- The paper introduces novel probabilistic metrics called P-precision and P-recall to address kNN limitations in evaluating generative models.
- It employs a probabilistic framework that normalizes density estimates, mitigates outlier effects, and separates fidelity from diversity.
- Experiments on models like StyleGAN and BigGAN demonstrate the superior stability and sensitivity of the proposed metrics compared to traditional methods.
Probabilistic Precision and Recall Towards Reliable Evaluation of Generative Models
Introduction
The paper introduces novel metrics, Probabilistic Precision (P-precision) and Probabilistic Recall (P-recall), for evaluating generative models by addressing limitations of k-Nearest Neighbor (kNN)-based metrics like Improved Precision and Recall (IPR) and Density and Coverage (DC). Traditional methods exhibit vulnerabilities to outliers and are insensitive to distribution changes due to oversimplified assumptions inherent in kNN. The proposed metrics provide a more robust mechanism by employing probabilistic approaches that address the shortcomings of constant-density assumptions and hypersphere overestimation.
Background
Existing evaluation metrics like Fréchet Inception Distance (FID) offer a broad comparison of generative models, but they fail to distinguish between fidelity and diversity. Thus, two-value metrics like IPR and DC were introduced. However, both approaches face challenges. IPR relies on constant-density assumptions within hyperspheres and its reliance on kNN results in unreliable support estimations, particularly in the presence of outliers. DC attempts to refine these evaluations by considering hypersphere overlap but remains susceptible to outliers, demonstrates large variability, and displays insensitivity to distribution shifts (Figure 1).
