- The paper introduces a novel conjugated distributional operator that enables DRL agents to train on unaltered rewards using the Cramér distance.
- The C2D algorithm extends the C51 framework by computing discrete distributions with variable supports, improving performance especially in high-variance environments.
- Extensive evaluations on 55 Atari games demonstrate state-of-the-art performance with convergence guarantees, highlighting areas for improvement in sparse reward settings.
Conjugated Discrete Distributions for Distributional Reinforcement Learning
The paper "Conjugated Discrete Distributions for Distributional Reinforcement Learning" (2112.07424) presents a novel approach in the field of distributional reinforcement learning (DRL). It introduces a new operator, the conjugated distributional operator, which allows agents to train on unaltered rewards utilizing a proper distributional metric, specifically the Cramér distance. The authors provide empirical evidence for the efficacy of their method through extensive evaluations in stochastic environments, particularly focusing on Atari 2600 games.
Introduction to Distributional Reinforcement Learning
Distributional reinforcement learning has emerged as a significant enhancement over traditional value-based reinforcement learning methods. Instead of learning the expected value of returns, DRL focuses on capturing the entire distribution of possible returns. This richer representation provides more insights into the uncertainty and variance associated with different actions, enabling more robust decision-making.
Transformations in reinforcement learning are employed to handle environments with varying reward magnitudes. Traditional methodologies, such as reward clipping or Q-function transformations, while effective, often do not maintain optimal policy invariance. This discrepancy highlights the need for a more sophisticated operator that can adapt to different settings without compromising the learning process.
Conjugated Distributional Operator
The paper addresses the limitations of existing transformation methods by introducing the conjugated distributional operator. This operator leverages a homeomorphism to transform random variables in a way that maintains policy invariance even in stochastic environments. The operator ensures that DRL can properly handle transformations, offering convergence guarantees that traditional value-based methods lack.
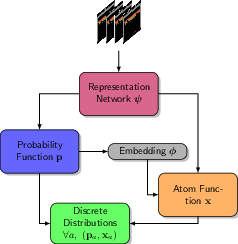
Figure 1: The functional model of C2D generates discrete distributions for all actions given an incoming state. A coupling effect between estimated probabilities p and atomic classes x is induced by a parameterized embedding.
Algorithm and Implementation
The introduced algorithm, dubbed Conjugated Discrete Distributions (C2D), builds upon the C51 algorithm’s framework. Unlike C51's fixed support and projection method, C2D employs discrete distributions with variable supports, using a network that outputs both the probabilities and locations of atoms. This allows the algorithm to minimize the distributional distance using the squared Cramér distance, which provides a more accurate measurement of differences between predicted and actual distributions.
The architecture of C2D is depicted in Figure 1, where a feature vector extracted from state inputs is used to calculate both the probability distribution over actions and the parameterized atom locations for the discrete distribution.
Evaluation on Atari Games
The paper thoroughly evaluates the performance of C2D using the Arcade Learning Environment, focusing on 55 Atari 2600 games to simulate stochastic MDPs via sticky actions. The Dopamine framework with specified hyperparameters was employed to ensure a fair comparison with other leading algorithms like C51, IQN, and Rainbow.
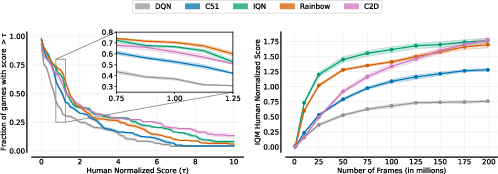
Figure 2: Accumulated statistics on 55 stochastic Atari games computed in accordance to the performance profiling methods given in \cite{agarwal2021deep}.
Results and Observations
The results showcase that C2D achieves state-of-the-art performance on par with or surpassing current leading algorithms. Particularly, C2D demonstrated superior performance in environments with frequent rewards of high variance, as shown in Figure 2. However, it was noted that C2D's performance in environments with sparse rewards and lower variance was less robust, highlighting a potential area for further enhancement.

Figure 3: Aggregate metrics on Atari-200M over 55 games. The metrics are computed in accordance to the performance profiling methods given in \cite{agarwal2021deep}.
The combined metrics in Figure 3 indicate that C2D consistently performs well on average across all games, with notable improvement in the mean scores and a comparable median to the best-performing distributional methods.
Conclusion
The paper introduces a significant advancement in DRL through the conjugated distributional operator, which facilitates training on unaltered rewards while maintaining theoretical guarantees of convergence. C2D’s competitive performance, particularly in high-variance environments, demonstrates its potential as a robust single-actor RL algorithm. Future work could explore integrating exploration strategies and additional enhancements from existing powerful algorithms to further bolster C2D's performance across a broader range of environments.