Hierarchical Reasoning Model
Abstract: Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current LLMs primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency. HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes. Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities. These results underscore HRM's potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new kind of AI model, called the Hierarchical Reasoning Model (HRM), that’s designed to “think” in a more brain-like way. Instead of writing out long chains of text to reason step by step (like many current AI systems do), HRM does most of its thinking quietly inside, using two parts that work at different speeds: a slow planner and a fast problem-solver. With just a small amount of training data and a relatively small model size, HRM solves tough puzzles like extreme Sudoku, large mazes, and ARC-AGI tasks better than much larger models.
What questions are the researchers asking?
In simple terms, they ask:
- Can we build an AI that reasons deeply without needing to write out every step as text?
- Can it plan (slowly) and compute details (quickly) in a way that’s efficient and stable?
- Can a small model trained on very little data solve hard logic problems that big models struggle with?
- Can it learn and decide how long it needs to “think” before giving an answer?
How does their model work?
Think of HRM as a team with two roles that cooperate over time:
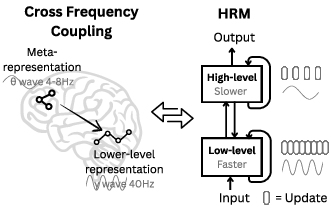
Two-level, brain-inspired design
- High-level module (the “planner” or coach): updates slowly, makes big-picture decisions, and guides the overall strategy.
- Low-level module (the “doer” or player): updates quickly, tries out detailed steps, searches, and cleans up mistakes.
This separation is inspired by how parts of the brain operate at different speeds (slow rhythms guiding fast rhythms) and talk back and forth.
Thinking in cycles
- The fast module takes several quick steps to settle on a local decision (like testing a bunch of moves).
- Then the slow module updates once, based on what the fast module discovered, and sets a new direction.
- This repeats for N cycles. At the end, the model outputs the answer.
Analogy: The player (fast) plays a few turns and reports progress; the coach (slow) updates the plan; repeat. This lets the model do many layers of reasoning without getting stuck.
Learning efficiently without replaying every step
Many “recurrent” models learn by replaying the entire sequence of steps backward to adjust their weights (called “Backpropagation Through Time”), which is memory-heavy. HRM uses a clever shortcut:
- It learns mainly from the final states in each cycle (a “one-step gradient” approximation), like improving based on the end result rather than rewinding the whole movie.
- This makes training much more memory-efficient and stable, yet still effective.
They also use “deep supervision”: the model practices in short segments, learns after each, then “detaches” and continues — like doing mini-rounds of practice and locking in what it learned before starting the next round.
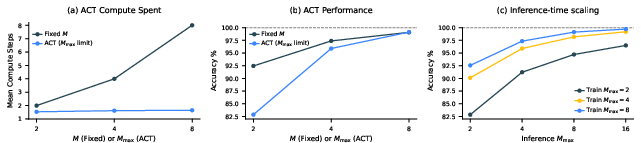
Knowing when to stop (Adaptive Computation Time)
Sometimes a puzzle is easy; sometimes it’s hard. HRM learns to decide when to stop thinking:
- It comes with a small “Q-head” that estimates whether it should halt now or continue another segment.
- If it thinks the answer is already good, it stops early; if not, it keeps going.
- Over time, it learns a smart trade-off: use more thinking for harder problems and less for easier ones.
What did they find?
Here are the main results:
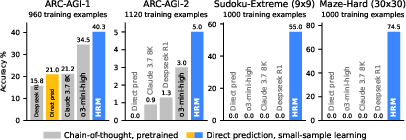
- Tough puzzles solved with little data: With only about 1,000 training examples and no pretraining, HRM (about 27 million parameters) performs extremely well on:
- Sudoku-Extreme: near-perfect on very hard puzzles that need deep search and backtracking.
- Maze-Hard (30×30): finds optimal paths where chain-of-thought (CoT) methods failed completely (0%).
- Outperforms much larger models on ARC-AGI: On ARC-AGI (a benchmark for abstract reasoning), HRM reaches about 40.3%, beating larger chain-of-thought systems like o3-mini-high (34.5%) and Claude 3.7 (8K context, 21.2%).
