- The paper introduces HRM, a model that evaluates both individual and sequential reasoning steps to correct errors and enhance decision accuracy.
- It proposes HNC, a novel data augmentation technique that merges MCTS nodes, reducing the need for expensive human annotation while boosting robustness.
- Experiments on datasets like PRM800K, GSM8K, and MATH500 demonstrate HRM’s superior stability and generalization compared to traditional reward models.
HRM: Enhancing Reasoning in LLMs via Hierarchical Multi-Step Reward Models
This paper introduces the Hierarchical Reward Model (HRM) to improve the reasoning capabilities of LLMs. HRM addresses the limitations of Process Reward Models (PRM) by evaluating both individual and consecutive reasoning steps, enabling better assessment of reasoning coherence and self-reflection. Additionally, the paper introduces Hierarchical Node Compression (HNC) to enhance the efficiency and robustness of Monte Carlo Tree Search (MCTS) data augmentation.
Addressing Limitations of Existing Reward Models
The paper identifies key limitations in existing reward models used to enhance LLM reasoning. Outcome Reward Models (ORM) suffer from delayed feedback and credit assignment issues, making it difficult to determine which intermediate steps contribute to the final outcome. PRMs, while offering more granular feedback, are prone to reward hacking and require extensive manual annotation, leading to high costs and potential unreliability. HRM is proposed to mitigate these issues by incorporating both fine-grained and coarse-grained reasoning evaluations, allowing for self-reflection and error correction.
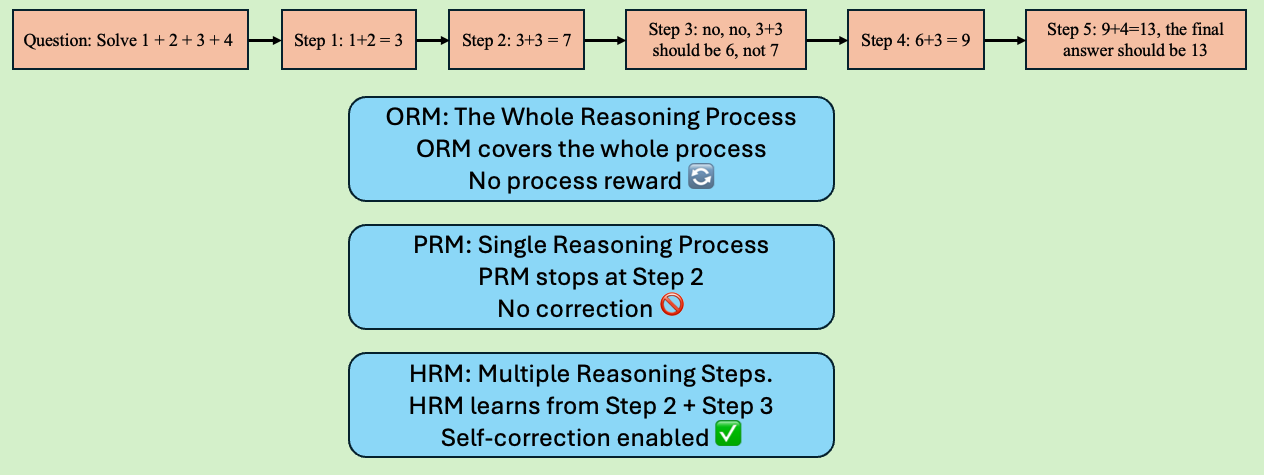
Figure 1: Illustration of how ORM, PRM, and HRM handle reasoning processes, with HRM considering multiple consecutive steps for error correction.
The Hierarchical Reward Model (HRM)
HRM differs from PRM by evaluating not only individual reasoning steps but also consecutive steps, enabling the reward model to assess multi-step reasoning coherence. This approach allows the model to identify and incorporate subsequent steps that rectify earlier errors, leading to more robust and reliable evaluations. The training dataset for HRM includes consecutive reasoning sequences, allowing the model to capture both fine-grained and coarse-grained reasoning consistency. Unlike PRM, HRM does not terminate evaluation upon encountering an error, but rather assesses whether subsequent steps correct earlier mistakes.
