- The paper introduces a self-training framework that integrates reward-guided tree search to refine LLM reasoning traces and value predictions.
- The paper demonstrates improved accuracy over existing methods on SciBench and MATH datasets using a modified Monte Carlo Tree Search with process rewards.
- The paper's iterative self-training pipeline enhances both policy and reward models, making LLM reasoning more efficient and reliable.
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Introduction
The advancement of self-training methodologies in LLMs has predominantly leveraged LLM-generated responses, filtering data to only include those that lead to correct outputs. This paper introduces a novel approach, ReST-MCTS*, which aims to create higher-quality reasoning traces and value predictions for LLM self-training. The key innovation lies in the integration of process reward guidance with tree search, effectively allowing LLMs to refine their reasoning capabilities by collecting valuable intermediate reasoning steps without manual annotation.
Process Reward Guided Tree Search
The process reward guided tree search, referred to as , employs a modified Monte Carlo Tree Search (MCTS) algorithm, strategically guided by a trained Process Reward Model (PRM). The core of this approach involves inferring per-step process rewards, which serve as value targets for training both the reward and policy models.
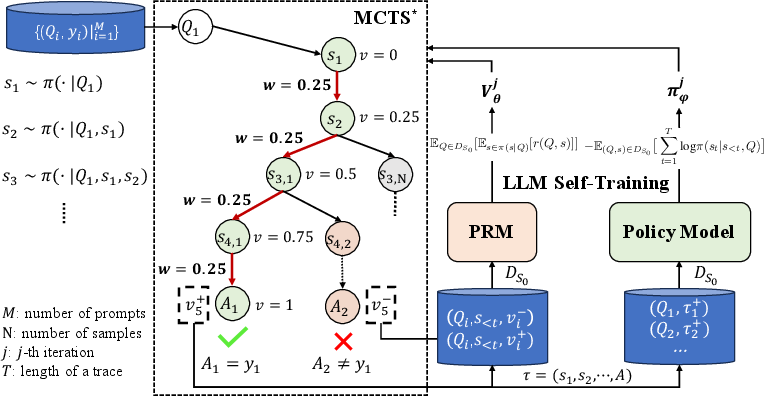 *Figure 1: The left part presents the process of inferring process rewards and how we conduct process reward guide tree-search. The right part denotes the self-training of both the process reward model and the policy model.
*Figure 1: The left part presents the process of inferring process rewards and how we conduct process reward guide tree-search. The right part denotes the self-training of both the process reward model and the policy model.
The tree search policy in ReST-MCTS* achieves improved accuracy compared to existing baselines like Best-of-N and Tree-of-Thought, utilizing the same search budget. By employing searched traces for training, the approach facilitates continuous enhancement of LLM performance across multiple iterations.
Implementation Details
Search Algorithm: The * algorithm comprises four main stages: node selection, thought expansion, greedy MC rollout, and value backpropagation. Node selection uses Upper Confidence Bounds for Trees (UCT) to balance exploration and exploitation. Thought expansion generates new solution steps by prompting the policy model. The rollout stage simulates a few steps to record the highest quality value observed. Finally, backpropagation updates node values based on children's values.
Value Model: The initial Process Reward Model (PRM) is trained to predict the quality value vk of partial solutions. The quality value captures both correctness and completeness of reasoning steps, guiding the tree search effectively.