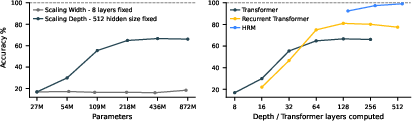
- Efficient and scalable thinking: The model uses constant memory for its learning shortcut, trains stably, and at test time can do better simply by letting itself “think longer” (especially useful for Sudoku).
Why this matters: These tasks require multi-step logic, planning, and search — skills that current LLMs often struggle with unless they produce long, fragile chains of text. HRM does the reasoning internally and robustly.
What does this mean going forward?
- More thinking, fewer tokens: HRM shows that AI can reason well without writing out every step as text or needing huge training sets. That could mean faster, cheaper, and more private AI (fewer tokens, less data).
- Toward general-purpose reasoning: The two-speed, planner–doer design makes it easier to handle problems that need both long-term planning and quick detailed checks — a good recipe for general problem solving.
- Flexible compute: The adaptive halting learns when to think more or less, saving time on easy problems and pushing harder on tough ones.
- Brain-inspired ideas help: Borrowing concepts like hierarchy, different timescales, and stable feedback loops can lead to AI that’s deeper and more efficient.
- Not the final answer, but a strong step: HRM doesn’t make AI “fully general,” but it’s a promising move toward models that can plan, search, and reason with less data and simpler training. Future work could refine how the two modules communicate, improve interpretability (understanding its internal strategy), and combine this approach with other architectures.
In short, this paper shows a practical way to get deep, stable reasoning from a small model trained on little data, by organizing thinking like a coach-and-player team that knows when to plan slowly and when to act fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions left unresolved by the paper that future work could address:
- ARC-AGI evaluation protocol clarity and fairness:
- The paper states it “start[s] with all input-output example pairs in the training and the evaluation sets,” and prepends a learnable token per puzzle. This risks training on evaluation tasks and leaking task identity; provide leaderboard-compliant results that exclude evaluation-set examples and any per-task learned token for unseen eval tasks.
- Quantify how much performance comes from heavy test-time augmentation (1,000 augmented solves per test input with majority vote), and compare against baselines granted the same augmentation budget to ensure fairness.
- Compute, efficiency, and latency:
- Report training/inference FLOPs, wall-clock latency, and energy for HRM versus CoT baselines, including the cost of multiple cycles, multiple segments (ACT), and 1,000 test-time augmented runs on ARC-AGI.
- Characterize the accuracy–compute frontier and whether HRM’s gains persist under matched compute budgets and strict latency constraints.
- Theoretical guarantees for hierarchical convergence and 1-step gradients:
- Provide conditions (e.g., contraction properties, bounds on the spectral radius of Jacobians) under which hierarchical convergence is guaranteed and stable.
- Quantify the error of the one-step gradient approximation relative to exact BPTT/IFT-based gradients (e.g., gradient alignment metrics, convergence guarantees, bias/variance analysis) and when it is expected to fail.
- Ablation studies and design choices:
- Systematically ablate N/T (number of cycles/timesteps), L-module reset policy, deep supervision, ACT, stablemax vs softmax, RMSNorm/Post-Norm, Adam-atan2, and simple addition vs gating/attention-based fusion.
- Compare HRM to recurrent/state-space baselines (e.g., DEQ/implicit models, RWKV, S4/Mamba, Hyena, RMT) and to recurrent Transformers trained with truncated BPTT at matched parameter and compute scales.
- Generalization to larger problem sizes and distribution shifts:
- Evaluate scaling to larger mazes (e.g., 50×50, 100×100), larger Sudoku variants (e.g., 16×16), and ARC tasks with larger grids or different color vocabularies to test asymptotic behavior and computational depth claims.
- Test robustness to distribution shifts (noisy inputs, permuted conventions, partial occlusion) and to tasks with multiple valid solutions.
- Transfer, multitask learning, and reuse:
- Assess whether a single HRM trained jointly can solve ARC, Sudoku, and Maze simultaneously without catastrophic interference, and whether the H-module reuses shared abstractions across tasks.
- Measure few-shot transfer to novel but related task families (e.g., new rule compositions in ARC or new maze topologies).
- Interpretability of latent reasoning:
- Move beyond qualitative visualizations to identify algorithmic primitives (e.g., counters, stacks, constraint propagation) in z_H/z_L using probing, causal interventions, and state-machine extraction.
