- The paper introduces SEM for MARL, reducing sample inefficiency and computational overhead by utilizing a single lookup table for state-based returns.
- SEM demonstrates superior performance compared to VDN and QMIX in SMAC benchmarks, showcasing its effectiveness in cooperative multi-agent tasks.
- The method provides a stable alternative to conventional target networks, mitigating overestimation and enhancing resource management in complex environments.
State-based Episodic Memory for Multi-Agent Reinforcement Learning
Introduction
The paper "State-based Episodic Memory for Multi-Agent Reinforcement Learning" (2110.09817) addresses the challenge of sample inefficiency in multi-agent reinforcement learning (MARL) by introducing a novel method termed State-based Episodic Memory (SEM). This method extends the concept of episodic memory (EM), already explored in single-agent settings, to multi-agent environments. The proposed approach is integrated within the Centralized Training with Decentralized Execution (CTDE) framework prevalent in MARL, with a focus on reducing the computational and storage complexities associated with traditional EM methods.
SEM Methodology
SEM utilizes a single lookup table to record the highest discounted returns correlated with global states, rather than joint actions. This state-centric approach significantly reduces the space and time complexities compared to State and Action based Episodic Memory (SAEM), which relies on action-specific tables. In SEM, the highest return for a given state is periodically updated, ensuring that the table reflects the most advantageous experiences encountered during training. This design is theorized to offer both space and computational benefits, thus making it feasible for larger MARL environments.
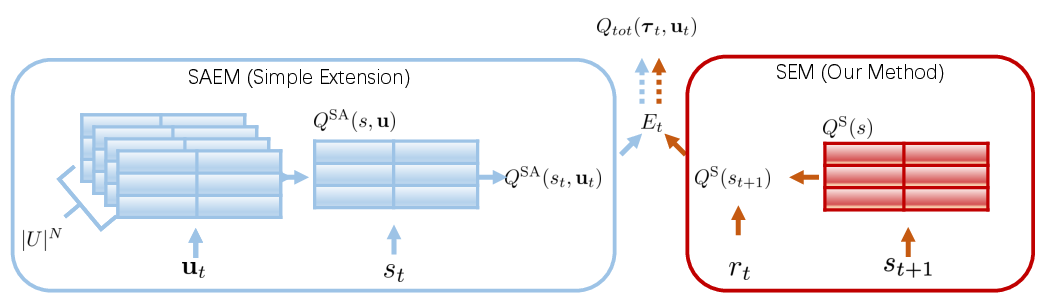
Figure 1: Comparison between SAEM architecture for MARL and SEM architecture. Best viewed in color.
Experimental Results on SMAC
The efficacy of SEM was validated using the StarCraft Multi-Agent Challenge (SMAC) environment, a benchmark for cooperative multi-agent tasks. SEM demonstrated notable improvements in sample efficiency and storage costs when compared against existing MARL algorithms such as VDN and QMIX. In particular, the SEM-augmented versions of these algorithms exhibited superior performance in various SMAC maps, highlighting the benefits of incorporating state-based episodic memory.
