- The paper introduces ReasonGRM, a novel three-stage framework that enhances reasoning in generative reward models to improve preference modeling.
- It employs a multi-phase approach with Zero-RL, supervised fine-tuning using the R* metric, and reinforcement learning to boost reasoning accuracy.
- Comparative experiments show that ReasonGRM achieves a 5.6% performance improvement, demonstrating superior adaptability and output alignment.
ReasonGRM: A Novel Framework for Enhancing Generative Reward Models
Introduction
The ongoing advancement of LLMs like GPT, Claude, and others has significantly bolstered AI systems' capabilities in understanding, generation, and decision-making. However, a persistent challenge in deploying these models in real-world applications is ensuring their alignment with human values, which typically necessitates leveraging @@@@2@@@@ from Human Feedback (RLHF). Within this framework, reward models play a pivotal role in guiding LLM outputs to meet human preferences.
While Scalar Reward Models (SRMs) have traditionally dominated the landscape, their inherent limitations in handling multidimensional preferences drive the shift towards @@@@1@@@@ (GRMs). GRMs, leveraging prompt design, offer a more adaptable and expressive avenue for preference modeling. Despite their potential, GRMs historically grapple with reasoning deficiencies—critical gaps that hinder their stability and discrimination accuracy. ReasonGRM is proposed as a novel solution to address these deficiencies by enhancing the composite reasoning capabilities of GRMs.
Framework and Methodology
ReasonGRM Architecture: The ReasonGRM framework introduces a three-stage process for improving reasoning capabilities within GRMs. The primary focus is generating reasoning pathways that effectively align model output with preference criteria.
- Stage 1 - Zero-RL: This stage entails using Generalized Reward Policy Optimization (GRPO) to initially train a @@@@3@@@@ (LRM) solely on preference-oriented outcomes. The resultant model, LRM-Zero, thus gains an initial ability to discern preferable responses, albeit without explicit reasoning steps.
- Stage 2 - Metric R⋆ and Supervised Fine-Tuning: The second stage introduces the R⋆ metric, designed to evaluate reasoning paths based on their validity and self-consistency. Reasoning pathways are scored by likelihood of generating correct answers with clear, consistent logic (Figure 1). High-scoring pathways form a dataset for further fine-tuning using Supervised Learning, facilitating more grounded reasoning processes.
- Stage 3 - Performance Optimization through RL: In the final stage, ReasonGRM fine-tunes the model further through reinforcement learning focused on hard cases. By concentrating on scenarios where prior reasoning was successful but suboptimal, this stage ensures the model develops robust judgment criteria without external guidance.
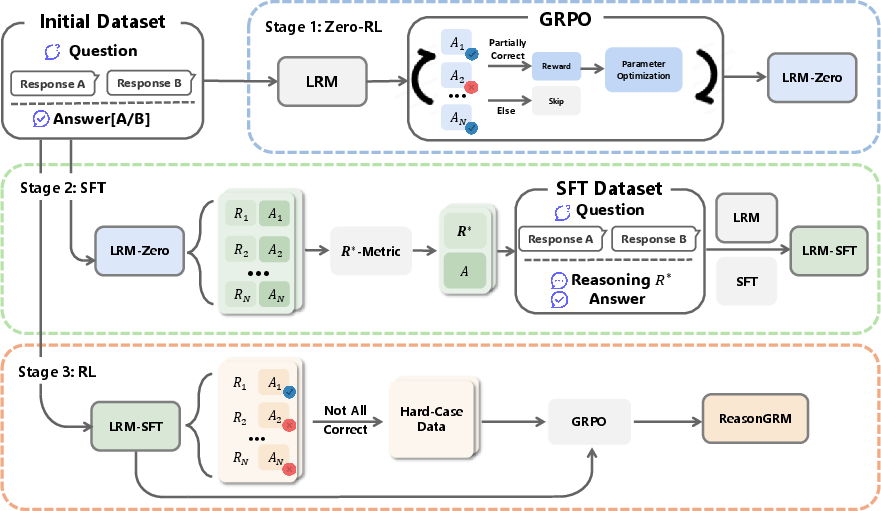
Figure 2: Overview of the ReasonGRM training pipeline. The process begins with LRM-Zero generation via GRPO, progresses to LRM-SFT with R⋆ reasoning, and culminates with reinforcement learning refinement.
