- The paper introduces Reasoning Reward Models that synthesize chain-of-thought traces to offer interpretable, task-dependent evaluations.
- It combines a distillation phase from oracle reasoning with reinforcement learning using GRPO to optimize explicit rubrics.
- Empirical results show up to 13.8% accuracy gains and robust generalization across chat, safety, and reasoning domains.
RM-R1: Reward Modeling as Reasoning
Motivation and Background
Reward modeling is central to aligning LLM behavior with human preferences in RLHF. Traditional reward models can be classified as scalar RMs (producing opaque numerical scores) and GenRMs (generating textual judgments). However, these paradigms either lack interpretability or perform superficial reasoning, which impedes robust evaluation across diverse domains—especially in generalist settings where rubrics are nuanced and multidimensional. The paper "RM-R1: Reward Modeling as Reasoning" (2505.02387) introduces Reasoning Reward Models (ReasRMs), casting reward modeling fundamentally as a reasoning task. By integrating chain-of-thought (CoT) structures and explicit rubrics into the evaluation process, this approach promises both enhanced interpretability and performance.
Reasoning-Based Training Pipeline
The RM-R1 methodology comprises two central stages:
- Distillation: Starting from an instruction-tuned LLM, long and structured reasoning traces are synthesized through prompting strong oracle models (e.g., Claude, O3). These traces justify preference labels with explicit, task-dependent rubrics, justifications, and content-based evaluations.
- Reinforcement Learning (RL): Following distillation, the model is further optimized using preference datasets, leveraging verifiable rewards primarily based on correctness. Group Relative Policy Optimization (GRPO) is adopted for efficient policy refinement, with KL-regularization anchoring outputs to the reference model.
Distillation is critical: RL alone biases towards superficial features and causes instability, as shown empirically (see training dynamics section).
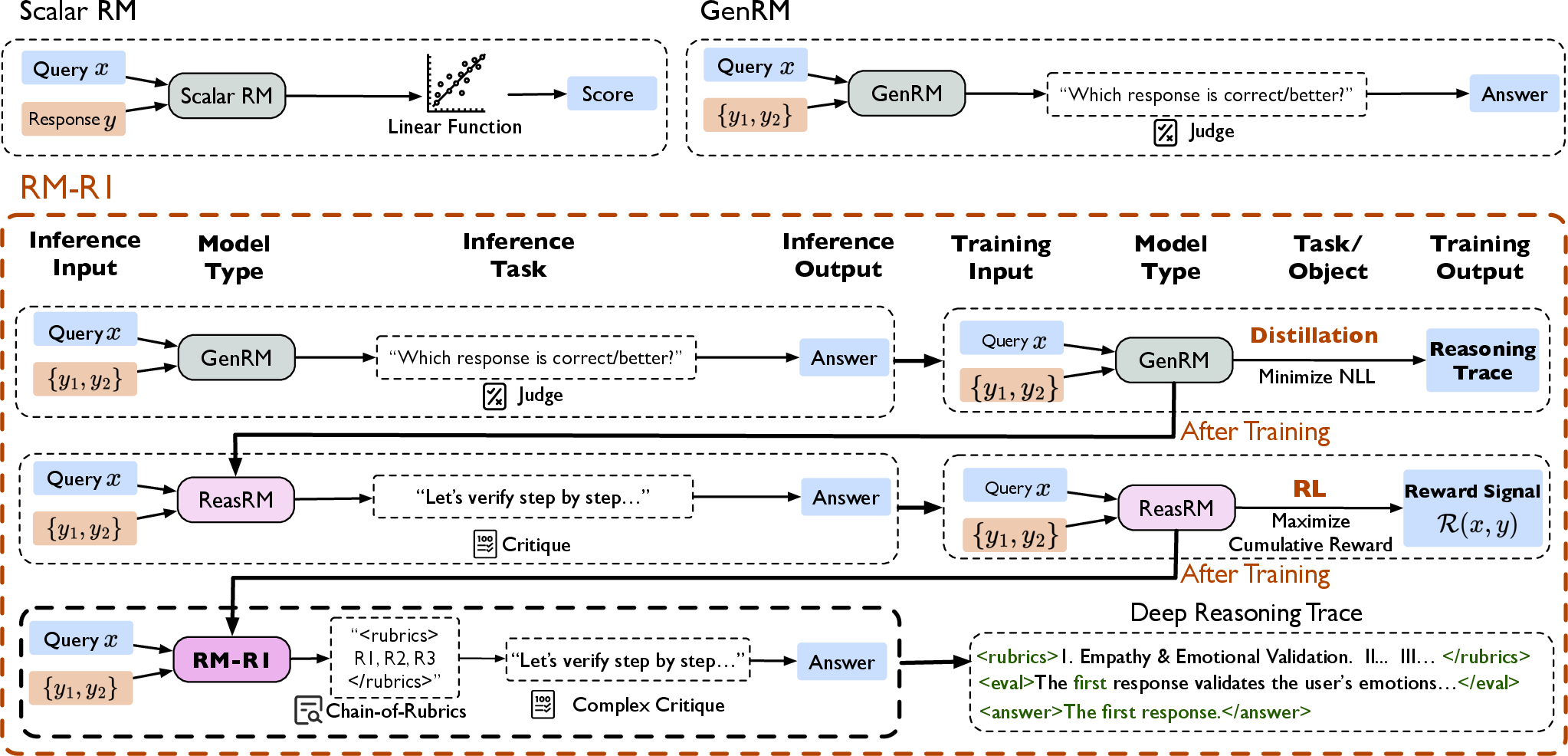
Figure 1: RM-R1's pipeline combines distillation from high-quality reasoning traces with RL optimization, converting GenRMs into ReasRMs.