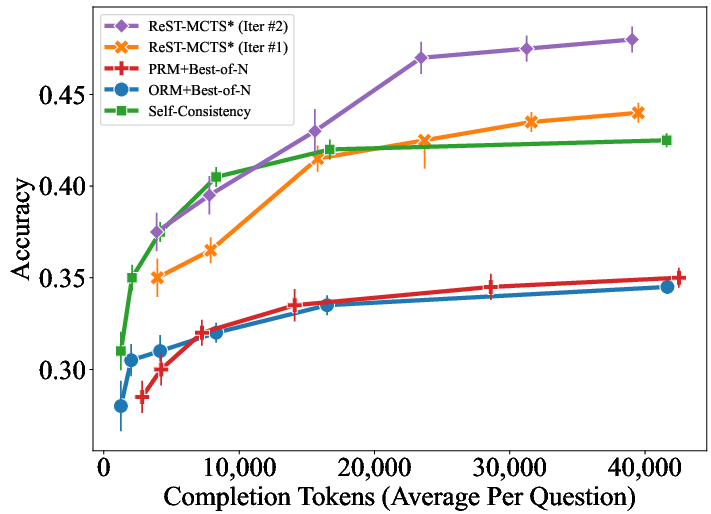
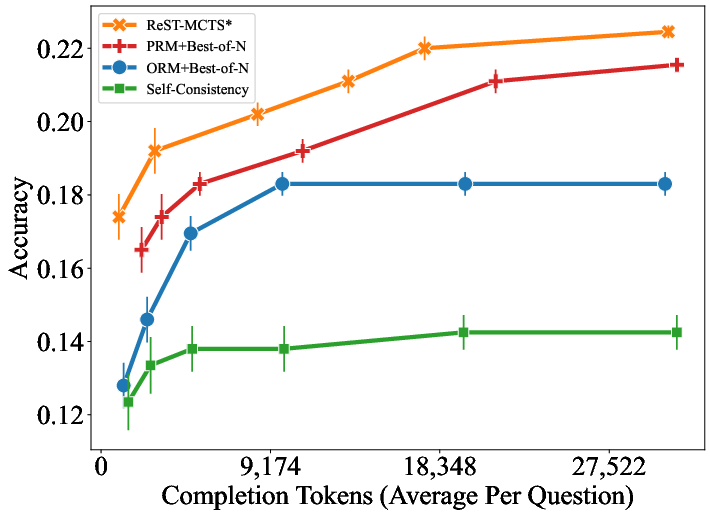
Figure 2: Self-training of value model on MATH.
Self-Training Pipeline
The self-training pipeline leverages the tree search algorithm to improve both policy and process reward models iteratively. This mutual self-training ensures that the value model can provide precise guidance for policy updates, and conversely, the refined policy improves the data used to train the reward model.
Data Generation and Reward Inference: The generation process involves conducting the tree search to produce a search tree, pruning unfinished branches, verifying trace correctness, and subsequently inferring rewards. The inferred process rewards serve to continuously refine the value model's predictive accuracy.
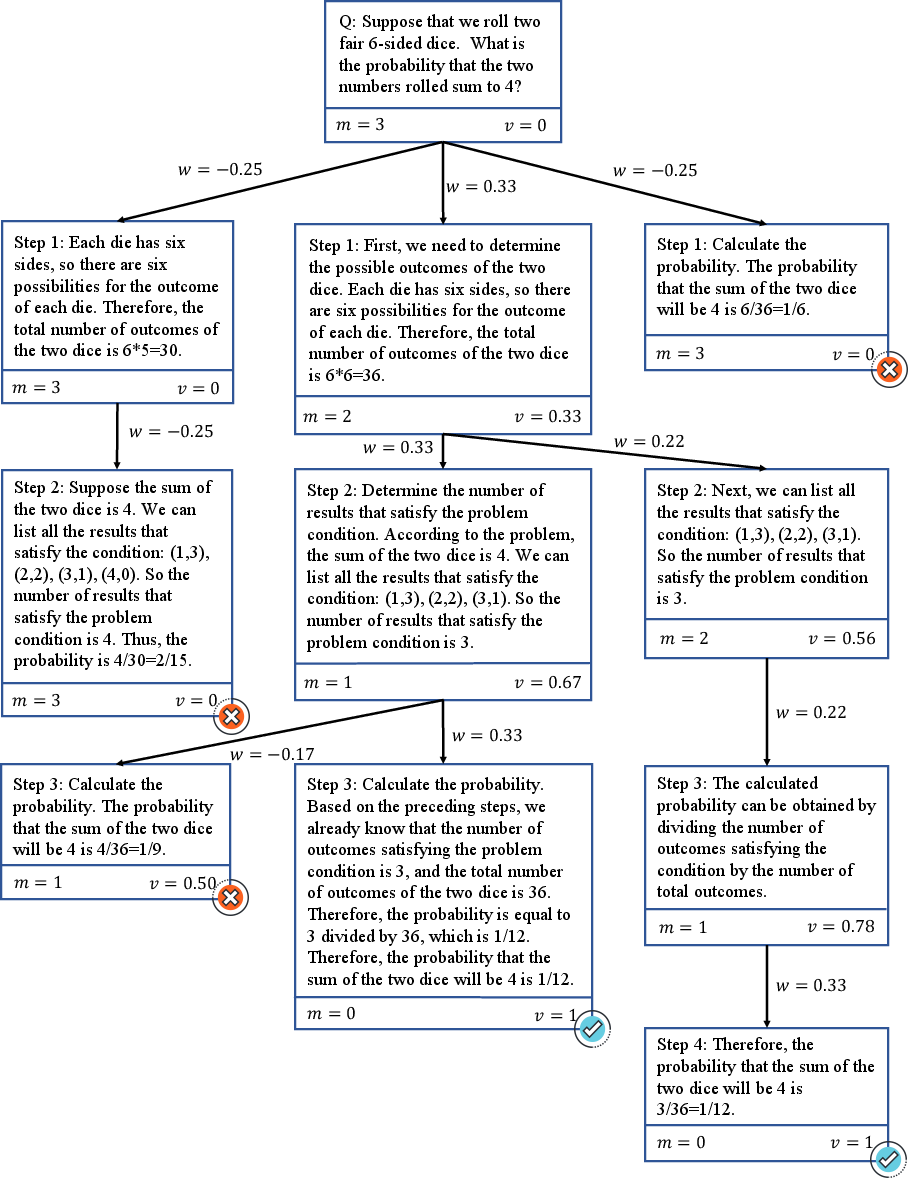
Figure 3: Detailed inferred process of a concrete example. The search tree has been pruned with traces verified, demonstrating step-by-step reward updates.
Improvements Over Baselines: The proposed framework demonstrates superior performance over existing self-training methods such as ReSTEM and Self-Rewarding. Experimentation on datasets like SciBench and MATH indicates that ReST-MCTS* can achieve notable improvements in accuracy under restricted search budgets.
