- The paper introduces a metric framework using α-Precision, β-Recall, and Authenticity to evaluate individual sample quality, capturing fidelity, diversity, and generalization.
- It proposes a novel approach by leveraging minimum volume sets and binary classification to measure typicality and detect overfitting.
- The methodology demonstrates broad applicability, including in sensitive areas like clinical data synthesis, to support thorough model auditing and refinement.
Evaluation Metrics for Generative Models
The paper "How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models" (2102.08921) introduces a comprehensive framework for assessing generative models. It proposes a novel evaluation metric composed of three key components: α-Precision, β-Recall, and Authenticity. This paper addresses the limitations of existing generative model evaluation metrics by introducing a method that can evaluate any generative model across various domains in a model-agnostic manner.
Motivations and Objectives
Traditional evaluation metrics for generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), often rely heavily on likelihood functions or specific pre-trained embeddings. These metrics, although useful, often fail to adequately capture the nuances and modes of failure in generative models across different domains, as they are optimized for image synthesis tasks. The authors aim to provide a holistic evaluation metric that reflects the fidelity, diversity, and generalization capabilities of generative models in a domain-agnostic manner.
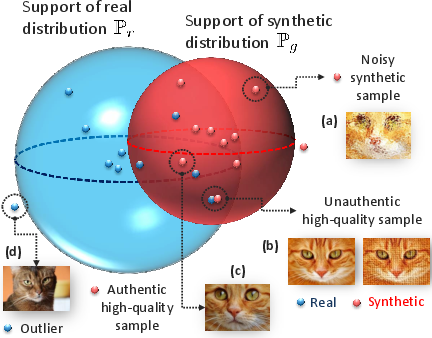
Figure 1: Pictorial depiction for the proposed metrics. The blue and red spheres correspond to the α- and β-supports of real and generative distributions, respectively.
The crux of the proposed methodology is a shift from global distribution-based measures to a focus on the quality of individual samples. This is achieved through the introduction of metrics that can be estimated via binary classification, paving the way for nuanced evaluations of fidelity and diversity, as well as the introduction of generalization to diagnose overfitting through data copying.
Methodological Framework
The proposed framework introduces a three-dimensional metric that represents the performance of generative models as a point in a three-dimensional space. This space is defined by:
- Fidelity (α-Precision): Measures the probability that synthetic samples resemble the most typical samples within the real distribution.
- Diversity (β-Recall): Quantifies the extent to which the synthetic samples cover the real data distribution.
- Generalization (Authenticity): Assesses the likelihood that synthetic samples are not merely memorized copies of training data.
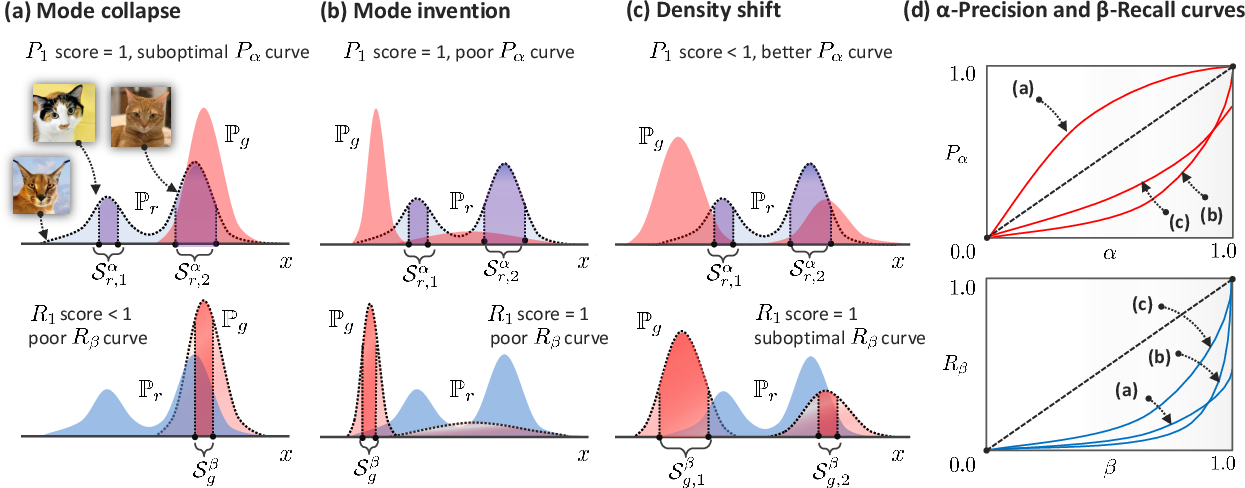
Figure 2: Interpretation of the Pα and Rβ curves.
The authors utilize minimum volume sets to define α- and β-supports, which are crucial to calculating these metrics. α-Precision and β-Recall represent probability mass concentrations in the real and synthetic data distributions, systematically ignoring outliers to evaluate typicality and coverage more accurately.
Evaluation and Applications
The proposed metrics were empirically validated through experiments with different generative models, including those aimed at synthesizing sensitive clinical data. Evaluations demonstrated that these metrics provide richer insights into generative model performance compared to traditional methods (e.g., Fréchet Inception Distance), which often inadequately report fidelity and diversity.
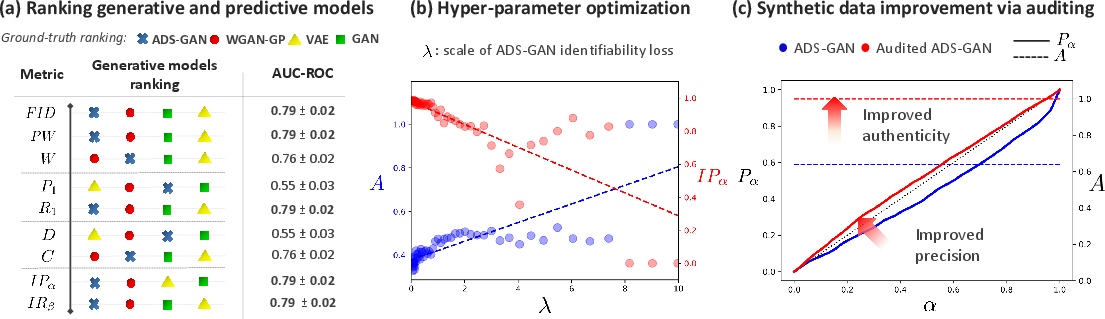
Figure 3: Predictive modeling with synthetic data.
The framework's applicability extends beyond mere evaluation; it facilitates post-hoc auditing to enhance model outputs. In model auditing, each synthetic sample's quality is individually assessed, allowing for post-generation refinement without altering the model architecture. This capability is particularly beneficial for sensitive applications where data authenticity and privacy are paramount, such as in healthcare data synthesis for COVID-19.
Limitations and Future Directions
While the paper successfully establishes a versatile metric framework, certain challenges remain unaddressed, including computational cost and reliance on the robustness of pre-trained embeddings for certain data modalities. Future research could address these challenges by exploring more efficient computation methods and developing embeddings that maintain stability across diverse application domains.
In conclusion, this paper introduces a pioneering framework for generative model evaluation, combining precision-recall analysis with statistical divergence measures while adding a third dimension of generalization. This approach notably enhances the capacity to evaluate generative models in a sample-sensitive and domain-agnostic manner.