- The paper presents the Reward Reasoning Model that enables adaptive reward estimation through explicit chain-of-thought reasoning for LLMs.
- It employs multi-response strategies such as ELO ratings and knockout tournaments alongside a reinforcement learning framework with group relative policy optimization.
- Empirical evaluations on benchmarks like MATH and GPQA demonstrate that RRMs significantly outperform existing reward models and enhance RLHF training.
Reward Reasoning Model: Explicit Reasoning for Adaptive Reward Modeling in LLMs
Introduction and Motivation
The Reward Reasoning Model (RRM) paper addresses a critical limitation in current reward modeling for LLM post-training: the inability to adaptively scale test-time compute for reward estimation. Traditional reward models, whether scalar or generative, apply uniform computational resources across all queries, which is suboptimal for complex tasks requiring nuanced, multi-step reasoning. The authors propose RRMs, which explicitly perform chain-of-thought reasoning before producing reward judgments, thereby enabling dynamic allocation of test-time compute based on query complexity.
Model Architecture and Reasoning Process
RRMs are built on the Qwen2 Transformer-decoder backbone and frame reward modeling as a text completion task. Each input consists of a query and two candidate responses. The model is prompted to analyze both responses step-by-step according to criteria such as instruction fidelity, helpfulness, accuracy, harmlessness, and detail, and then output a final judgment in a strict format (no ties allowed). The explicit reasoning phase is central: RRMs generate a chain-of-thought trace before the final reward, allowing for adaptive compute scaling.
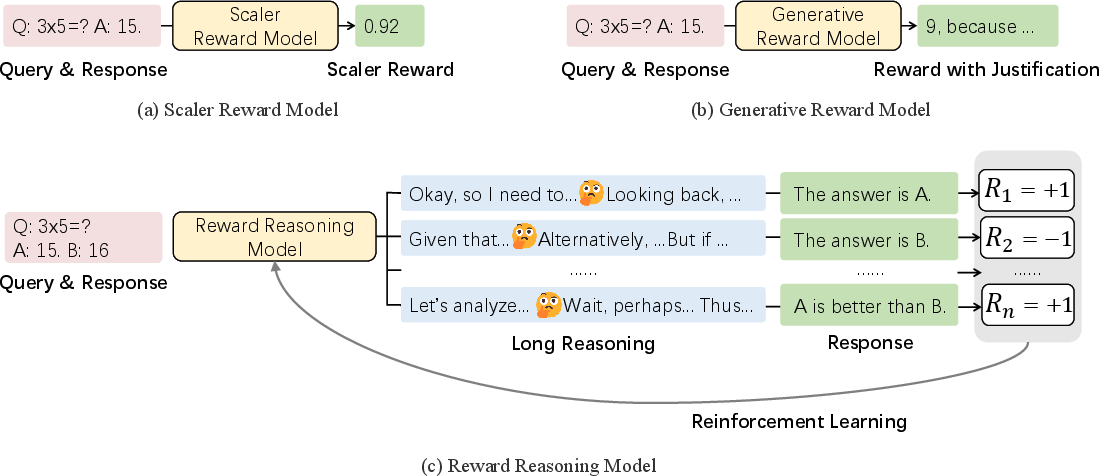
Figure 1: RRMs leverage chain-of-thought reasoning to adaptively utilize test-time compute before producing reward judgments.
Reinforcement Learning Framework for Reasoning
Supervised data with explicit reward reasoning traces is scarce. To address this, the authors introduce a reinforcement learning framework—Reward Reasoning via Reinforcement Learning—where RRMs self-evolve their reasoning capabilities using rule-based rewards. The reward function is binary (+1 for correct preference, -1 otherwise), and training is performed using group relative policy optimization (GRPO) on diverse pairwise preference data. This approach enables the emergence of sophisticated reasoning patterns without explicit supervision of reasoning traces.
Multi-Response Rewarding Strategies
Although RRMs natively accept only two candidate responses, the paper introduces two scalable strategies for multi-response scenarios:
- ELO Rating System: Implements round-robin pairwise comparisons among n candidates, converting win-loss records to ELO scores. This enables fine-grained reward assignment for RLHF pipelines.
