- The paper introduces LGC-MARL, which integrates reinforcement learning with LLM-based planning and graph-based coordination for multi-agent systems.
- The LLM planner and critic model generate and validate subtask graphs, ensuring accurate plan execution and effective reward function design.
- Experimental results in the AI2-THOR simulation show improved success rate, efficiency, and scalability compared to traditional MARL approaches.
Enhancing Multi-Agent Systems via Reinforcement Learning with LLM-based Planner and Graph-based Policy
The paper "Enhancing Multi-Agent Systems via Reinforcement Learning with LLM-based Planner and Graph-based Policy" explores the integration of Multi-Agent Reinforcement Learning (MARL) with LLMs to improve coordination and task execution in multi-agent systems (MAS). The proposed framework, LLM-based Graph Collaboration MARL (LGC-MARL), addresses the inherent challenges in MAS, such as coordination, safety, and dynamic task handling.
Overview of LGC-MARL Framework
LGC-MARL is designed to facilitate efficient collaboration in MAS by combining the cognitive capabilities of LLMs with graph-based policy coordination. The framework is composed of two primary components: an LLM planner and a graph-based collaboration meta-policy. The LLM planner breaks down complex tasks into executable subtasks and creates an action dependency graph that informs agent interactions. The graph-based meta-policy uses this graph to enable effective collaboration among agents through meta-learning.
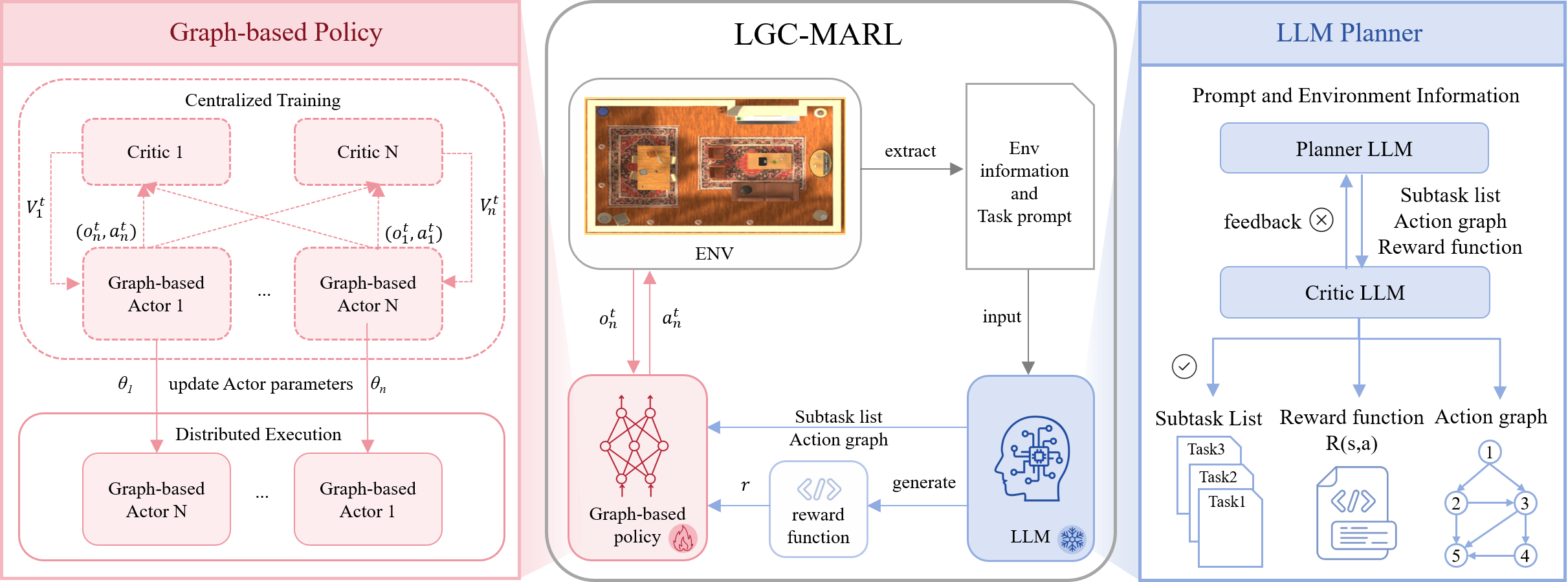
Figure 1: The illustration of the proposed framework.
LLM Planner and Critic Model
The LLM planner interprets task instructions and environmental context to formulate a sequence of subtasks and an action dependency graph. To enhance the accuracy of the generated plans, a critic model, also based on an LLM, evaluates the feasibility of these plans. The critic model detects and corrects factual errors, ensuring practical applicability and mitigating risks associated with LLM hallucinations.

Figure 2: Planner LLM and Critic LLM
Reward Function Generation and Graph-Based Policy
Crafting effective reward functions is crucial for MARL. LGC-MARL leverages an LLM-based reward function generator to create reward functions that enhance agent collaboration by considering both individual and collective objectives. The generator uses environment descriptions to produce modular reward functions, maintaining interpretability by documenting the reasoning process.