- Correlate L-module reset “spikes” with identifiable backtracking events and quantify plan/search dynamics over cycles.
- ACT stability and policy quality:
- Provide empirical stability analyses of Q-learning without replay/target networks across seeds and tasks; report sensitivity to ε, M_min/M_max, and reward design.
- Compare ACT to alternatives (e.g., PonderNet, Graves’ ACT with ponder cost, entropy regularization) and study “overthinking” failure modes.
- Robustness and reliability:
- Analyze systematic failure cases (e.g., near-miss Sudoku violations, suboptimal maze paths) and add self-checkers/refinement loops; study calibration of halting/confidence signals and abstention mechanisms.
- Architectural scalability and memory:
- Attention in H/L Transformers is quadratic; evaluate memory/runtime scaling for longer contexts and explore sparse/linear attention or convolutional/equivariant alternatives better suited to large grids.
- Dependence on data augmentation:
- Quantify performance drop without augmentation on ARC; disentangle gains from learned invariances versus augmentation; evaluate architectures with built-in symmetries (e.g., permutation/rotation equivariance).
- Benchmark breadth and comparators:
- Include comparisons to classical or neuro-symbolic solvers (e.g., SAT/CP for Sudoku, BFS/A* for mazes) and hybrid search+policy/value methods to situate HRM’s absolute capability and compute efficiency.
- Reproducibility and statistical rigor:
- Report variance across multiple seeds, confidence intervals, hyperparameters (including N, T), and training/inference compute; release code, checkpoints, and the exact Sudoku-Extreme split.
- Claims on computational universality:
- Provide formal results or empirical scaling studies connecting HRM to stronger computational classes (e.g., simulating polytime TM on families of growing inputs with polynomial compute in size).
- Output modality and applicability beyond grids:
- Clarify how HRM would handle long-form autoregressive outputs (language, code, math proofs), including decoding strategy and alignment with next-token prediction objectives; benchmark on standard reasoning suites (GSM8K, MATH, HumanEval, MiniF2F).
- Safety and termination guarantees:
- Prove or empirically validate bounded-time termination under ACT (no pathological loops) and study safe-guarded halting thresholds under distribution shift.
- Brain correspondence claims:
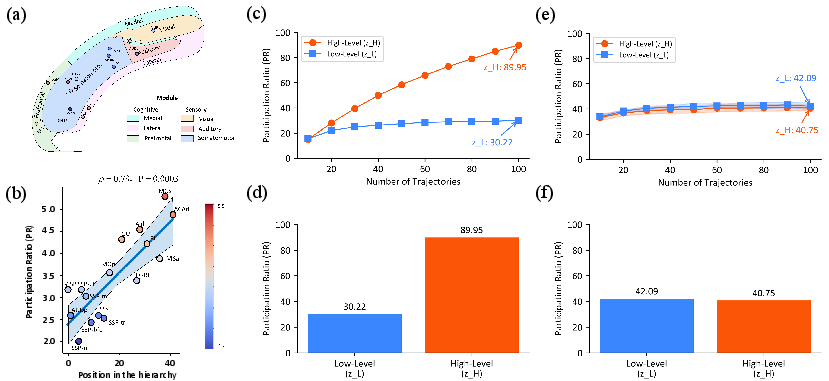
- Go beyond PR dimensionality analyses to test stronger neuro-inspired predictions (e.g., causal roles of timescales, credit assignment locality), and verify whether learned dynamics align with known oscillatory coupling patterns.
- Tokenization/representation choices:
- Evaluate the impact of grid flattening versus spatially aware encoders (e.g., convs, graph/message-passing) and whether spatial inductive biases reduce compute or data needs.
- Error decomposition across the hierarchy:
- Measure how much each module (H vs L) contributes to final accuracy and how errors propagate across cycles; test partial freezing of modules to isolate roles and assess modularity.
Practical Applications
Immediate Applications
Below are concrete applications that can be prototyped or deployed now by leveraging HRM’s architecture, training recipe, and demonstrated capabilities on grid- and sequence-structured reasoning tasks.