- Knockout Tournament: Organizes candidates into brackets, advancing winners through successive rounds. This requires only O(n) comparisons and O(logn) rounds, providing computational efficiency.
Both strategies can be combined with majority voting, further leveraging test-time compute for robust reward assessment.
Empirical Evaluation
Reward Modeling Benchmarks
RRMs are evaluated on RewardBench and PandaLM Test, covering domains such as chat, reasoning, safety, and alignment with human preference. RRMs consistently outperform strong baselines, including scalar models (Skywork-Reward), generative judges (JudgeLM), and production-grade LLMs (GPT-4o, Claude 3.5 Sonnet). Notably, RRM-32B achieves 98.6% accuracy in the reasoning category of RewardBench, surpassing all baselines.
Best-of-N Inference and Preference Proxy Evaluations
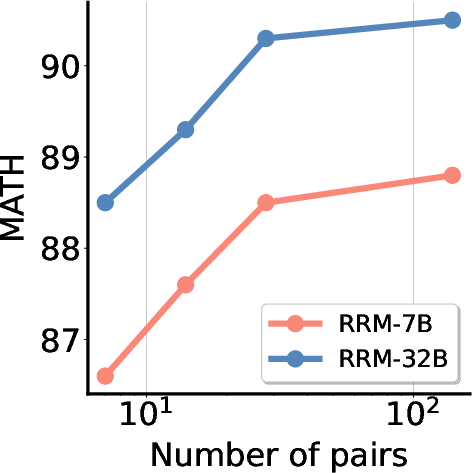
On Preference Proxy Evaluations (PPE), RRMs demonstrate superior accuracy in reward-guided best-of-N inference across MMLU-Pro, MATH, and GPQA subsets.
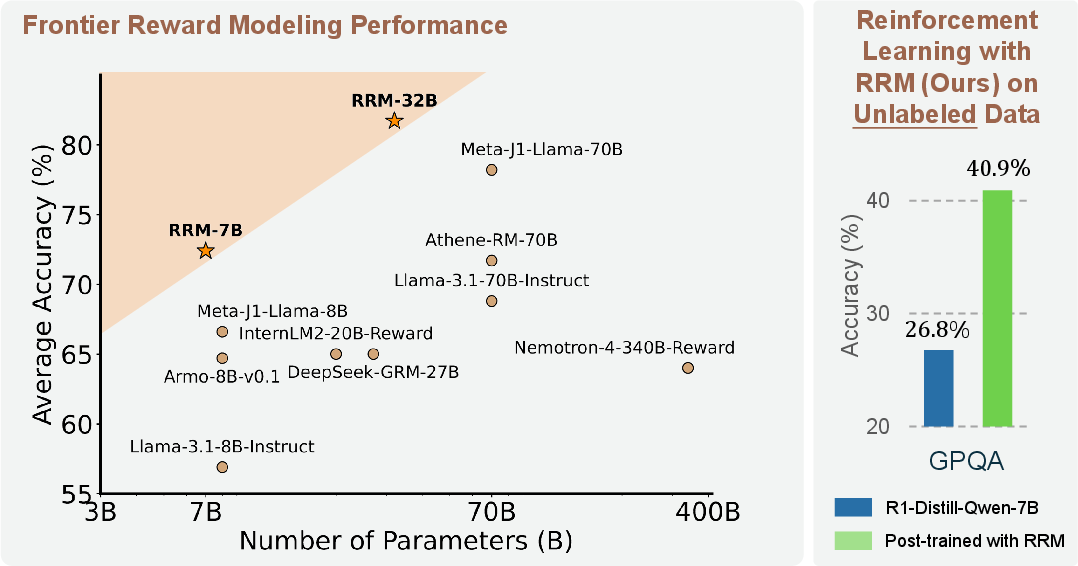
Figure 2: RRMs outperform previous reward models in average accuracy on Preference Proxy Evaluations across MMLU-Pro, MATH, and GPQA.
Majority voting further boosts performance, and RRMs generalize robustly across diverse knowledge domains, including STEM and humanities.
