- The paper introduces a novel quantile-based approach that adapts traditional distributional RL to optimize long-run per-step rewards in an average-reward framework.
- It employs differential updates via quantile regression, replacing average-reward parameters with aggregated quantile estimates for high convergence.
- The method reduces complexity and bias, yielding accurate reward distribution modeling and competitive performance in benchmark tasks.
A Differential Perspective on Distributional Reinforcement Learning
Introduction
This essay explores the extension of distributional reinforcement learning (distributional RL) into the average-reward setting, transitioning from the traditional discounted reward framework. The paper implements a novel approach utilizing quantile-based methods to derive algorithms capable of optimizing long-run per-step reward distributions.
Differential Distributional RL Algorithms
The novel differential distributional RL algorithms focus on learning the limiting per-step reward distribution. The primary goal is to replace the average-reward update in conventional algorithms with equivalent quantile-based updates. These algorithms utilize quantile regression to update the value estimates.
Algorithmic Overview
D2 Q-Learning Algorithm:
- Initiates with arbitrary state-action values and reward quantiles.
- Emphasizes a new form of value update, replacing the average-reward parameter with an aggregation of quantile estimates.
- Achieves high convergence, reflecting accurate modeling of long-run per-step reward distributions.
1
2
3
4
5
6
7
8
9
|
def D2_Q_Learning():
initialize_Q_and_quantiles()
for t in training_steps:
A = policy(S)
R, S' = environment(A)
average_reward = average_quantiles(quantiles)
TD_error = R - average_reward + max(Q(S')) - Q(S, A)
update_values(Q, TD_error)
update_quantiles(quantiles, R) |
The algorithms exhibit competitive performance with traditional non-distributional methods. Key empirical results in tasks like red-pill blue-pill and inverted pendulum environments show:
- Efficient learning of the limiting per-step reward distribution.
- Consistency in achieving or surpassing non-distributional algorithm performance.
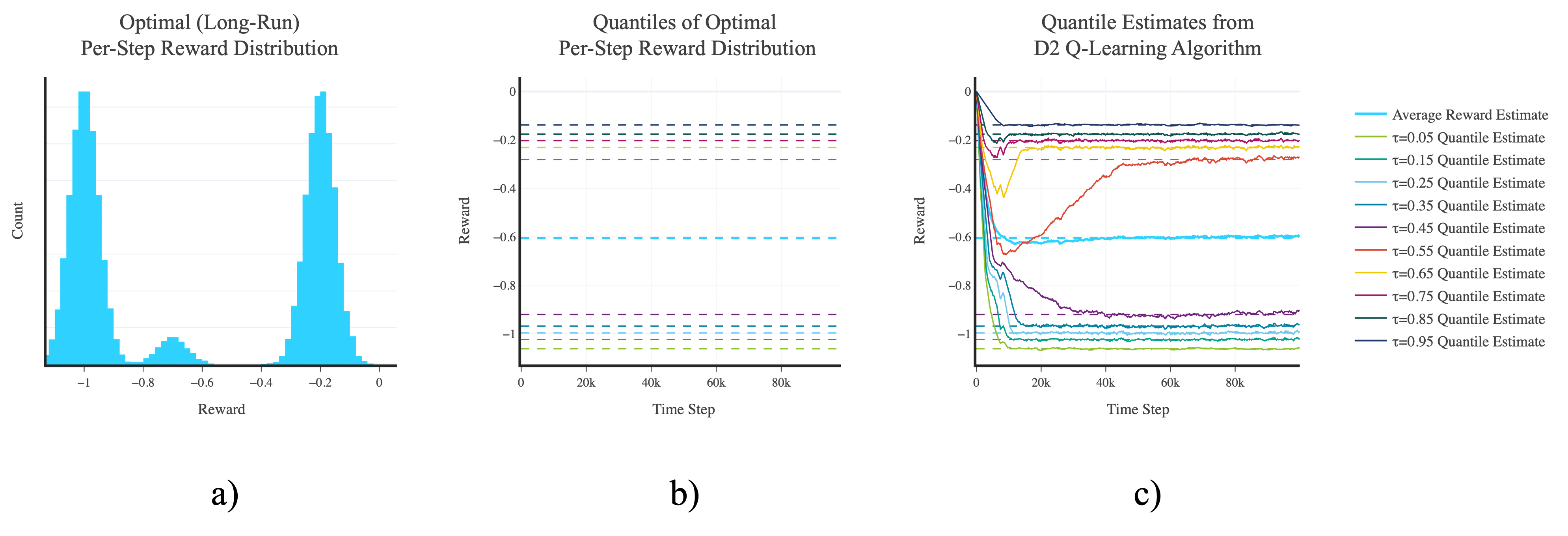
Figure 1: a) Histogram showing the empirical (ε-greedy) optimal (long-run) per-step reward distribution in the red-pill blue-pill task. b) Quantiles of the (ε-greedy) optimal (long-run) per-step reward distribution in the red-pill blue-pill task. c) Convergence plot of the agent's (per-step) reward quantile estimates as learning progresses when using the D2 Q-learning algorithm in the red-pill blue-pill task.