Hierarchical Node Compression (HNC) for MCTS Data Augmentation
The paper addresses the high cost of human-annotated supervision in training PRMs by introducing Hierarchical Node Compression (HNC), a data augmentation method for MCTS. HNC merges two consecutive nodes in the MCTS tree into a single node, expanding the training dataset while maintaining minimal computational overhead.
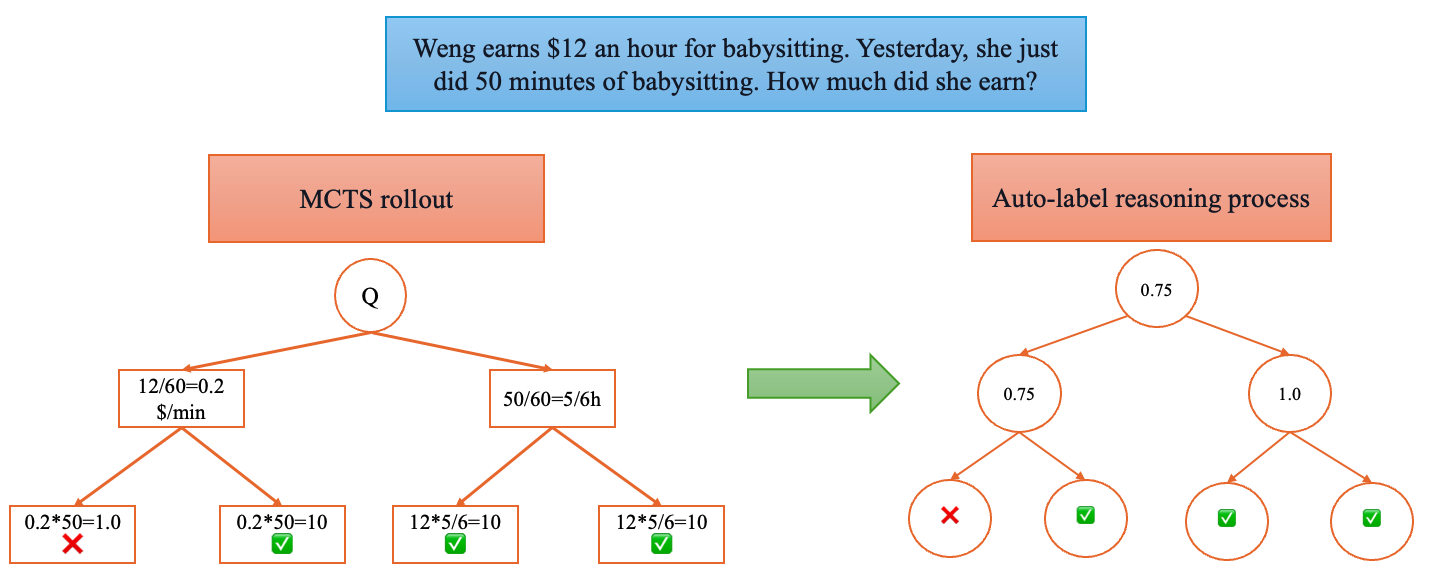
Figure 2: Diagram illustrating how HNC transforms the MCTS structure by merging two consecutive nodes into one.
HNC introduces controlled noise by randomly removing or merging consecutive nodes, enhancing the robustness of MCTS-based scoring. By consolidating nodes, HNC redistributes weights among the remaining nodes, improving the resilience of the scoring mechanism and diversifying the generated reasoning data.
Experimental Results and Analysis
The paper presents empirical results on the PRM800K dataset, demonstrating that HRM, in conjunction with HNC, achieves superior stability and reliability compared to PRM. Specifically, HRM's accuracy stabilizes at 80% as the number of reasoning trajectories (N) increases, while PRM and ORM exhibit significant performance fluctuations. The experiments also evaluate the generalization of HRM trained on PRM800K using auto-labeled reasoning processes from MCTS and HNC, showing that HRM achieves superior reasoning consistency and generalizes effectively across GSM8K and MATH500 datasets.
