- The paper introduces CREW-WILDFIRE, an open-source benchmark evaluating LLM-based multi-agent collaborations using procedurally generated wildfire simulations.
- It employs heterogeneous agents such as firefighters, drones, bulldozers, and helicopters across 12 test levels to assess coordination, task delegation, and adaptive planning.
- Results show that while existing frameworks perform well on simpler tasks, they struggle with complex, dynamic scenarios that demand improved communication and decentralized planning.
CREW-WILDFIRE: Benchmarking Agentic Multi-Agent Collaborations at Scale
Introduction
The paper introduces CREW-WILDFIRE, an open-source benchmark specifically crafted to evaluate large-scale, LLM-based multi-agent systems. This benchmark addresses critical gaps in existing evaluations, which often emphasize smaller and less complex domains. The CREW-WILDFIRE environment features procedurally generated wildfire response scenarios, incorporating heterogeneous agents, partial observability, stochastic dynamics, and long-horizon planning objectives. The study highlights significant performance gaps in current state-of-the-art frameworks, underscoring challenges in coordination, communication, and planning in dynamically complex environments.
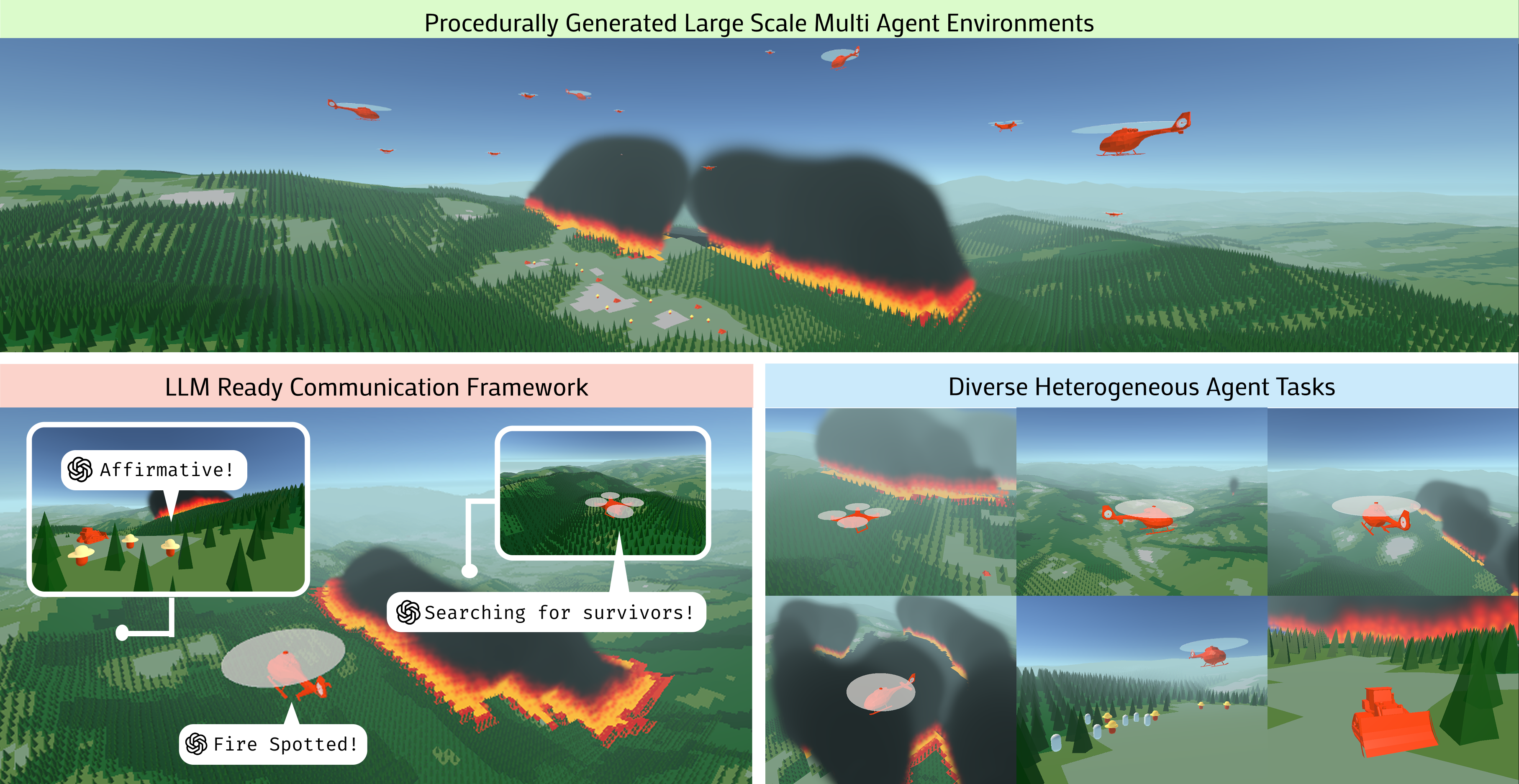
Figure 1: Features procedurally generated environments, an LLM-compatible multi-agent framework, and heterogeneous agents designed to evaluate Agentic collaborations at scale.