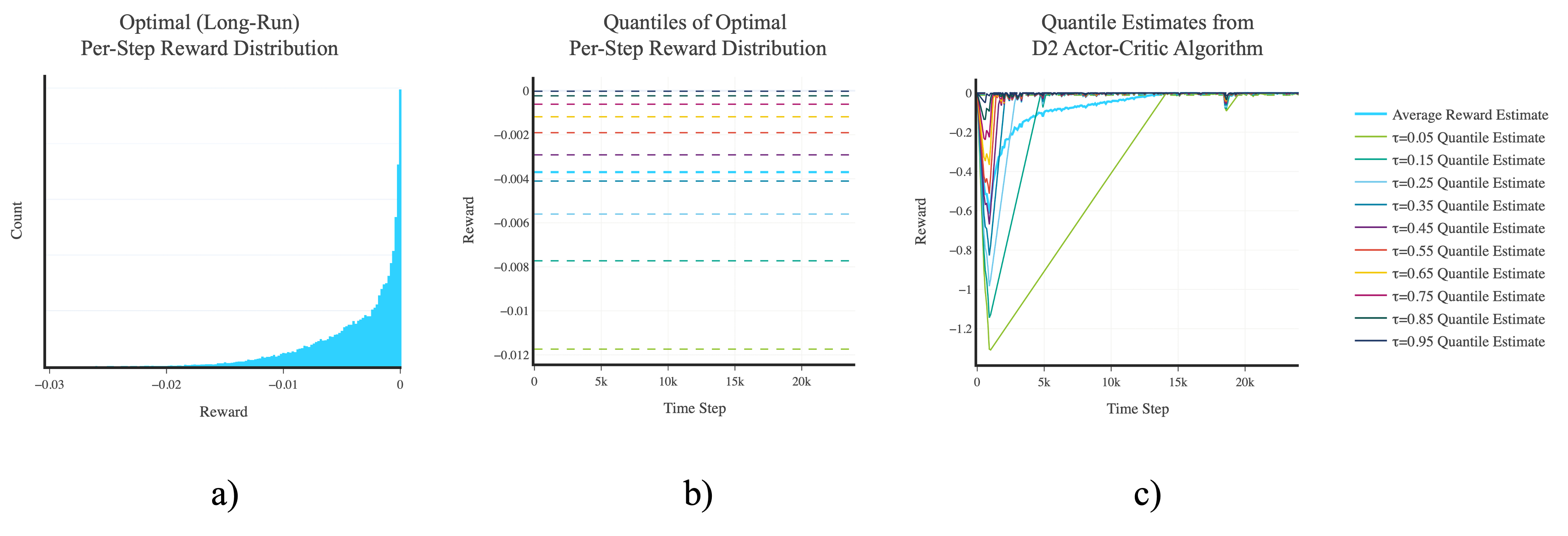
Figure 2: a) Histogram showing the empirical (ε-greedy) optimal (long-run) per-step reward distribution in the inverted pendulum task. b) Quantiles of the (ε-greedy) optimal (long-run) per-step reward distribution in the inverted pendulum task. c) Convergence plot of the agent's (per-step) reward quantile estimates as learning progresses when using the D2 actor-critic algorithm in the inverted pendulum task.
Theoretical Insights and Implications
The proposed quantile-based approach introduces several theoretical implications:
- Scalability: Reduces complexity compared to discounted distributional RL by focusing on fewer parameters.
- Convergence Guarantees: Ensures convergence of the quantile estimates to the true quantiles of the limiting reward distribution.
- Bias Reduction: Offers more accurate estimations, leading to solutions that reliably reflect the actual average-reward.
Challenges and Future Work
Despite its advantages, the research opens up questions for further exploration:
- Extending the approach to more complex tasks and larger environments.
- Exploring alternative parameterizations, such as categorical methods.
- Increasing empirical evaluations to validate the approach's robustness.
Conclusion
The transition from a discounted to an average-reward framework in distributional RL marks a significant advancement. By implementing quantile-based methods, this research paves the way for more effective learning of reward distributions, enriching the toolkit of reinforcement learning practitioners with scalable and reliable algorithms. Further exploration could refine these methods, broadening their applicability across varied RL tasks.