- The paper introduces a novel QRM that uses quantile regression to estimate a full distribution of rewards, capturing multiple modes of human preferences.
- It details a two-step process involving attribute distribution estimation and a gating network for aggregating individual distributions into a comprehensive reward model.
- Experimental results indicate that the approach outperforms conventional scalar reward models, particularly in risk-aware RLHF applications to avoid low-quality outputs.
Quantile Regression for Distributional Reward Models in RLHF
The paper "Quantile Regression for Distributional Reward Models in RLHF" introduces a novel approach to improving Reinforcement Learning from Human Feedback (RLHF) by employing Quantile Reward Models (QRMs) to create distributional reward models that can handle the complexity and diversity of human preferences more effectively than traditional scalar reward models. This approach leverages quantile regression to generate a richer, multimodal distribution of rewards, which better captures the spectrum of human values.
Introduction and Background
Reinforcement learning from human feedback is a critical process used to align LLMs with human preferences. Traditional reward models output a single scalar value, simplifying human values to the detriment of capturing the underlying complexity. RLHF traditionally relies on these point estimates derived from human judgments, leading to limitations in scenarios with diverse and conflicting preferences. This simplification can suppress nuanced feedback, potentially skewing the optimization of LLMs.
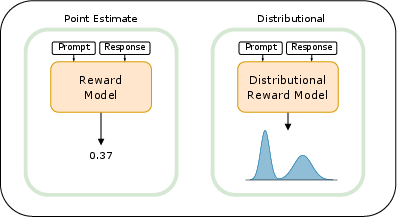
Figure 1: Visualization of two reward estimation methods. The classical point estimate model generates a single scalar value as the reward. In contrast, the distributional reward model proposed in this paper outputs a distribution over possible rewards that can be multimodal.
The proposed QRMs fill this gap by estimating a full distribution using quantile regression, which allows for modeling multiple modes corresponding to different preference interpretations.
Distributional Reward Models
The core innovation in this paper is the QRM, which transforms reward modeling by predicting a distribution over rewards rather than a single point estimate. This involves two key steps:
- Attribute Distribution Estimation: Quantile regression is used to estimate distributions for each of multiple attributes like helpfulness or safety. This is achieved by training on a range of quantiles to capture the shape of the reward distribution across possible outcomes.
- Gating Network for Aggregation: A gating network is then trained to weigh these attribute distributions to produce a final reward distribution. The gating network generates attribute weights, facilitating the blending of individual distributions into a comprehensive reward distribution.
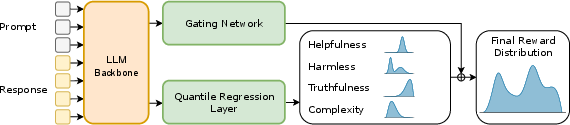
Figure 2: Visualization of our approach. The prompt and response are fed into the LLM backbone, which generates two types of embeddings: a prompt embedding for the gating network and a prompt-response embedding for the quantile regression layers.
Application in Risk-Aware RLHF
The paper explores the practical application of leveraging the additional information contained within distributional rewards. Specifically, risk-aware policies can be devised by applying utility functions over the reward distribution, allowing AI systems to avoid generating poor-quality outputs by respecting diverse user preferences and penalizing low scores.
This approach is significantly beneficial in contexts where avoiding detrimental outliers is crucial, such as conversational agents or safety-critical applications.
Experimental Evaluation
The proposed QRM was evaluated using the RewardBench benchmark, which assesses the effectiveness of reward models across tasks like chat, safety, and reasoning. Empirical results indicate that QRM outperforms conventional scalar models, particularly in handling conflicting preferences. Additionally, using distributional estimates helps train risk-aware policies that are less prone to generating undesirably extreme responses.