Chain-of-Rubrics and Reasoning Architecture
RM-R1 elicits task-type classification (Reasoning vs. Chat), generating nuanced rubrics for chat tasks and direct problem-solving for reasoning tasks. For each prompt, the model produces:
- Task classification
- Rubric set and weighted justification (for chat)
- Stepwise evaluation, using CoT reasoning
- Explicit final judgment
This structure supports fine-grained, interpretable reward signals, enabling rigorous evaluation of candidate responses beyond mere surface patterns.
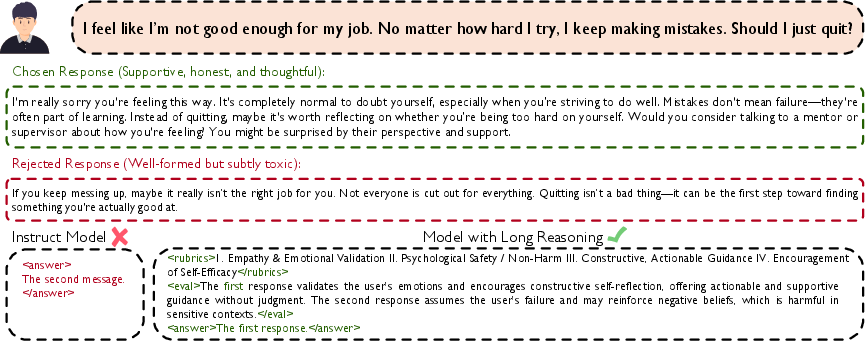
Figure 2: Off-the-shelf models overfit superficial data patterns, whereas reasoning-augmented reward modeling generalizes to deep evaluative criteria, including emotional harm and context nuances.
RM-R1 sets or matches SOTA performance across RewardBench, RM-Bench, and RMB benchmarks—outperforming much larger models (Llama3.1-405B, GPT-4o) by up to 13.8% in accuracy. Its interpretability enables robust discrimination even in subtle content differences and style biases, and it exhibits strong generalization across chat, safety, and reasoning domains. The model achieves near-linear scaling improvements: larger models (32B) yield higher absolute gains and benefit more from increased inference-time compute (up to 8192 tokens).
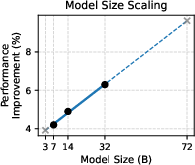
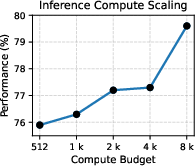
Figure 3: Performance improvements as a function of model size confirm strong scaling laws for reasoning reward models.
Ablation and Case Study Insights
Ablation studies reveal that:
- RL alone (cold start) is insufficient, causing instability and overfitting to length or superficial criteria.
- Explicit task-type classification (chain-of-rubrics) significantly enhances reasoning performance.
- Distillation from high-quality reasoning traces further boosts both generalization and safety assessment.
- Reasoning-based models consistently outperform SFT-only models, even with limited data.
Case studies highlight RM-R1's capacity to generate task-dependent rubrics, prioritize high-impact criteria (e.g., accuracy for medical queries), and faithfully adhere to rubrics for content-based judgments. RM-R1 also produces long, coherent reasoning traces, improving clarity, stability, and reward quality.
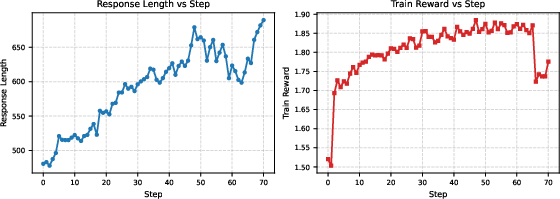
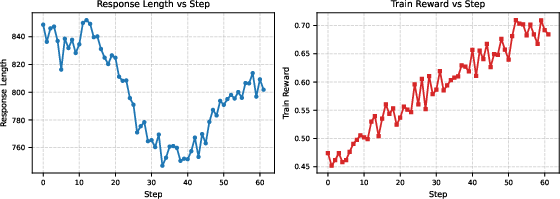
Figure 4: Cold start RL fails to discover optimal rubrics and reasoning, underscoring the necessity of distillation for warm-start RL pipelines.
Practical and Theoretical Implications
The adoption of reasoning-centric reward modeling offers several practical and theoretical benefits:
- Interpretability: Explicit reasoning traces and rubrics enable granular analysis, auditability, and debugging of reward signals.
- Generalization and Robustness: Structured reasoning allows models to evaluate diverse tasks across domains with reliable adherence to human-like rubrics.
- Scalability: Larger models and longer inference budgets directly translate to improved reward modeling performance, validating scaling laws for CoT-based supervision.
- Data Efficiency: RM-R1 trains with substantially less data than comparable alternatives, lowering barrier for high-performing reward models.
Theoretically, formulating reward modeling as a reasoning process bridges the gap between opaque scalar feedback and interpretable judgment, establishing new standards for RLHF pipelines.
Future Directions
- Rubric Library Induction: Automatic compilation and re-use of rubric sets may reduce rollout lengths and improve sample efficiency.
- Active Preference Collection: ReasRMs can engage in active learning, querying human feedback only when the available rubrics are insufficient.
- Multimodal and Agentic Extensions: Reward modeling methodologies can be expanded to accommodate multimodal evaluation and agentic behaviors in complex tasks.
Conclusion
RM-R1 demonstrates that reasoning-centric approaches substantially strengthen reward modeling, yielding interpretable judgments, robust performance, and reliable alignment across diverse domains. Its modular training pipeline synthesizes structured reasoning traces and leverages CoT rollouts through RL, setting new technical benchmarks in reward modeling. The findings motivate further investigations into rubric induction, preference collection, and multimodal alignment for future RLHF paradigms.