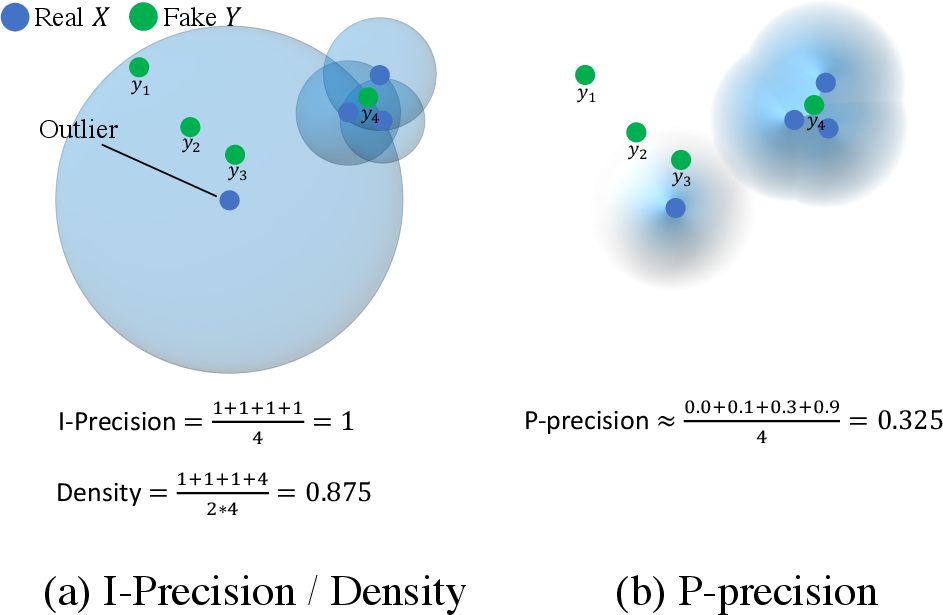
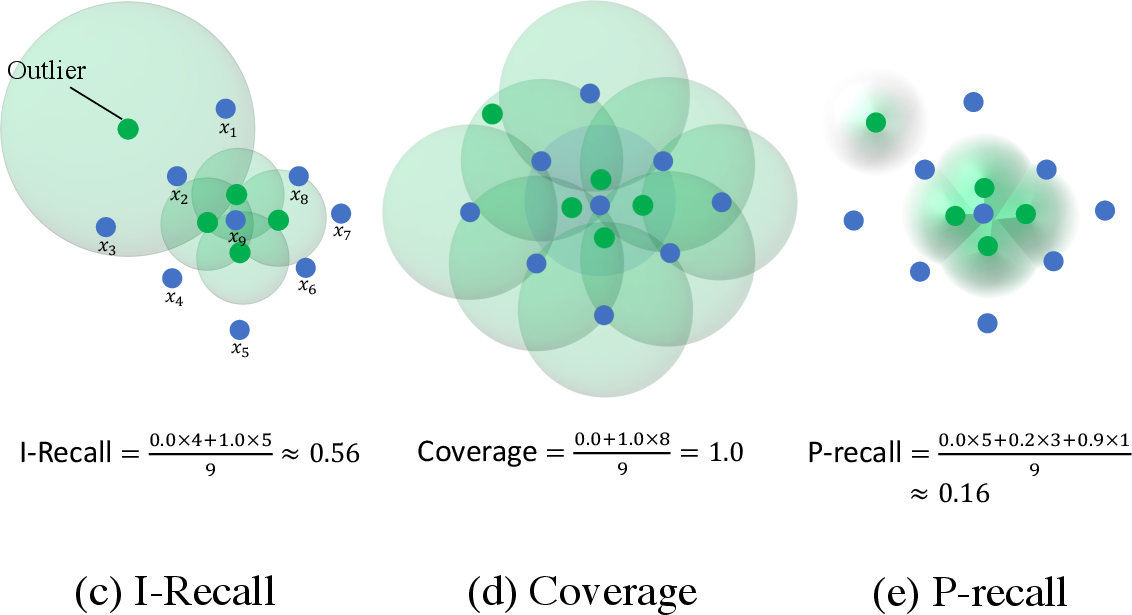
Figure 1: Examples of IP{additional_guidance}IR, D{additional_guidance}C, and PP{additional_guidance}PR with varying y showcasing overestimation by kNN and differences in P-precision and P-recall.
Proposed Methodology
The proposed P-precision and P-recall metrics use a probabilistic framework to address these issues. Unlike deterministic kNN metrics, this probabilistic approach considers the uncertainty in support estimation. The probability Pr(yj∈SP) for a sample yj belonging to the support SP is defined by assessing its proximity to various subsupports around each observation xi. This method, termed Probabilistic Scoring Rules (PSR), effectively normalizes the density and mitigates outlier impact.
The metrics are calculated by averaging over these probabilities, creating a robust measure that separates fidelity and diversity without being overly sensitive to k choice or hypersphere overestimation.
Experimental Evaluation
Experiments on toy datasets and generative models like StyleGAN and BigGAN demonstrate the superiority of PP{additional_guidance}PR over existing metrics. In scenarios with outliers, P-precision and P-recall remain stable, whereas IPR and DC metrics show significant biases due to outlier influence. Furthermore, when evaluating models with varying fidelity and diversity trade-offs, the proposed metrics accurately reflect these changes, unlike the less sensitive DC metrics (Figures 2-6).
