- The paper introduces batch-wise sum-to-zero regularization (BSR) to mitigate over-optimization in reward models during RLHF.
- It demonstrates that stabilizing hidden state norm dispersion significantly improves model generalizability across varied input distributions.
- Extensive experiments with models like Llama-3 and Qwen2.5 validate that BSR leads to more reliable alignment of AI systems with true human preferences.
On the Robustness of Reward Models for LLM Alignment
The paper "On the Robustness of Reward Models for LLM Alignment" addresses the issue of over-optimization in reward models (RMs) during reinforcement learning with human feedback (RLHF). It introduces a novel regularization method designed to enhance the robustness of RMs against unseen input distributions.
Introduction
Reward models are pivotal in RLHF as proxies for human preferences to align LLMs. Typically trained using the Bradley-Terry (BT) model, these models may suffer from over-optimization, causing poor generalization to new inputs. This work identifies the excessive dispersion in hidden state norms as a significant factor contributing to over-optimization.
Batch-Wise Sum-to-Zero Regularization (BSR)
The paper proposes batch-wise sum-to-zero regularization (BSR) as a mitigation strategy. BSR enforces that the sum of rewards within a batch is zero, which penalizes outliers with extreme magnitudes. This constraint theoretically limits the variance in hidden state norms that cause over-optimization.
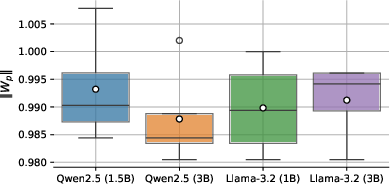
Figure 1: ||W_p|| distribution after reward modeling for four seeds each. ||W_p|| generally stays around one after the training.
BSR effectively maintains consistent hidden state norms across different evaluation scenarios, showcasing improved robustness compared to existing methods. The proposed method outperforms traditional approaches like simple BT, hinging on the insight that stabilizing hidden state norm dispersion is crucial for RM robustness.
Experiments
The study utilizes extensive experiments across various settings and model families, including Llama-3 and Qwen2.5 models, to verify the efficacy of BSR.
Reward Model Over-Optimization
BSR's benefits are validated through comprehensive over-optimization assessments across different distributions:
- BSR consistently outperforms baselines in unseen prompt and response generalization scenarios.
- Models trained with BSR demonstrate improved performance consistency and alignment with the true preference model.
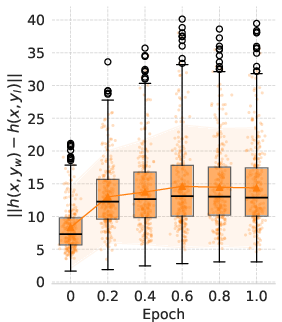
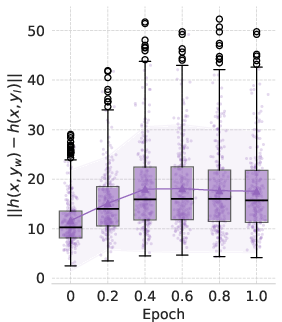
Figure 2: Qwen2.5 (3B) performance on various generalization tasks.
RLHF Training with RLOO
Applying the BSR-regularized RM within an RLHF framework (using Reinforcement Learning with Optimistic Objectives - RLOO), the method showed:
- Enhanced alignment of optimized policies with the true preference model.
- Stabilized reward maximization, reducing volatile training behaviors caused by over-confidence issues typically induced by unregularized training.
Practical Implications
The practical implications of this research are significant, as the ability to prevent over-optimization in reward models can lead to better-aligned, more generalizable AI systems. This improvement has the potential to enhance the reliability of AI feedback systems and mitigate alignment challenges.
Conclusion
The introduction of BSR marks a meaningful step toward tackling RM over-optimization, providing a robust method for enhancing model generalizability. This contribution is vital for the future of preference learning and LLM alignment, paving the way for more resilient AI systems.
In summary, the proposed batch-wise sum-to-zero regularization effectively addresses the challenge of reward model over-optimization in RLHF, ensuring better alignment and performance across a range of scenarios and models. This research provides valuable insights into the development of more robust AI feedback mechanisms.