AWorld: Orchestrating the Training Recipe for Agentic AI
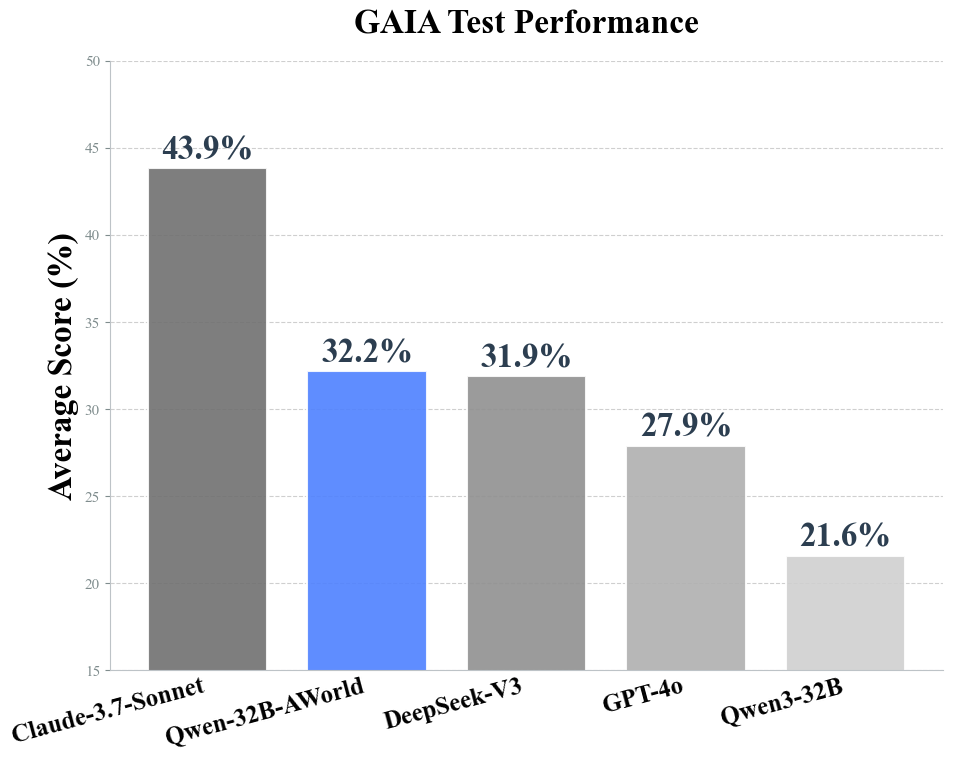
Abstract: The learning from practice paradigm is crucial for developing capable Agentic AI systems, yet it is severely hampered by inefficient experience generation, a bottleneck especially pronounced in complex benchmarks like GAIA. To address this, we introduce AWorld, an open-source system engineered for large-scale agent-environment interaction. By distributing tasks across a cluster, AWorld accelerates experience collection by 14.6x compared to standard single-node, sequential execution. This critical speedup makes extensive reinforcement learning practical and scalable. Leveraging this capability, we trained a Qwen3-32B-based agent that significantly outperforms its base model, increasing its overall GAIA accuracy from 21.59% to 32.23%. On the benchmark's most challenging levels, our agent achieves a score of 16.33%, surpassing the performance of leading proprietary models. Our open-source system and resulting agent provide a practical blueprint for a complete agentic AI training pipeline, from efficient interaction to demonstrable model improvement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Generalizability beyond GAIA: Evaluate AWorld across diverse, realistic agentic environments (e.g., WebArena, OSWorld, web shopping, coding agents) and report cross-domain performance and failure characteristics.
- Multi-agent capabilities: The framework supports inter-agent communication, but there are no multi-agent experiments; quantify collaboration benefits, scalability, role assignment, and coordination protocols under varying team sizes and topologies.
- Reward design limitations: RL uses a binary exact-match reward; investigate process rewards, partial credit, reward shaping, learned evaluators (RLAIF), and robustness to noisy or incomplete ground-truth.