Environment Design
The CREW-WILDFIRE environment leverages the CREW platform, providing a procedural generation of realistic wildfire scenarios. This includes varying terrain features generated via Perlin noise and detailed wildfire simulations using cellular automata models. The environment supports flexible interfacing with LLMs for both low-level control and high-level reasoning.
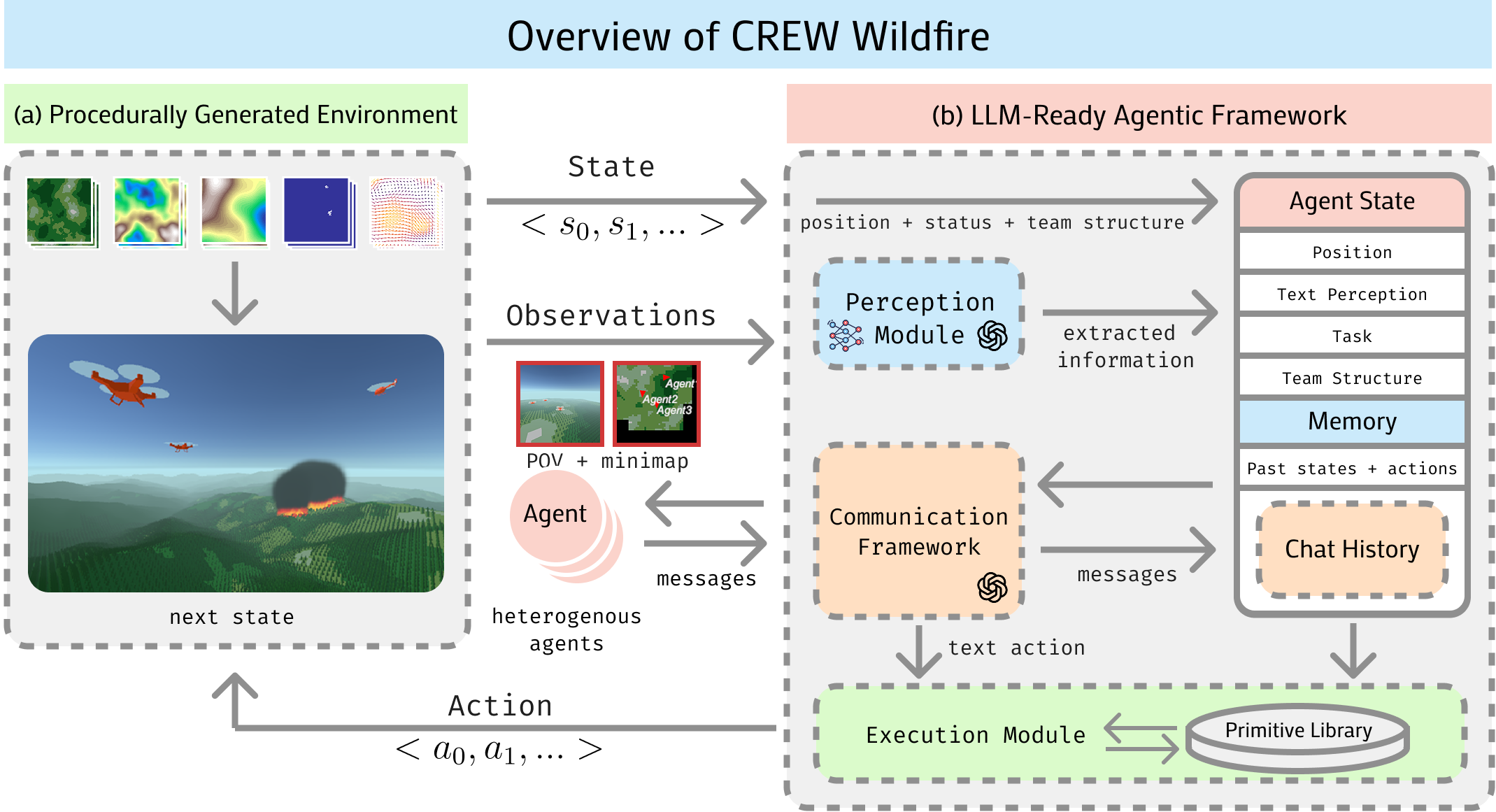
Figure 2: An overview of the CREW Wildfire Framework.
