- The paper demonstrates that integrating Monte Carlo Tree Search for process supervision significantly refines LLM reasoning.
- The methodology involves iterative sampling of reasoning steps with scoring, weighted log-likelihood minimization, and a KL penalty to guide training.
- Experimental results on MATH and GSM8K highlight rapid convergence and cross-dataset improvements in model performance.
Enhancing Reasoning through Process Supervision with Monte Carlo Tree Search
Introduction
The paper "Enhancing Reasoning through Process Supervision with Monte Carlo Tree Search" investigates the improvement of reasoning capabilities in LLMs through process supervision rather than outcome supervision. The primary contribution of the work is the integration of Monte Carlo Tree Search (MCTS) to generate process supervision data for refining reasoning skills in LLMs. This research explores iteratively sampling reasoning steps using LLMs, assigning scores to each step to evaluate "relative correctness," and subsequently training the LLM by minimizing a weighted log-likelihood of these reasoning steps.
Methodology
The proposed method leverages MCTS to sample and search through step-by-step reasoning paths, constructing a training dataset of reasoning problems. The process involves four stages: Selection, Expansion, Simulation, and Backpropagation. The model assigns scores to each node in the reasoning path that reflect the relative correctness of the steps, using Eq. (1) from the paper. This score-based data is integrated into a weighted negative log-likelihood loss function, which, along with a KL penalty term, guides the training process.
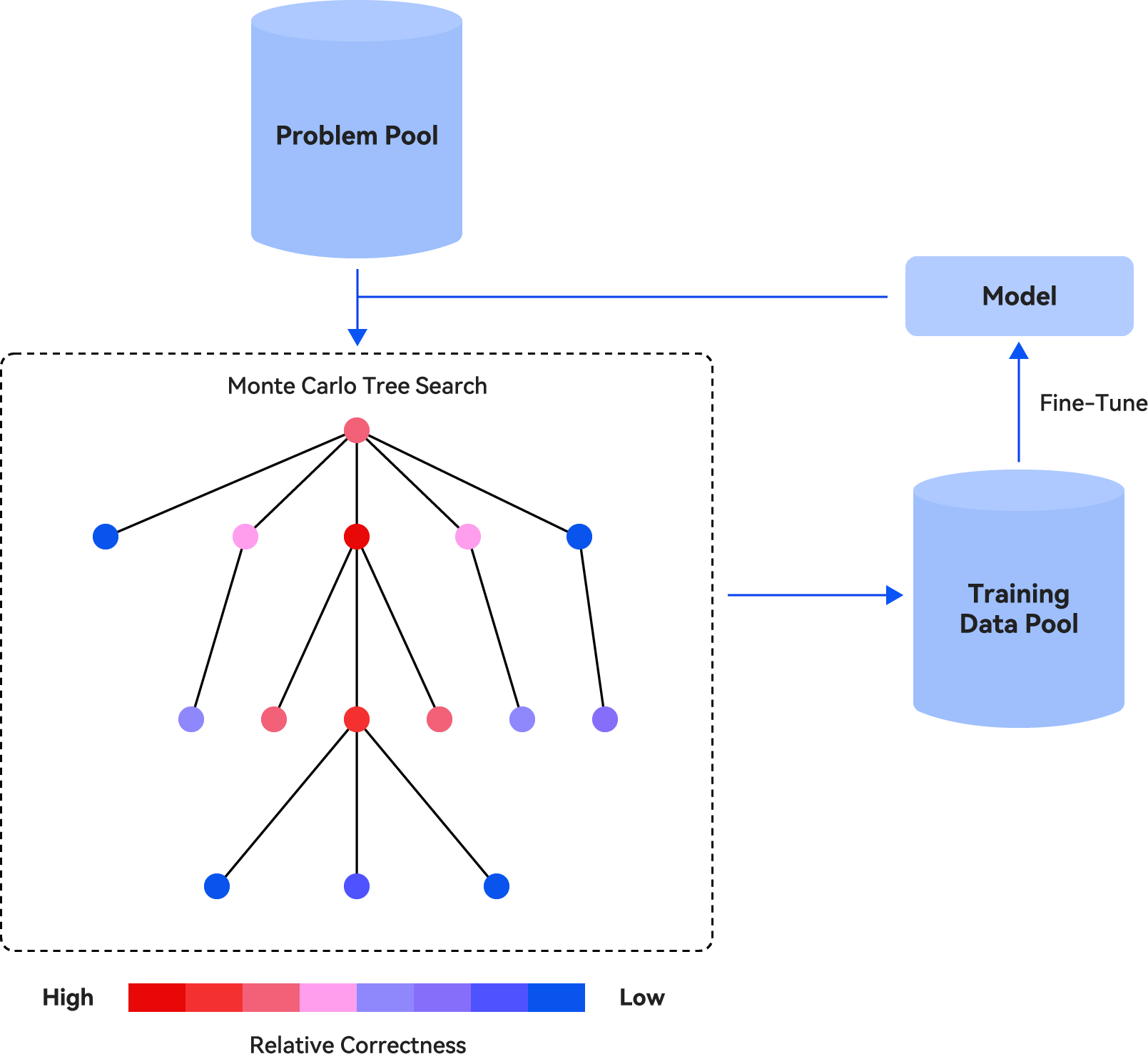
Figure 1: An overview of the proposed methods.
The iterative nature of the training ensures that with each cycle, the LLM becomes more adept at reasoning by continuously refining on previously generated data, starting from the pretrained LLM at the first iteration.
Experimental Setup and Results
Experiments are conducted using Llama-3.1-8B-Instruct and deepseek-math-7b-instruct on the MATH and GSM8K datasets. The evaluations compare the proposed approach against baselines such as Zero-shot-CoT and Rejection Sampling Fine-Tuning (RFT). The results indicate significant performance improvements with the proposed method consistently outperforming baselines. The iterative training showed rapid convergence, with noticeable accuracy gains on both datasets.
Transferability Evaluation
An additional experiment evaluated cross-dataset transfer capabilities, where models trained on one dataset exhibited improved performances on the other (e.g., models trained on GSM8K tested on MATH). The results confirmed that the models learned generalizable reasoning skills, albeit with lesser improvements than on the task-specific dataset.
Conclusion and Limitations
The integration of MCTS for generating process supervision data shows substantial efficacy in enhancing LLM reasoning abilities on mathematical datasets. However, limitations include the rapid convergence of the methodology that limits extensive iterative training. Additionally, models utilizing LoRA for training may have restricted the total improvements observed. Future work could explore methodologies for slowing convergence and evaluate alternative parameter-efficient fine-tuning methods.
This paper provides a robust framework for improving LLM reasoning with process supervision, opening avenues for further research into scalable reasoning improvement strategies in artificial intelligence.