- The paper introduces a framework to evaluate multi-agent LLM systems with novel KPIs and coordination topologies.
- It demonstrates that graph structures and cognitive evolving planning enhance collaborative task performance by 3%.
- Results highlight implications for AGI development, showing how sophisticated coordination strategies improve agent efficiency.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents
Introduction
LLMs have displayed significant potential as autonomous agents capable of collaboration and competition in multi-agent scenarios. While most evaluations of LLM systems focus on single-agent tasks or constrained domains, these existing benchmarks fail to address the complexities inherent in interactions among multiple agents. MultiAgentBench is introduced as a comprehensive benchmarking framework designed to assess the functionality and efficacy of LLM-based multi-agent systems across diverse interactive scenarios. This framework emphasizes not only task completion but also interaction dynamics, encompassing both collaborative and competitive aspects within these systems.
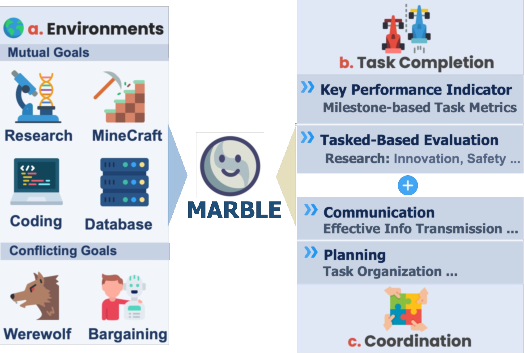
Figure 1: Overview of MultiAgentBench evaluation process: Multi-Agent System Coordination in various interactive environments, with a focus on task performance, and coordination.
MultiAgentBench Framework
The MultiAgentBench framework evaluates various coordination protocols such as star, chain, tree, and graph topologies. It also explores innovative strategies like cognitive planning and group discussions to optimize task-solving in complex environments. This benchmarking framework employs novel metrics, including milestone-based Key Performance Indicators (KPIs), to systematically assess planning quality, communication effectiveness, and competitive dynamics within multi-agent systems.
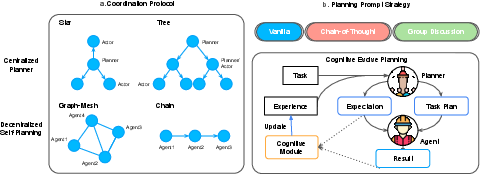
Figure 2: Illustration of coordination protocols and planning prompt strategies. (a) shows centralized and decentralized planning structures (e.g., star, tree, graph, and chain). (b) describes strategies like group discussions and cognitive prompts, incorporating iterative feedback and task updates for effective planning.
Methodology
The core methodology of MultiAgentBench involves evaluating LLM-based agents within a structured framework that tracks milestone achievements and analyzes interactions. Key components of this evaluation include cognitive modules for agent reasoning, a coordination engine for managing dynamic task execution, and memory modules that allow for adaptive learning and strategic planning by the agents.
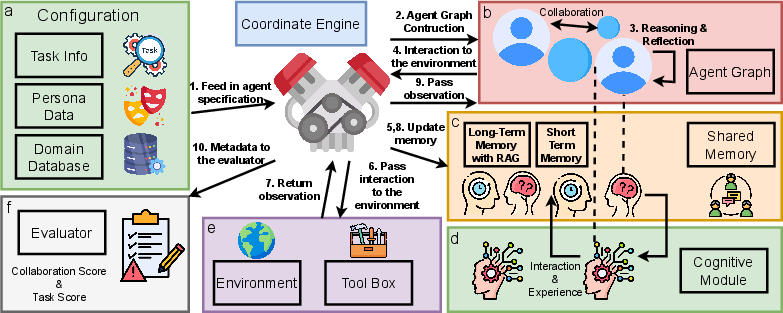
Figure 3: MARBLE -3.7pt: showcasing interactions between task information, persona data, domain databases, memory modules, and the environment through the coordinate engine and cognitive module.
Evaluation and Results
MultiAgentBench provides a rigorous analysis of coordination protocols, demonstrating that a graph structure excels in fostering collaborative efforts among LLM agents. In terms of planning strategies, cognitive evolving planning significantly enhances coordination, with LLM agents achieving milestone completion rates increased by three percent compared to traditional prompting methods.
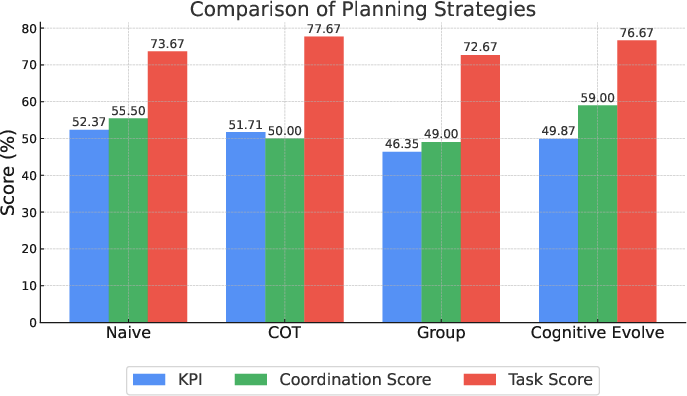
Figure 4: Average Metrics for Research Tasks for different planning prompt strategies. Cognitive Evolve Planning show best result in CS.
Implications for AI Development
The implications of this research are profound for the future development of AI systems, particularly in the field of artificial general intelligence (AGI). By identifying effective coordination strategies and mechanisms for multi-agent collaboration and competition, MultiAgentBench provides insights into emergent social behaviors observed in LLM-based systems. Such behaviors offer promising pathways toward creating more sophisticated, intelligent collaboration frameworks that mirror AGI-level capabilities.
Conclusion
MultiAgentBench represents a significant advancement in the evaluation of LLM-based multi-agent systems, offering a structured approach to analyze both collaborative and competitive interactions. By introducing novel metrics and coordination protocols, this framework provides valuable insights toward understanding and enhancing the capabilities of LLMs in complex multi-agent environments. The demonstrated emergent behaviors are indicative of the progress toward AGI-level collaborations, although further exploration and refinement are necessary. Future developments can extend this benchmark to even more diverse scenarios, ensuring comprehensive insight into the evolving capabilities of AI agents.