- Absence of learning curves and sample efficiency: Provide learning curves versus number of trajectories/updates; measure sample efficiency (success per rollout) and data-efficiency gains attributable to AWorld.
- SFT vs RL contribution: Ablate the relative impact of the 886-trajectory SFT warm-start versus subsequent RL; quantify the minimal SFT needed and its interaction with rollout scale.
- Adaptive rollout allocation: Study dynamic rollout budgets per task (e.g., bandit or uncertainty-based allocation) instead of fixed 32 rollouts; quantify cost-benefit and diminishing returns.
- Baseline fairness and alternatives: The single-node baseline is sequential; compare against optimized single-node parallel/asynchronous executors, Ray-based runners, or other distributed rollout frameworks to isolate AWorld’s architectural advantages.
- Scaling limits and curves: Report throughput/concurrency scaling with cluster size (pods, GPUs, CPUs), network bandwidth, and inference server capacity; identify bottlenecks (trace server, storage, scheduler) and Amdahl’s/Gustafson’s limits.
- Failure modes and reproducibility: Characterize tool/environment failures, timeouts, non-determinism, and state drift; implement deterministic replay, checkpointing, and fault injection tests with quantitative reliability metrics.
- Cost, energy, and carbon footprint: Provide compute hours, dollar costs, and energy usage per point of improvement to assess practical viability and efficiency; compare to alternative training recipes.
- Safety, security, and compliance: Evaluate sandbox isolation, tool permissioning, data exfiltration risks, web interaction ethics/ToS compliance, and red-teaming; define and measure safety guardrails.
- Data curation transparency: The SFT dataset (886 trajectories) curated via Claude is not described in detail; release or document selection criteria, domain coverage, potential GAIA leakage/overlap, bias, and licensing constraints.
- Tool use analytics: Analyze per-tool usage, latency, error rates, and contribution to success; perform ablations on tool availability and tool-selection policies to identify high-impact integrations.
- Algorithmic details and stability: Report GRPO hyperparameters, advantage estimation, variance reduction, on-/off-policy considerations, policy lag in distributed updates, and convergence diagnostics under long horizons.
- Exact-match evaluation risks: GAIA correctness via exact match may penalize semantically correct but differently formatted answers; add tolerant/semantic evaluation and human assessment for borderline cases.
- Test contamination and splits: Clarify training/evaluation splits on GAIA (val vs test) to avoid leakage; quantify statistical significance and uncertainty (confidence intervals) given the small test size (165 questions).
- Generalization beyond search tasks: xbench-DeepSearch results suggest generalization, but broader out-of-domain tests (code reasoning, math, multimodal tasks) are missing; design systematic cross-domain evaluation.
- Long-horizon credit assignment: Explore hierarchical RL, options/skills, memory mechanisms, and reflection to improve credit assignment over extended trajectories; compare to flat policy gradients.
- Latency–throughput trade-offs: Detail vLLM batching, scheduling policies, and Kubernetes autoscaling; quantify pipeline stalls and end-to-end latency vs throughput trade-offs under varied load.
- Multi-modality training: Tools include image/audio servers, but multimodal RL training and evaluation are not reported; assess VLM integration and performance on multimodal GAIA items.
- Agent memory and retrieval: The framework mentions memory/context assembly, but there is no evaluation of persistent memory, retrieval augmentation, or their effect on long-horizon performance.
- Central trace server as a bottleneck: Examine the trace server’s scalability, redundancy, and failure recovery; evaluate distributed logging/metadata services to remove single points of failure.
- Deployment on modest hardware: Study performance on CPU-only clusters or smaller GPU setups; quantify what configurations make AWorld accessible to non-enterprise users.
- Security of code execution: Assess sandbox escape risks, resource abuse, and privilege separation in e2b-code-server/terminal-controller; propose and test hardened policies.
- Answer extraction and finalization: Document how final answers are extracted/validated from trajectories; compare different answer finalization strategies and their impact on correctness.