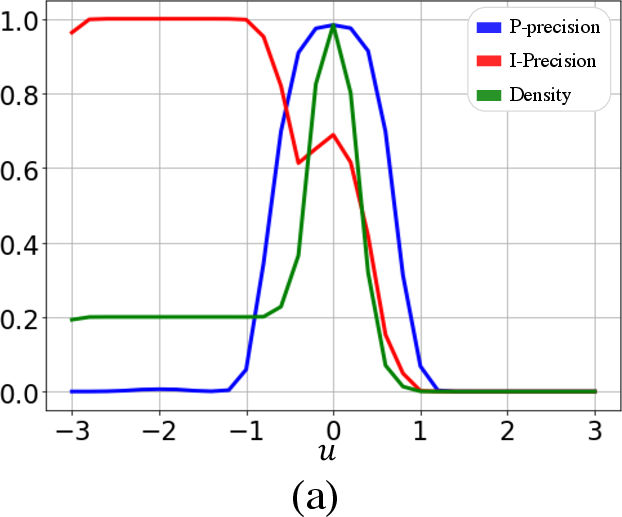
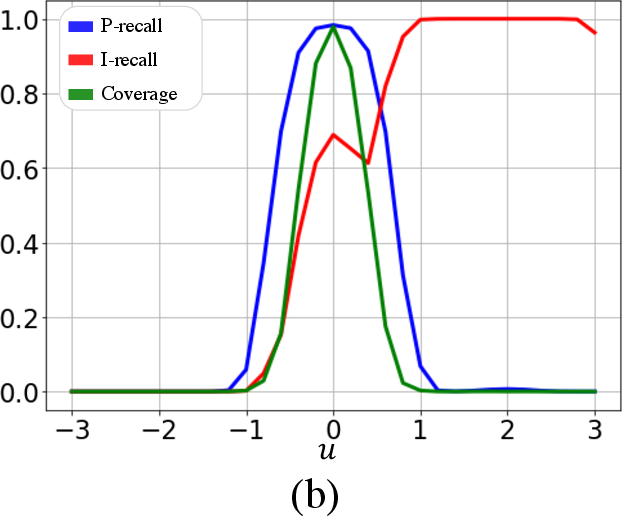
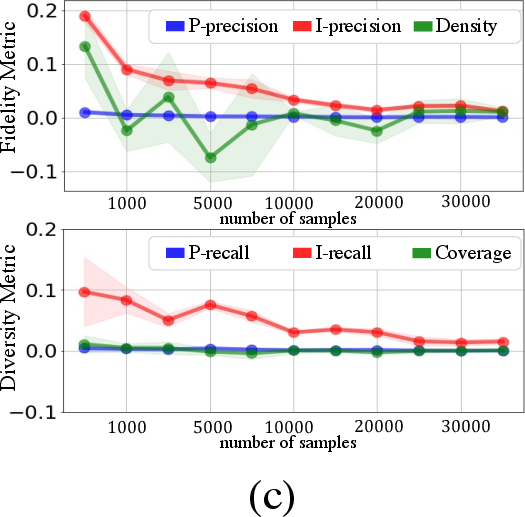
Figure 2: Fidelity and diversity metric behavior with Gaussian variable u, highlighting P-precision reliability.
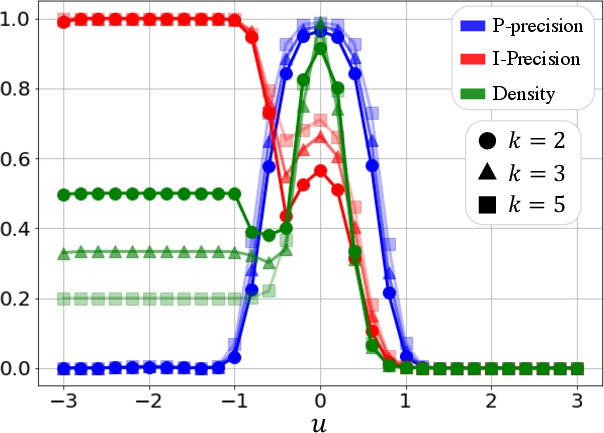
Figure 3: Ablation over k, showing metric consistency across different k values.


Figure 4: Metric behavior in response to gradient scale variations in classifier guidance.
Real-World Applications
The paper evaluates state-of-the-art models across datasets like ImageNet and LSUN, showing that PP{additional_guidance}PR can effectively discern model performance nuances not captured by FID. The new metrics provide a clearer understanding of how models trade-off between high fidelity and diversity, offering deep insights into generative model strengths and weaknesses.
Conclusion
The proposed P-precision and P-recall offer a robust, probabilistically grounded approach to evaluating generative models, overcoming significant limitations of traditional kNN-based metrics. Future work could further integrate advanced feature embeddings to enhance metric reliability across diverse datasets. Through addressing fundamental flaws in prior metrics, this research lays a foundation for more reliable and insightful evaluation of generative models in varied applications.