Simultaneously, the graph-based collaboration meta-policy employs the action dependency graph to coordinate agent actions. Utilizing meta-learning techniques, it allows rapid adaptation to new tasks while optimizing cooperative strategies across agents.
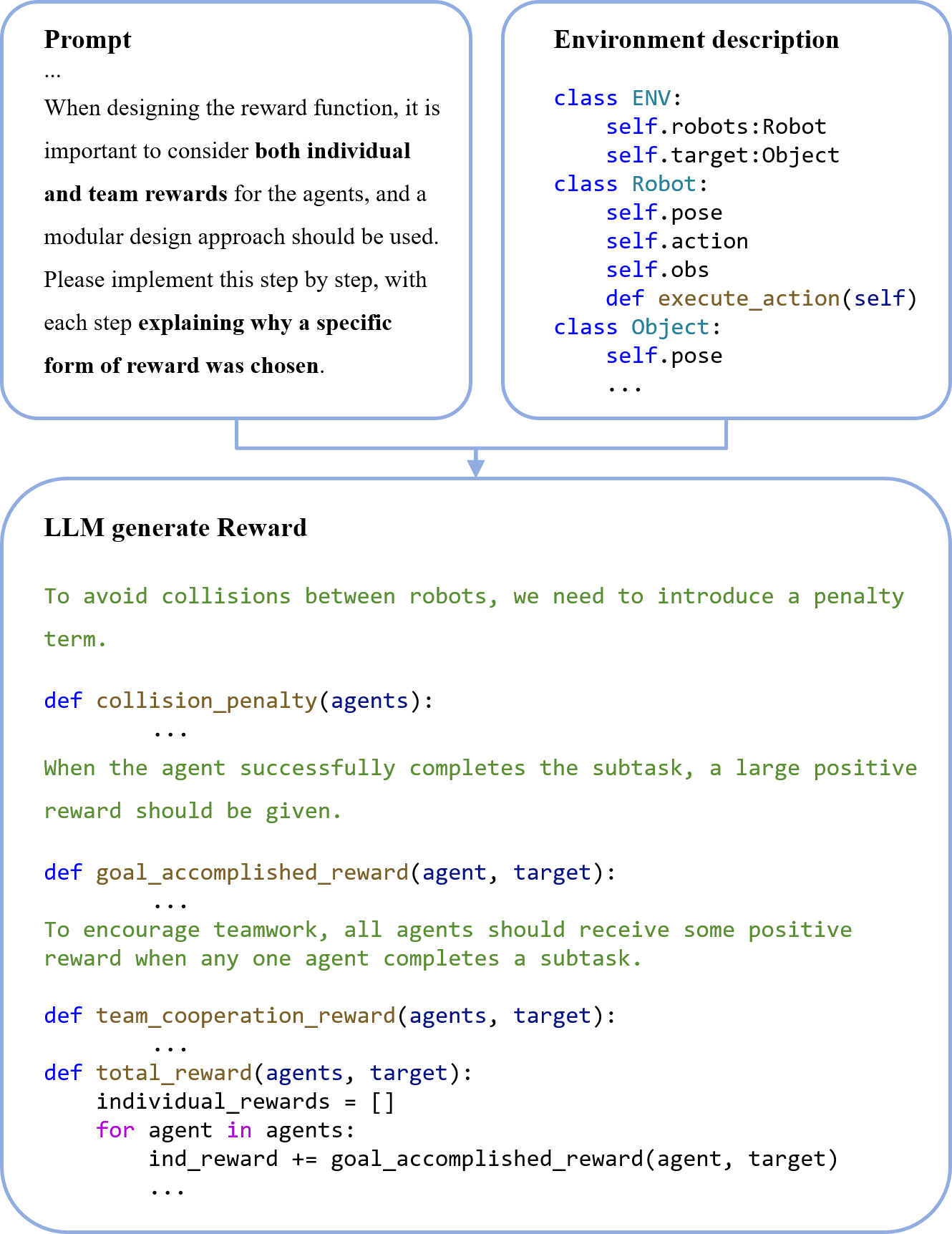
Figure 3: LLM-based reward function generator
Experimental Evaluation
Experiments conducted in the AI2-THOR simulation environment demonstrated that LGC-MARL surpasses traditional MARL and LLM-based methods in key metrics: Success Rate, Average Completion Time, and Normalized Token Cost. Results indicate that LGC-MARL maintains high task success rates with efficient resource use. The framework exhibited superior scalability and robustness, particularly as the number of agents increased.