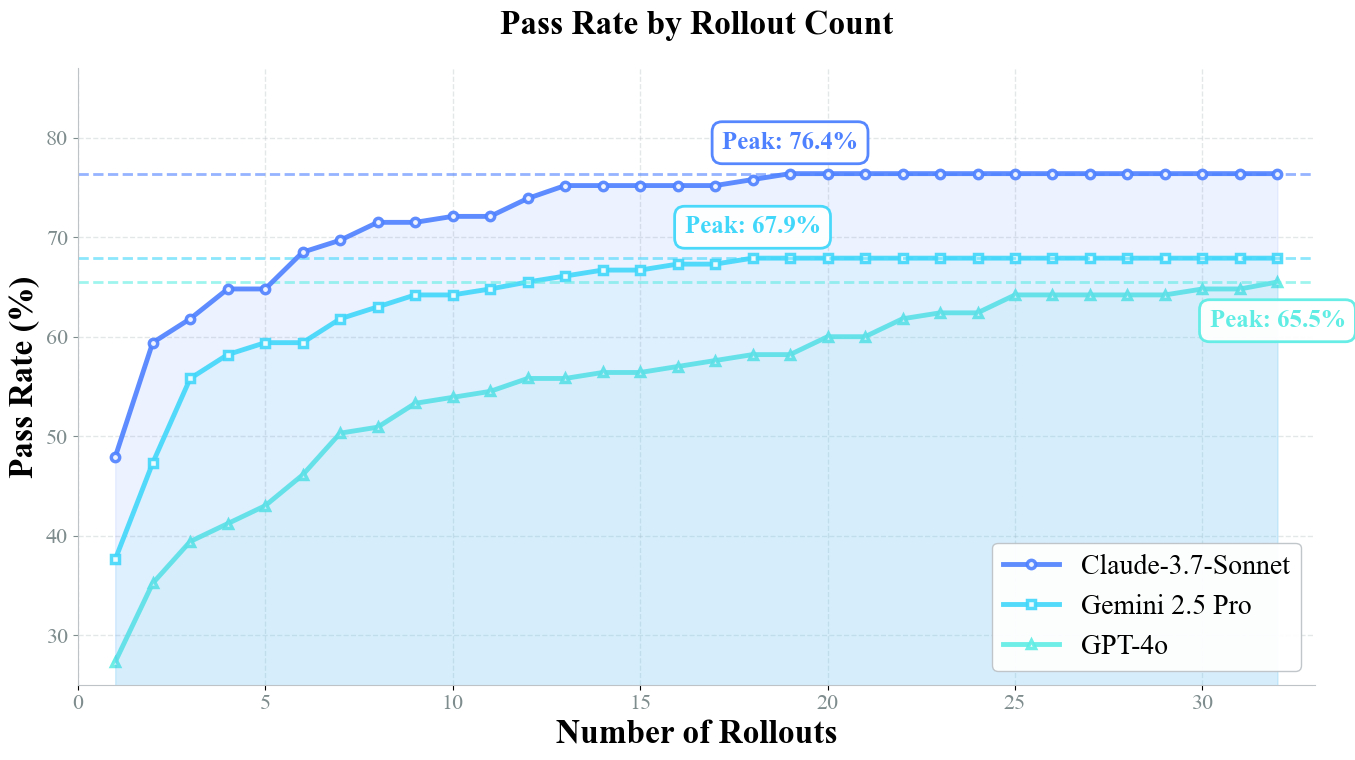
- Pass@k plateau analysis: Investigate why pass@k gains plateau around 10–15 rollouts; develop policies or planning strategies that reduce required rollouts rather than merely accelerating them.
- Comparative framework benchmarks: Benchmark AWorld against existing agents frameworks (LangChain, OpenAgents, OpenAI Agents SDK, AutoGPT) for rollout efficiency, reliability, and training integration.
- Full reproducibility kit: Release seeds, exact versions, Kubernetes manifests, container images, and configs required to deterministically reproduce the reported 14.6× speedup and GAIA improvements.
Glossary
- A2A protocol: Google's Agent-to-Agent communication protocol for coordinating multiple agents. "inter-agent communication (e.g., Google's A2A protocol~\citep{googlea2a})."
