- The paper introduces SRMT, a model that pools agents’ memories to enable decentralized coordination in multi-agent reinforcement learning tasks.
- It integrates self-attention and cross-attention modules to fuse individual observations with global context, significantly improving pathfinding performance.
- Experimental results show SRMT's superior generalization and scalability in lifelong MAPF, outperforming traditional MARL methods in sparse reward scenarios.
An Analysis of "SRMT: Shared Memory for Multi-agent Lifelong Pathfinding"
Introduction
The paper "SRMT: Shared Memory for Multi-agent Lifelong Pathfinding" (2501.13200) proposes the Shared Recurrent Memory Transformer (SRMT), a novel architecture aimed at improving coordination among agents in multi-agent reinforcement learning (MARL) settings. Unlike traditional methods requiring explicit communication protocols, SRMT facilitates implicit information exchange using shared memory, enhancing agents' ability to collaborate effectively in environments without centralized control.
The study builds upon existing transformer-based memory architectures, extending them into multi-agent settings. Previous approaches in MARL, such as MAMBA, QPLEX, and ATM, rely heavily on explicit communication or centralized training frameworks. In contrast, SRMT enables decentralized coordination by pooling individual agent memories into a globally accessible space, merging insights from cognitive theory with practical MARL applications.
SRMT Architecture
SRMT enhances the memory transformer architecture by integrating a shared memory mechanism, leveraging self-attention and cross-attention modules to process both individual and collective information. At each time step, agents access a pooled memory, which is subsequently updated based on their observations and actions. This setup allows agents to retain context and make informed decisions without explicit inter-agent communication.
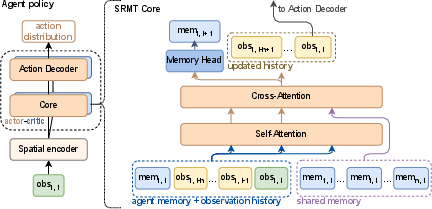
Figure 1: Shared Recurrent Memory Transformer architecture. SRMT pools recurrent memories memi,t of individual agents at a moment t and provides global access to them via cross-attention.
Experimental Evaluation
The SRMT model was evaluated using the POGEMA framework, focusing on both classical and lifelong multi-agent pathfinding (MAPF) tasks. In "Bottleneck" tasks, SRMT outperformed existing MARL and memory-based baselines, notably under sparse reward conditions where feedback was minimal. The architecture's ability to coordinate agent actions was crucial, particularly in environments requiring navigation through narrow corridors.
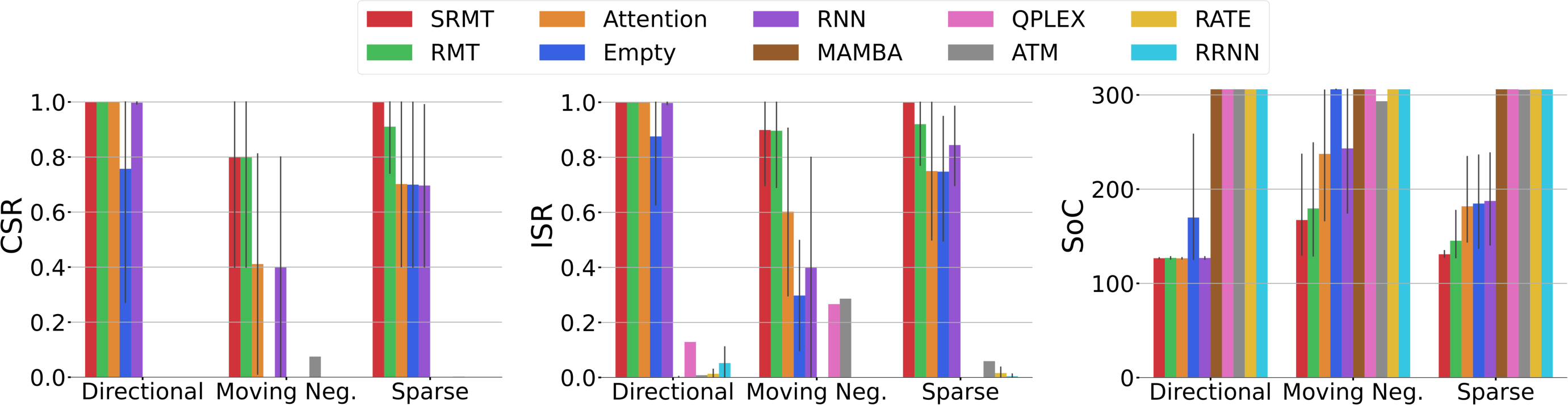
Figure 2: SRMT effectively solves the Bottleneck Task with different reward functions, showcasing superior performance under challenging conditions.
In lifelong MAPF scenarios, SRMT demonstrated robust generalization to unseen maps, outpacing traditional MARL baselines like MAMBA and QPLEX in terms of throughput and scalability. The incorporation of heuristic planning into SRMT further improved congestion management, implying that hybrid strategies combining learning-based and planning algorithms can significantly enhance performance in dense environments.
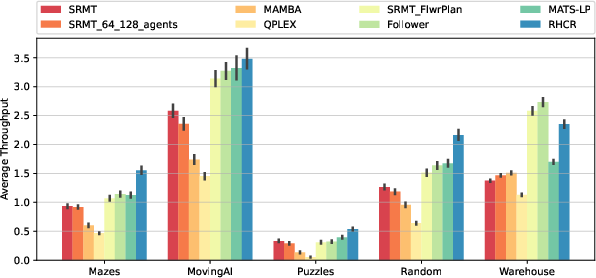
Figure 3: SRMT outperforms other MARL methods in different environments, showing robust generalization when evaluated on maps not seen during training.
Implications and Future Work
The SRMT presents a decentralized alternative to MARL challenges, capable of enhancing scalability and robustness in multi-agent systems. By abstracting inter-agent communication into a shared memory construct, SRMT reduces reliance on centralized coordination, facilitating deployment in real-world applications where such control is impractical. Future research might explore the integration of more sophisticated planning algorithms or extend the shared memory concept to additional MARL problem domains.
Conclusion
The introduction of SRMT marks a significant step in the evolution of multi-agent coordination strategies. By leveraging shared memory architectures, SRMT enhances the flexibility and scalability of MARL systems, paving the way for more efficient and adaptive solutions to complex pathfinding tasks. This research underscores the transformative potential of memory-augmented transformer networks in decentralized multi-agent environments, opening new avenues for theoretical exploration and practical application.