Heterogeneous Agents
The benchmark includes four types of agents: Firefighters, Bulldozers, Drones, and Helicopters, each with distinct capabilities requiring cooperative strategies. These roles mimic real-world fire crew specializations, demanding inter-agent dependencies that make coordination challenging.

Figure 3: The Four Heterogenous Agent Types: Firefighters, Bulldozers, Drones, and Helicopters.
Benchmarking Suite
The evaluation suite introduces 12 levels, each designed to test different competencies through diverse objectives. These levels vary in complexity, team composition, and task difficulty, providing a comprehensive testbed for assessing coordination, spatial reasoning, task delegation, and adaptability.
The suite also establishes a set of behavioral goals, such as Task Designation and Plan Adaptation, to diagnose conceptual challenges rather than relying solely on scoring.
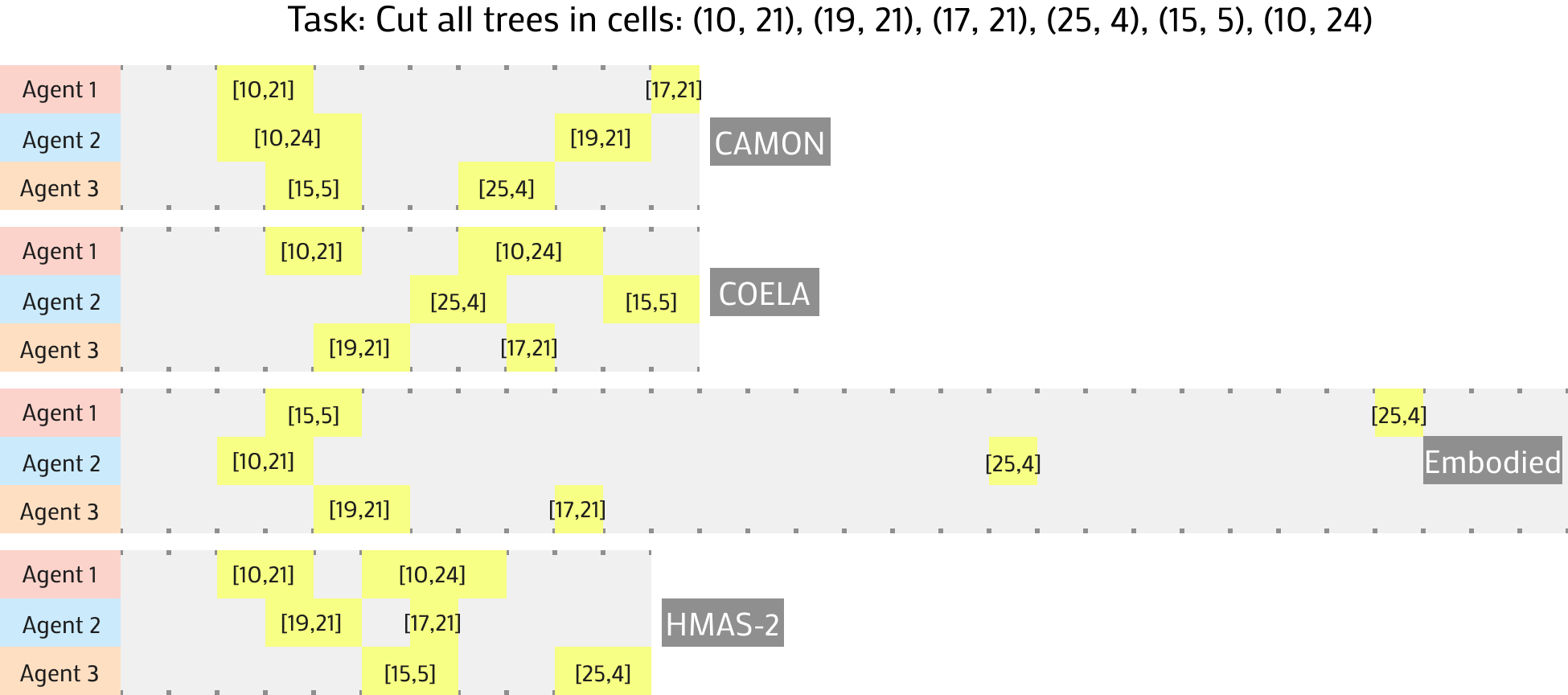
Figure 4: Sample Multi-Agent Trajectories for the Cut Trees: Sparse(small) level. Each highlighted section represents the correct tree being cut by that agent.