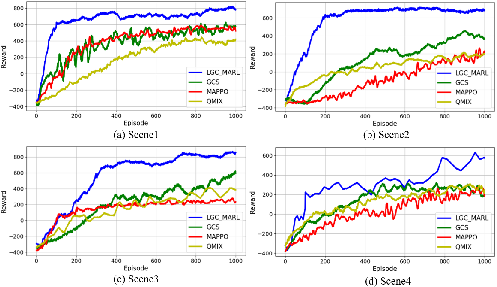
Figure 4: Comparison of different MARL algorithms
Scalability and Efficiency
A series of experiments assessed the impact of varying agent numbers on performance. Unlike centralized LLM and direct LLM dialogue methods, which showed declining performance with more agents, LGC-MARL maintained efficiency and success rates, highlighting its scalable nature.
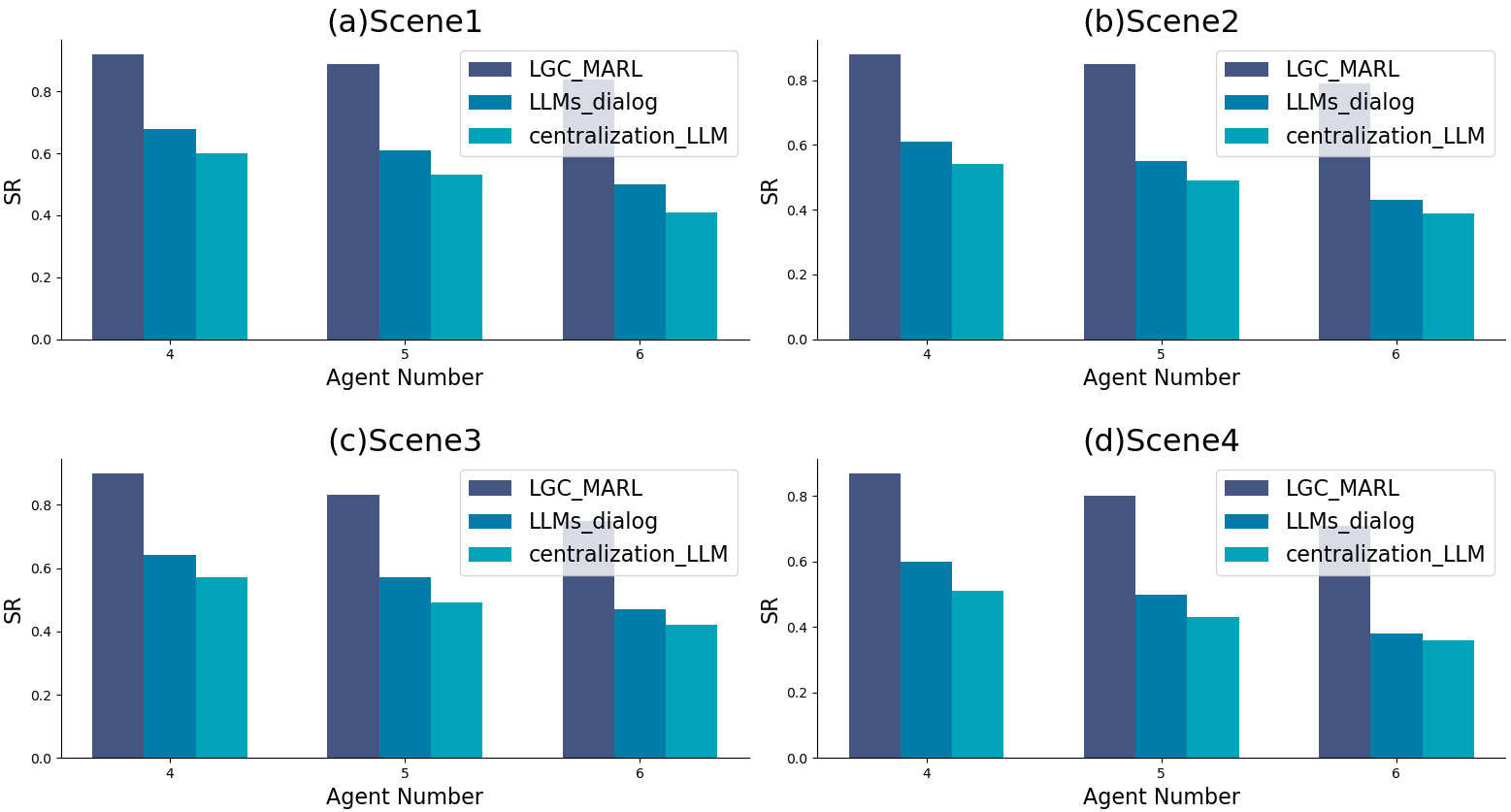
Figure 5: Comparison of different agent numbers
Conclusion
LGC-MARL represents a significant advancement in MAS by integrating LLM's cognitive abilities with MARL's strategic frameworks. The combination of LLM-generated task plans with graph-based policies achieves efficient collaboration and resource management. Future directions could explore further enhancements in LLM planning capabilities and applications in diverse, real-world MAS domains.