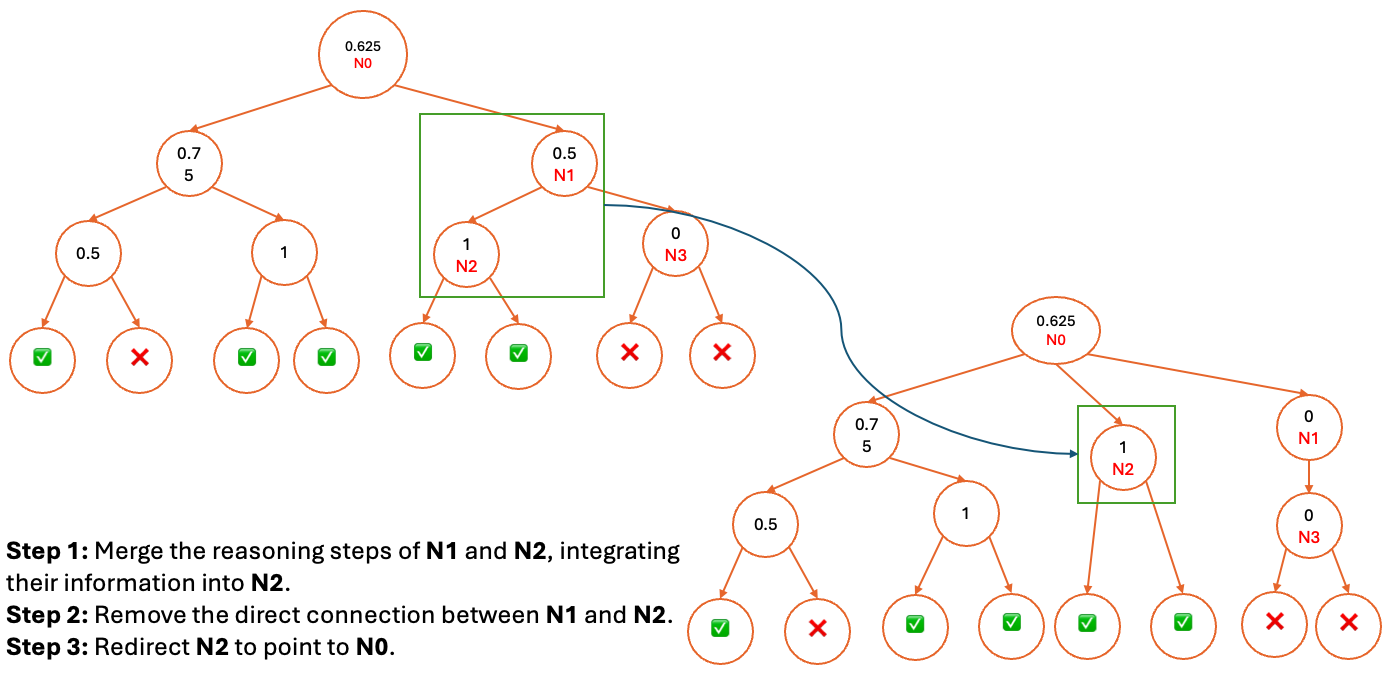
Figure 3: An alternative illustration of Hierarchical Node Compression, emphasizing the transformation of the MCTS structure.
Self-Training with KL Divergence Regularization
The paper employs a self-training approach to filter high-quality reasoning data from MCTS, using either MC-Score or HRM to assign scores. To mitigate reward hacking, a high-quality data filter based on MC-Score is applied. The objective function combines causal language modeling loss with KL divergence regularization, using a weighting factor (λ) to balance task-specific adaptation and retention of general capabilities. The paper notes that without proper KL regularization, the KL divergence can grow unbounded, necessitating the logarithmic scaling of the KL term to stabilize the loss landscape.