Results and Analysis
The experimental results demonstrate that current frameworks excel in simplified tasks but struggle with larger, dynamic, and complex scenarios. Frameworks such as CAMON showed effective task designation but failed in decomposing and adapting plans in more intricate scenarios.
The analysis of communication efficiencies revealed significant scaling challenges, where token usage increases linearly with agent count, indicating the need for decentralized or hierarchical communication architectures.
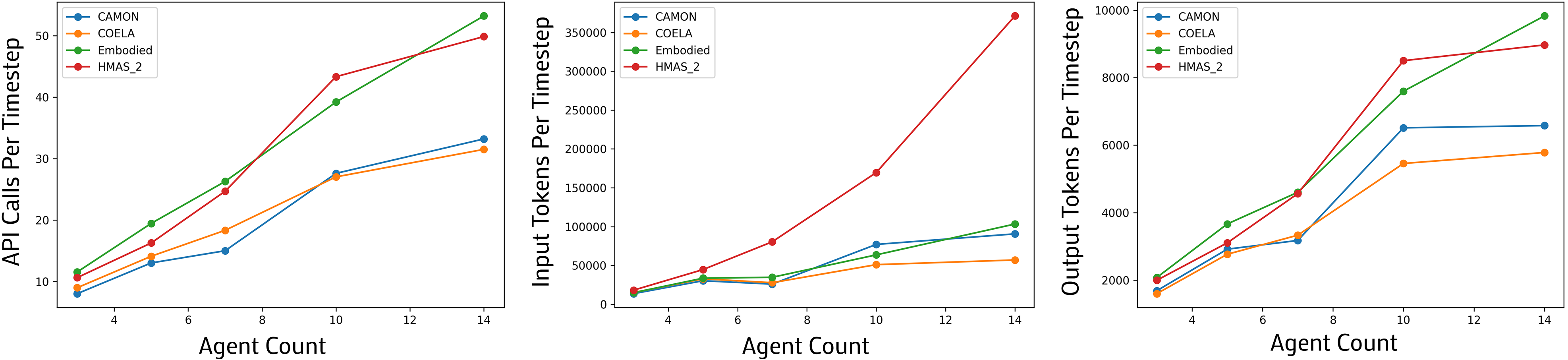
Figure 5: API calls, input tokens, and output tokens per timestep across agent counts.
Behavioral Competency
By introducing the Behavior-Competency Score (BCS), the paper evaluates the frameworks on task-related behaviors. While frameworks demonstrate strengths in Realtime Coordination and Task Designation, gaps remain in Observation Sharing and Plan Adaptation. This metric provides more granular insights into behavioral competencies by associating specific actions with high-level goals.
Conclusions
CREW-WILDFIRE provides a crucial platform for challenging current LLM-based multi-agent approaches, emphasizing real-world complexity and scalability. By identifying clear performance and competency gaps, the benchmark sets the stage for developing more robust, scalable, and adaptable multi-agent systems.
The release of the benchmark and associated tools is intended to foster advancements in LLM-based multi-agent systems, pushing the boundaries of current capabilities and setting a new standard for future research. This benchmark not only aids in performance evaluation but also serves as a foundation for further exploration of agent coordination, strategic planning, and adaptive behaviors in large-scale scenarios.