Experiments and Results
The experimental validation shows that ReST-MCTS* substantially outperforms prior self-training approaches across various benchmarks. Iterative self-training yields continuous improvements in model accuracy, as evidenced in comparisons on both in-distribution and out-of-distribution datasets.
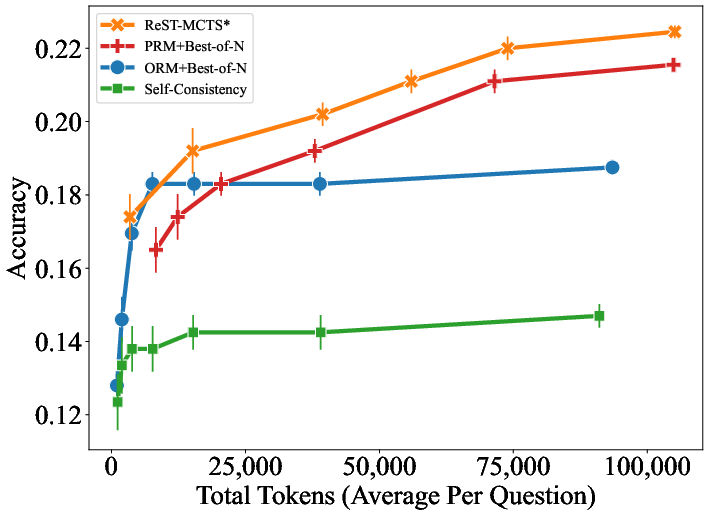
Figure 4: Accuracy of different methods on SciBench with varied total token usage per question.
Moreover, the results underscore the effectiveness of the inferred process rewards and the ability of the framework to refine reasoning trajectories efficiently, illustrating the feasibility of deploying ReST-MCTS* in diverse problem-solving scenarios.
Conclusion
ReST-MCTS* presents a robust framework for enhancing LLM reasoning through process reward guided tree search. By integrating inferred process rewards, the method not only refines policy models effectively but also fosters a more accurate reward model. While the current implementation focuses on math and logic-intensive tasks, future work will aim to extend these techniques to other domains, further exploring the potential of automated reward inference and process optimization in LLMs.