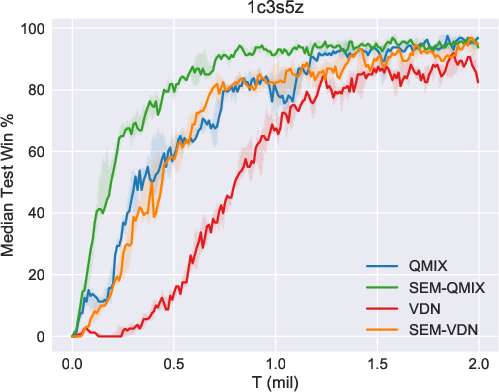
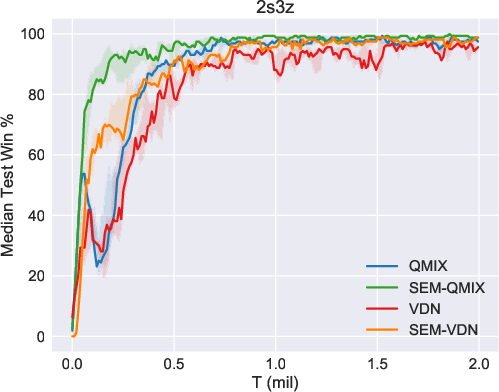
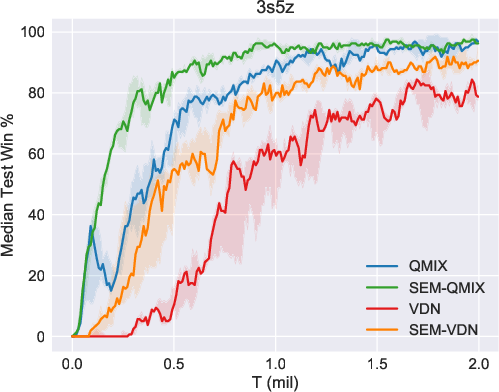
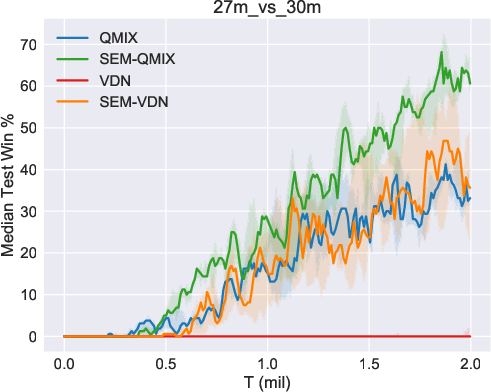
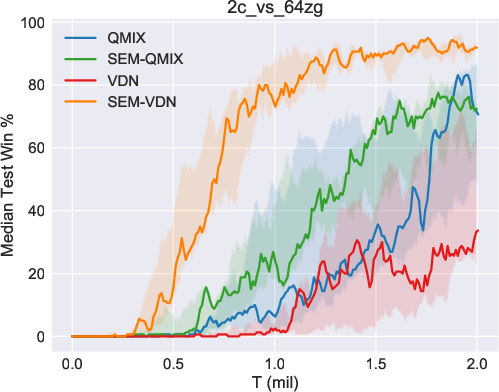
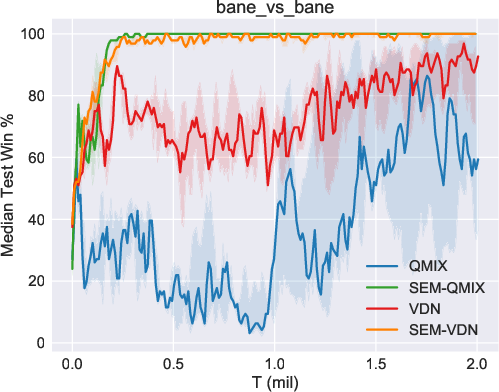
Figure 2: Results of our methods (SEM-VDN and SEM-QMIX) and baselines (VDN and QMIX), including the median performance as well as the 25-75\% percentiles.
Comparative Analysis and Insights
A core outcome of this research is the demonstration that episodic memory targets, specifically those derived from SEM, provide a stable and less overestimated alternative to conventional target networks used in MARL training. The contrast in target accuracy was evident when comparing the overestimation tendency in vanilla targets to the stability of episodic memory targets, as shown in the performance metrics across several tested scenarios.
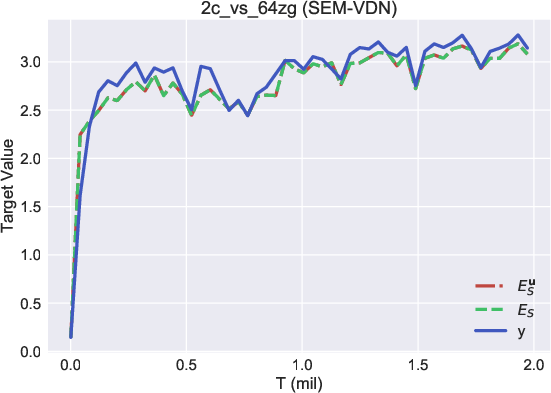
Figure 3: Comparison among different targets, Es,Esu, and y, in our methods and baselines.
Moreover, SEM outperformed the SAEM methodology in both computational efficiency and practical applicability, particularly in complex environments where the action space is significantly large. This performance gain is attributed to SEM's ability to minimize redundant computations associated with joint action spaces, which are computationally prohibitive in MARL settings.
Conclusion
The introduction of State-based Episodic Memory (SEM) marks a significant advancement in the field of multi-agent reinforcement learning, particularly in terms of sample efficiency and resource management. SEM's integration into existing MARL frameworks offers a scalable solution to some of the critical challenges facing reinforcement learning in multi-agent systems. Future research may explore further integration of episodic memory concepts with other reinforcement learning paradigms and the potential for improved generalization in diverse MARL environments.