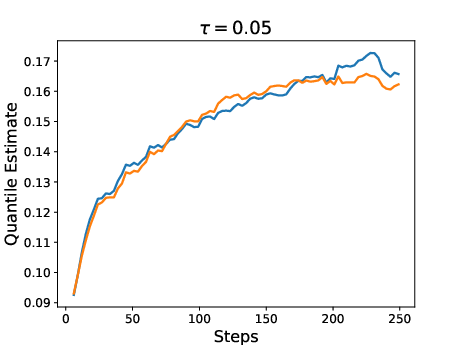
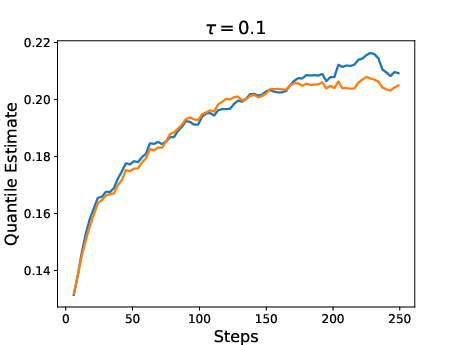
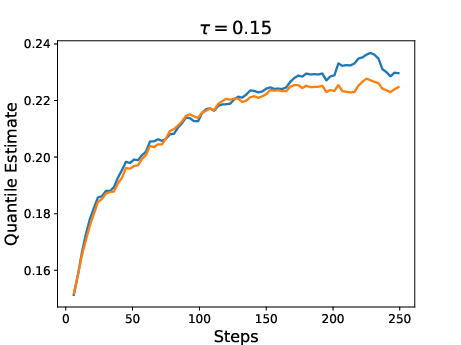
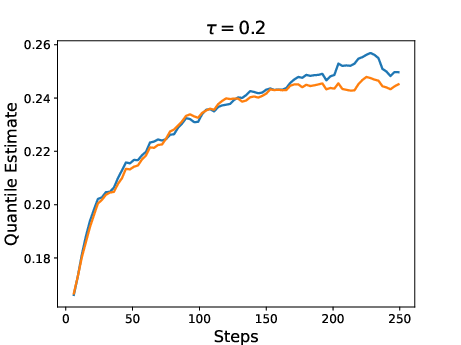
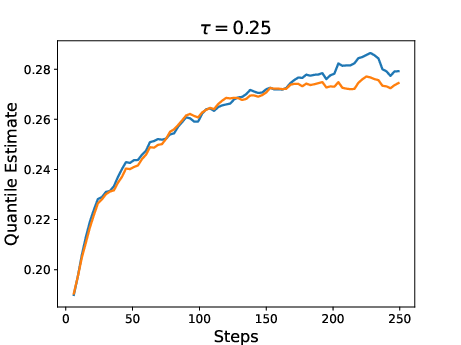
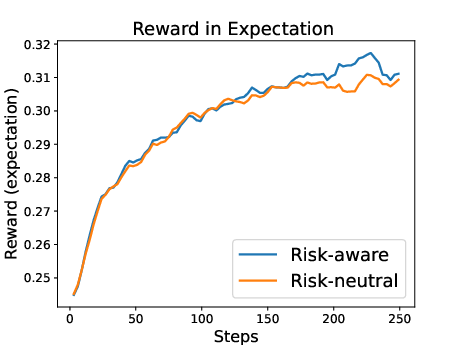
Figure 3: Results for two policies trained with RL using QRM as reward model. One policy was trained with the expectation as reward (risk-neutral) while the other was trained with a risk-aware utility function.
Conclusion
The introduction of Quantile Reward Models represents a meaningful advance in the modeling of human preferences in RLHF. By capturing the full distribution of potential rewards, QRMs enhance the flexibility and robustness of reward models. This research lays the groundwork for future explorations into using distributional models in reinforcement learning, including their application in fine-tuning LLMs and increasing interpretability within AI systems. Future research could expand on leveraging conflicting labels and exploring direct integration with distributional RL algorithms or decoding strategies that exploit the richer reward model distributions.