when the environment changes or pushes back.
They trained and tested on two real robots:
- A quadruped with an arm (Unitree B2-Z1).
- A humanoid robot (Unitree G1).
They also used the learned policy to collect better training examples for imitation learning. During human teleoperation, the policy provides estimated contact forces along with images and robot states. This creates “force-aware” demonstrations that include both what to do and how hard to push.
What did they find?
Here are the main results and why they matter:
- One policy can handle many behaviors:
- Position tracking: move the robot’s “hand” where it should be.
- Force control: press with a certain force.
- Force tracking: keep contact light or zero when needed.
- Impedance/compliance: be springy and safe when interacting with people or objects.
- Base compliance: adjust the robot’s walking speed or posture if something pushes its body.
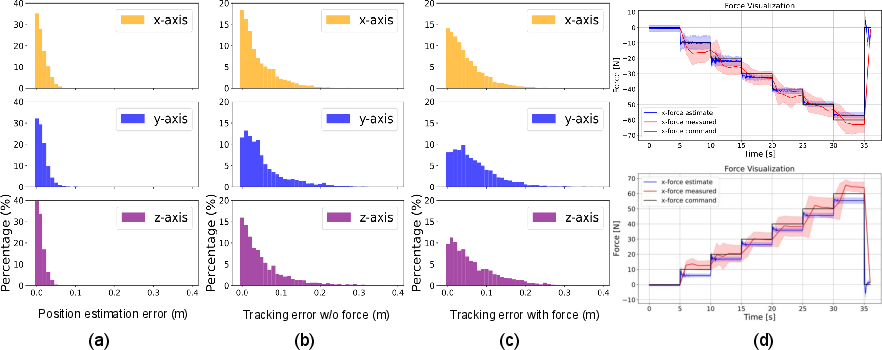
- Accuracy in tests:
- Position tracking errors stayed mostly within about 0.1 meters in simulation.
- Direct force control on real robots reached average errors within about 5–10 Newtons across tested positions, which is often good enough for everyday manipulation.
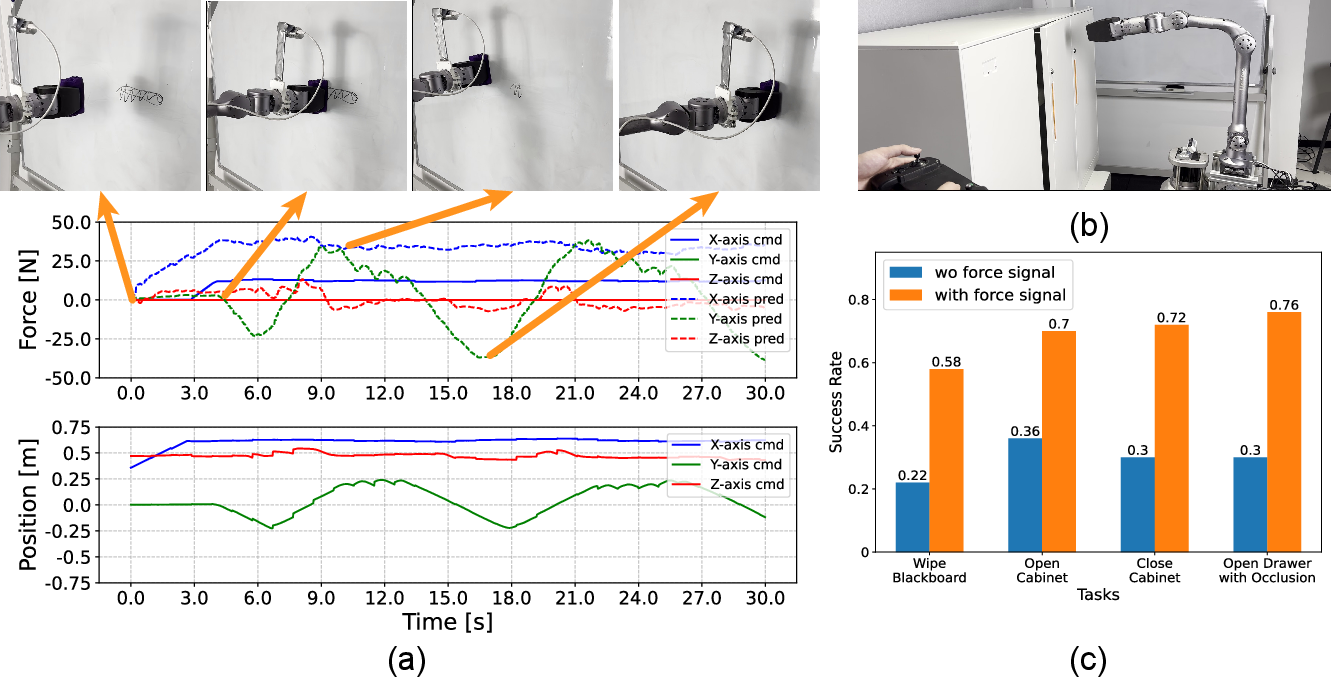
- Better imitation learning:
- Adding the estimated contact force to demonstration data boosted success rates by about 39.5% across four real tasks:
- Wiping a blackboard (needs steady contact while moving).
- Opening and closing a push-to-open cabinet (needs just the right push).
- Opening a drawer even when the camera view is blocked (force tells the robot it made contact even when it can’t see).
- This shows that feeling-like information (even estimated) is crucial when vision alone is not enough.
- Works on different robots:
- The same idea helped both a quadruped manipulator and a humanoid handle pushes and stay balanced or compliant.
Why does this matter?
- Safer, smarter contact: Robots often need to push, pull, or press without breaking things or hurting themselves. A unified position-and-force controller makes that easier and more reliable.
- No force sensors needed: Force sensors can be expensive or hard to mount. Estimating force from motion makes the system more practical and widely usable.
- Better training data: Many robot datasets only record positions and images, missing the “feel” of contact. Adding estimated force makes training examples much more informative, especially for tasks where touch matters more than sight.
- Generality: A single, learned policy that covers many behaviors reduces complexity and can transfer across different legged robots.
Limitations and future directions
- Edge cases: Force estimation is less accurate during very fast interactions or at the edges of the robot’s reach.
- Sim-to-real differences: Real hardware doesn’t perfectly match simulation, which can affect accuracy, especially along certain directions.
- Single-point focus: The work mainly estimates force at one contact point. Future work could handle multiple contact points across the whole body (for example, bracing with the body while manipulating with the arm).
Bottom line
This paper shows a practical way to give legged robots a sense of “how hard to push” and “where to move” at the same time—using one learned policy and no force sensors. It improves real-world performance in contact-heavy tasks and produces better data for teaching robots by example, moving us closer to robots that can safely and usefully work with people in everyday environments.
Collections
Sign up for free to add this paper to one or more collections.