- The paper demonstrates that integrating human guidance into an actor-critic RL framework using the TDQA mechanism significantly improves convergence and driving performance.
- It employs behavior cloning combined with prioritized experience replay based on TD error and Q-Advantage to optimize learning efficiency in complex scenarios.
- Experiments in the CARLA simulator reveal that PHIL-TD3 outperforms baseline methods in training rewards and robustness under challenging driving conditions.
Prioritized Experience-based Reinforcement Learning with Human Guidance for Autonomous Driving
This paper presents the development and evaluation of a human-guidance-based reinforcement learning framework tailored to autonomous driving tasks. By integrating a novel prioritized experience replay mechanism that adapts to human guidance, the framework aims to enhance the learning efficiency and performance of reinforcement learning algorithms.
Overview of Human-Guided Reinforcement Learning
Reinforcement Learning (RL) has greatly impacted various domains by providing solutions to complex control and optimization problems. However, its practical applications often suffer from inefficiencies due to the substantial interactions required with the environment. The incorporation of human guidance into RL presents a potential solution to mitigate these inefficiencies. The paper proposes an innovative approach combining human intervention and demonstration into RL to refine the agent's performance effectively.
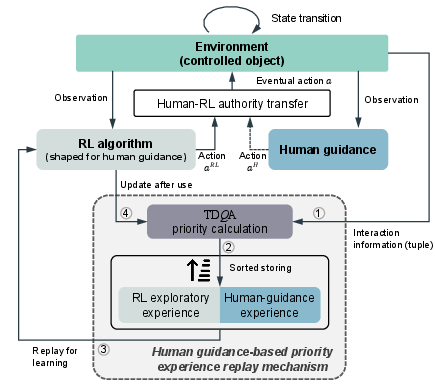
Figure 1: Framework of the proposed human-guided reinforcement learning. TDQA represents the prioritized experience replay mechanism allowing intermittent human-in-the-loop guidance.
Proposed Reinforcement Learning Framework
Human-Guidance-based Actor-Critic Framework
The proposed framework employs an actor-critic architecture incorporating human guidance through behavior cloning and intervention strategies. The human intervention and demonstration act as valuable data sources in shaping the RL agent's policy, enhancing data utilization through a novel prioritized experience replay mechanism (PER).
Prioritized Experience Replay Mechanism (TDQA)
The experience replay buffer utilizes a combination of Temporal Difference (TD) error and Q-Advantage (QA) to dictate the priority of experience replay, termed as TDQA. This mechanism optimizes data input from both human demonstrations and standard RL experiences. Key equations governing this mechanism include:
- Temporal Difference error-based weighting,
pi=∣δiTD∣+ε
- Q-Advantage evaluation,
QA=exp[Q(si,aiH;θ)−Q(si,π(⋅∣si);θ)]
The TDQA mechanism balances quick convergence with robust policy learning by emphasizing human guidance when it offers greater potential benefits than the standard RL exploration data.
Experimental Setup and Results
Task Environment and Configuration
Experiments were conducted using the CARLA simulator in complex autonomous driving scenarios such as unprotected left-turns and highway congestion. The environment setups tested both lateral and longitudinal control capabilities of RL policies across varying complexities.
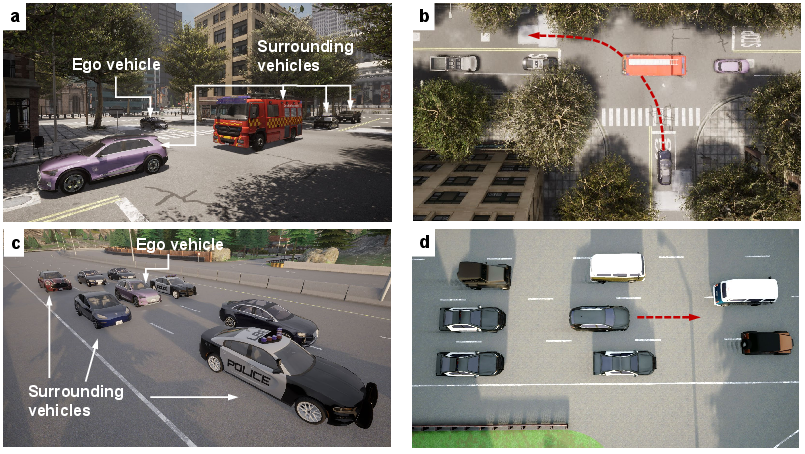
Figure 2: Task environment configuration showing both left-turn and congestion scenarios.
The experiments demonstrated that PHIL-TD3 (Prioritized Human-In-the-Loop RL) achieved rapid convergence and superior asymptotic performance compared to baseline methods, amplified by human-derived data. This was validated across multiple metrics, including training rewards and driving distances.
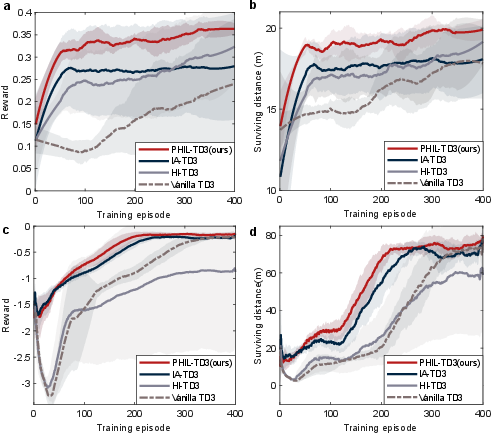
Figure 3: Learning efforts of different RL algorithms in training processes.
Empirical Evaluation
Additional evaluations examined the algorithm's robustness and adaptiveness across different task settings. The PHIL-TD3 was shown to maintain high success rates and consistent performance even in noise-injected and variant scenarios.
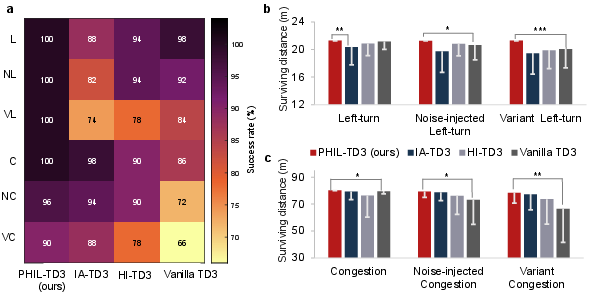
Figure 4: High-level driving performance under various autonomous driving scenarios.
Conclusions
The integration of human guidance into RL through the PHIL-TD3 framework marks an advancement in RL application for autonomous driving. The proposed prioritized experience replay mechanism significantly enhances learning efficiency, adaptability, and robustness. These results underscore the potential of human-guidance-based frameworks to address practical RL challenges effectively, paving the way for further applications in real-world autonomous driving scenarios. Future research could involve deploying PHIL-TD3 in physical vehicles to further assess its real-world efficacy and adaptiveness.