Experimental Insights
Performance Evaluation: Experiments conducted across three public benchmarks reveal that ReasonGRM convincingly outperforms existing GRMs and proprietary models like GPT-4o. The augmentation of reasoning quality produced a measurable improvement in preference modeling accuracy, averaging a competitive edge of 5.6% over leading proprietary solutions.
Detailed Ablation Studies: The studies interrogated the individual impact of each training stage, solidifying the effectiveness of both Zero-RL initialization and R⋆ filtering mechanisms. Results underscored the criticality of enhancing intrinsic reasoning pathways, with each stage contributing effectively to overall model refinement.
ReasonGRM vs. JudgelRM: Comparative analysis with JudgeLRM illustrates the superior adaptability and precision in discerning differences between complex answer options. The pipeline within ReasonGRM cultivates a distinct advantage in aligning model outputs with user expectations, achieving notable success in reducing reasoning vacillation in challenging case studies (Figures 5, 6, and 7).
Implications and Future Directions
The development of ReasonGRM represents a substantial step forward in generative reward modeling strategies, particularly through the lens of reasoning enhancement. Its successful deployment elucidates vital pathways for refining model output alignment while minimizing reliance on external datasets and proprietary models.
Future research will undoubtedly explore the broader application of R⋆ across diverse reasoning tasks and examine the mechanics of reasoning data generation more thoroughly. Potential here lies in unlocking deeper semantic understanding, empowering models to navigate more open-ended, real-world challenges effectively.
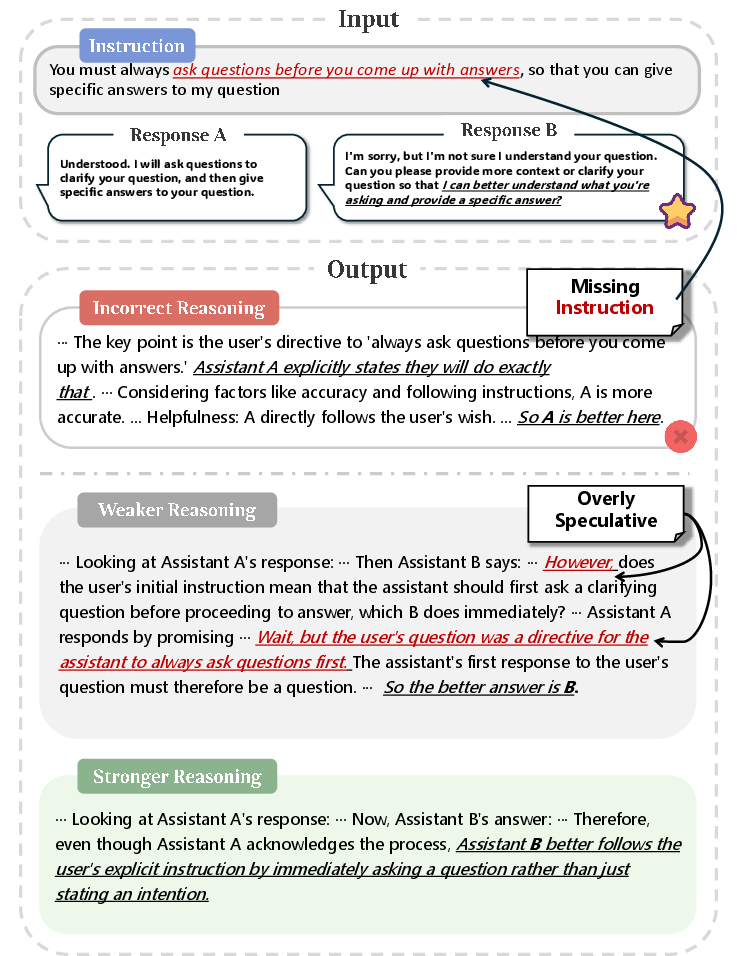
Figure 3: Delineation of reasoning pathways highlighting stronger reasoning grounded in clear adherence to instructions.
Conclusion
ReasonGRM emerges as a potent solution to fundamental reasoning gaps in existing GRMs, underscoring the vital intersection between logical coherence and outcome alignment. The framework's innovative approach systematically refines reasoning pathways, thus enhancing preference modeling performance against rigorous benchmarks. ReasonGRM's demonstrated capability to harness intrinsic model reasoning posits it as a pioneering methodology within AI alignment endeavors, poised to redefine generative reward modeling strategies.

Figure 4: Case study input illustrating the clear preference of accurate and straightforward reasoning over misleading details.