RL Post-Training with RRM Feedback
RRMs are used to supervise RL post-training of LLMs on unlabeled data, with rewards assigned via ELO ratings from RRM pairwise judgments. The downstream models show steady improvement on GPQA and MMLU-Pro benchmarks.
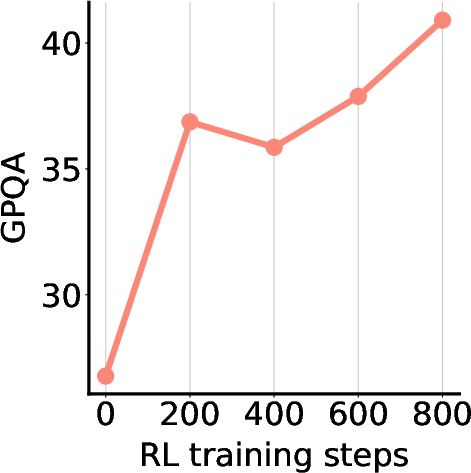
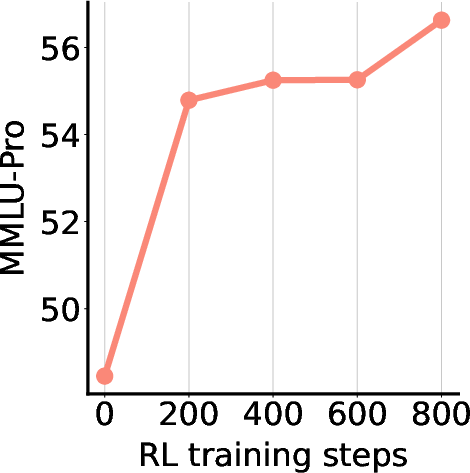
Figure 3: RL post-training with RRM feedback yields consistent accuracy improvements on GPQA and MMLU-Pro.
Scaling Test-Time Compute
The paper systematically analyzes parallel and sequential scaling of test-time compute:
Reasoning Pattern Analysis
Statistical analysis reveals that RRMs develop distinct reasoning patterns compared to untrained foundation models. RRM-32B exhibits higher utilization of transition, reflection, and comparison patterns, indicating more thorough and iterative evaluation processes. This is corroborated by case studies showing deeper self-reflection and comparative analysis in RRM outputs.
Implementation Considerations
- Training: RRMs require diverse pairwise preference data, which can be synthesized using LLMs and rule-based verifiers. Training is compute-intensive, especially for larger models (e.g., 32B parameters), and benefits from high-throughput accelerators.
- Inference: Adaptive test-time compute is realized via chain-of-thought prompting, majority voting, and scalable multi-response strategies (ELO, knockout). These methods allow practitioners to trade off between accuracy and computational cost.
- Deployment: RRMs are suitable for integration into RLHF pipelines, reward-guided inference, and direct preference optimization (DPO). Their explicit reasoning traces enhance interpretability and reliability in high-stakes applications.
Implications and Future Directions
The explicit reasoning paradigm in reward modeling represents a significant methodological shift, enabling dynamic allocation of inference resources and improved alignment with human preferences. RRMs' ability to scale test-time compute and develop sophisticated reasoning patterns suggests promising avenues for:
- Generalist Reward Modeling: RRMs can serve as universal evaluators across domains, including open-ended and complex tasks.
- Self-Improving Systems: The reinforcement learning framework allows for continual self-evolution of reward reasoning capabilities.
- Interpretability and Reliability: Explicit reasoning traces facilitate auditing and debugging of reward judgments, critical for safety and alignment.
Future research may explore further scaling laws, integration with multimodal inputs, and the development of meta-reward models capable of self-improvement and bias mitigation.
Conclusion
The Reward Reasoning Model paper introduces a principled approach to reward modeling in LLMs, leveraging explicit chain-of-thought reasoning and adaptive test-time compute. Empirical results demonstrate state-of-the-art performance across diverse benchmarks and practical RLHF applications. The reinforcement learning framework enables the emergence of robust reasoning patterns without explicit supervision, and scalable multi-response strategies provide flexibility for real-world deployment. RRMs represent a compelling direction for advancing reward modeling, alignment, and interpretability in large-scale LLM systems.