- Constraint-satisfaction solvers for operations and logistics
- Sectors: manufacturing, transportation, retail, public services
- Tools/products/workflows: HRM-based solvers for timetabling, shift rostering, bin packing, warehouse pick-path planning, and last-mile routing; use HRM to generate feasible assignments or high-quality heuristics that seed classical solvers (e.g., CP-SAT, MILP)
- Why HRM: strong performance on Sudoku (a prototypical CSP) with small data; adaptive computation time (ACT) to bound runtime; inference-time scaling to trade off speed/quality
- Assumptions/dependencies: task must be representable as discrete sequences/grids; availability of ~103 representative input–output pairs or synthetic data; may need hybridization with exact solvers for guarantees
- Path planning on occupancy grids for robotics and autonomous systems
- Sectors: robotics, drones, autonomous mobile robots (AMR/AGV), indoor mapping
- Tools/products/workflows: map-to-path module where occupancy grid → HRM → shortest path; ACT sets real-time budget; integrate as a drop-in learned planner or as a heuristic to A*/D* expansions
- Why HRM: near-perfect optimal pathfinding on 30×30 mazes with tiny training sets; small model size (≈27M) fits edge devices
- Assumptions/dependencies: grid-based planning; must handle dynamics/uncertainty with an outer control loop; requires domain adaptation to non-grid kinematics and noisy perception
- Programming-by-example for data transformation (ARC-like)
- Sectors: software, data engineering, business intelligence
- Tools/products/workflows: spreadsheet/ETL assistants that learn table/grid transformations from a handful of before–after examples; macro induction; low-code data cleaning
- Why HRM: strong results on ARC-AGI with only the official dataset; robust to few-shot, compositional rules
- Assumptions/dependencies: transformations must be cast as tokenized grids/sequences; careful data augmentation improves robustness; out-of-distribution generalization must be validated per domain
- Embedded and on-device puzzle/logic assistants
- Sectors: consumer apps, education, games
- Tools/products/workflows: offline Sudoku/maze solver apps; interactive tutors that visualize intermediate HRM states to explain reasoning steps
- Why HRM: small footprint, no reliance on CoT token generation; intermediate state visualization demonstrated
- Assumptions/dependencies: UI to render intermediate predictions; content licenses for commercial puzzles
- “Reasoning head” for agentic systems to replace or reduce CoT
- Sectors: software, customer support, productivity tools
- Tools/products/workflows: HRM as an internal solver for discrete sub-tasks (planning, slot-filling with constraints, board-state transforms) called by an LLM agent; reduce token latency and cost by moving from CoT to latent reasoning
- Why HRM: executes multi-step reasoning in a single forward pass; ACT budgets compute; one-step gradient training enables efficient fine-tuning
- Assumptions/dependencies: clear sub-task contract and serialization between LLM and HRM; guardrails for failure cases; task interfaces as structured states
- Accelerators for classical search, SAT/SMT, and theorem provers
- Sectors: EDA, formal methods, verification
- Tools/products/workflows: use HRM to learn branching/variable-ordering heuristics; plug-in heuristic scorer to reduce backtracks or guide proof search
- Why HRM: excels at backtracking-style reasoning; provides fast latent computation with bounded runtime
- Assumptions/dependencies: careful integration with existing solvers; needs labeled traces or self-play to learn high-quality heuristics
- Academic tooling and small-lab training
- Sectors: academia, startups
- Tools/products/workflows: O(1)-memory training of deep recurrent reasoning models on commodity GPUs; reproducible HRM baselines for reasoning benchmarks; curriculum learning studies
- Why HRM: one-step gradient approximation avoids BPTT; deep supervision stabilizes training; works with ~1k samples
- Assumptions/dependencies: implementation fidelity (RMSNorm, post-norm, optimizer details); hyperparameter discipline for stability
- Dynamic compute governance in production inference
- Sectors: cloud AI, MLOps
- Tools/products/workflows: ACT to enforce SLAs and “pay-as-you-think” billing; configurable M_max for tiered service levels
- Why HRM: built-in Q-learning halting with binary correctness reward; demonstrated compute–accuracy trade-offs
- Assumptions/dependencies: monitoring for Q-learning stability; task-specific reward shaping if correctness is not binary
Long-Term Applications
The following applications require further research, domain adaptation, scaling, or safety validation before broad deployment.