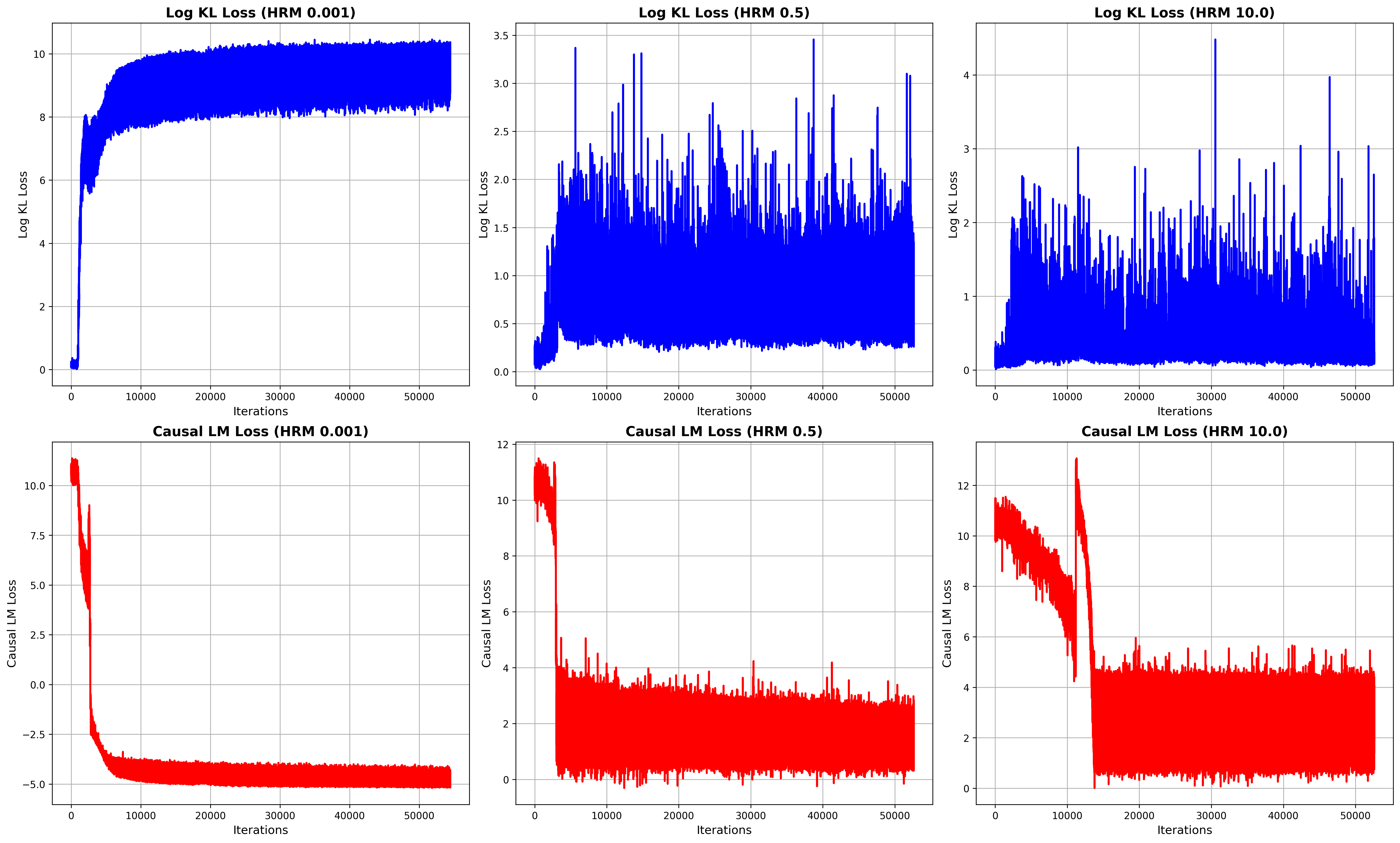
Figure 4: Visualization of loss dynamics during training with different KL loss weightings, showing the impact on KL loss and causal language modeling loss.
Implications and Future Directions
The HRM framework offers a more robust and reliable approach to reward modeling in LLMs, addressing the limitations of PRM and ORM. The introduction of HNC further enhances the efficiency and diversity of MCTS-based data augmentation, reducing the reliance on expensive human annotations. The empirical results demonstrate the effectiveness of HRM in improving reasoning consistency and generalization across different domains. Future research could explore the application of HRM in more complex reasoning tasks and investigate alternative data augmentation strategies to further enhance the robustness and efficiency of reward model training.
Conclusion
The paper makes significant contributions to the field of LLM reasoning by introducing HRM and HNC. These methods enhance the robustness, reliability, and generalization capabilities of LLMs in reasoning-intensive tasks. The combination of hierarchical reward modeling and efficient data augmentation offers a promising direction for future research in this area.