- General-purpose latent reasoners integrated into LLMs
- Sectors: software, productivity, enterprise AI
- Tools/products/workflows: jointly trained LLM+HRM systems where the LLM delegates sub-problems to HRM instead of emitting long CoT; reduced latency and cost; improved privacy by limiting tokenized traces
- Dependencies: multi-task training pipelines; unified interfaces between text and structured states; interpretability and safety audits
- Industrial-scale planning and scheduling under uncertainty
- Sectors: supply chain, aviation, energy, healthcare operations
- Tools/products/workflows: HRM-driven planners for network reconfiguration, disruption re-planning, airline recovery, surgical theater scheduling
- Dependencies: stochastic/robust optimization wrappers; regulatory requirements; hybridization with simulators and hard constraints; evaluation on large, non-grid instances
- Scientific discovery assistants (symbolic reasoning and search)
- Sectors: materials, biology, physics, math
- Tools/products/workflows: experiment design, hypothesis refinement, symbolic regression, automated theorem proving with HRM search strategies
- Dependencies: specialized representations (graphs, formulas), domain-specific rewards beyond binary correctness, rigorous validation and provenance tracking
- Formal verification and secure software synthesis
- Sectors: critical systems, automotive, aerospace
- Tools/products/workflows: HRM as a proof-search controller or program synthesizer under specifications; adaptive compute to meet certification-time budgets
- Dependencies: soundness guarantees, integration with proof assistants, adversarial robustness and explainability
- Energy systems optimization at grid scale
- Sectors: power generation and distribution
- Tools/products/workflows: unit commitment, outage restoration sequencing, microgrid reconfiguration; HRM-guided heuristics for faster near-optimal decisions
- Dependencies: coupling to physics-constrained solvers (AC power flow), safety constraints, real-time telemetry, large-scale benchmarks
- Neuromorphic and edge hardware implementations
- Sectors: semiconductors, embedded AI, robotics
- Tools/products/workflows: HRM-inspired recurrent stacks with local/temporally local learning rules; ACT for energy-efficient operation
- Dependencies: hardware support for recurrent equilibria and normalization; mapping one-step gradient approximations to local rules; co-design with memory hierarchies
- Human-in-the-loop educational copilots for reasoning
- Sectors: education, workforce upskilling
- Tools/products/workflows: adaptive tutors that adjust “thinking time” per student/problem via ACT; offer interpretable intermediate states and counterfactuals
- Dependencies: robust pedagogy for revealing latent steps without hallucination; content alignment and accessibility; efficacy trials
- Finance and market microstructure optimization
- Sectors: trading, market making, operations
- Tools/products/workflows: HRM-guided order routing, portfolio rebalancing with discrete constraints, clearing/settlement workflows
- Dependencies: non-stationary environments, regulatory constraints, risk controls, backtesting at scale
- Policy and sustainability tooling for compute-efficient AI
- Sectors: public policy, ESG, cloud economics
- Tools/products/workflows: frameworks that encourage adaptive compute (ACT) and small-data training; procurement guidelines favoring bounded-runtime models
- Dependencies: standard benchmarks for energy/performance, auditability of halting policies, ecosystem adoption
- Cross-modal hierarchical controllers for embodied agents
- Sectors: consumer robotics, industrial automation
- Tools/products/workflows: HRM extended to multimodal inputs (vision, touch, language) to plan at long/short horizons; inference-time scaling for hard tasks
- Dependencies: robust perception, safety envelopes, sim-to-real transfer, long-horizon credit assignment beyond grid-worlds
Notes on feasibility across applications:
- Representation alignment is critical: tasks must be expressed as token sequences/grids or be transduced into such forms (graphs/sets may need adapters).
- Data regimes vary: while HRM learns from ~1k examples on studied tasks, other domains may need synthetic data, curriculum learning, or hybrid supervision.
- Stability hinges on architectural and optimizer choices (post-norm, RMSNorm, AdamW/atan2, warmup) and on the ACT/Q-learning setup; reward design may need to move beyond binary correctness.
- For safety-critical domains, HRM should be paired with verifiers, constraint solvers, or formal methods to ensure guarantees and traceability.
Collections
Sign up for free to add this paper to one or more collections.