- ActionModel: A structured representation of an agent’s chosen action within the system’s messaging payloads. "payload (Any): Main content (e.g., ActionModel, Observation, TaskItem)."
- Advantage estimation: An RL technique to compute how much better an action is compared to a baseline for gradient updates. "we employ the GRPO algorithm for advantage estimation and gradient update computation."
- Agent-as-tool: A design where one agent is exposed as a callable tool for another agent. "including browser-based interfaces, terminal emulators, and agent-as-tool functionalities."
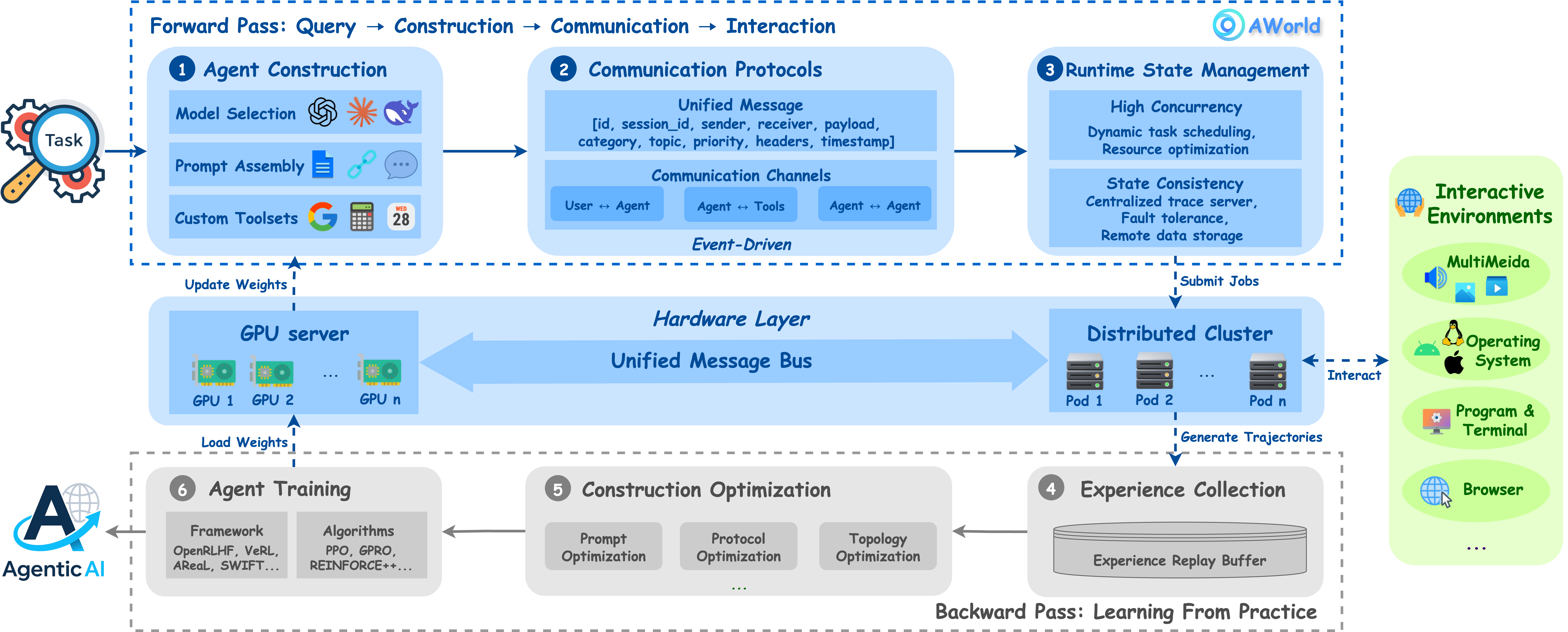
- Agent Construction: The process of defining an agent’s logic, tools, prompts, and planning capabilities. "Agent Construction: We begin at the foundational level by simplifying the instantiation of an individual agent, defining its core logic, toolset, and planning capabilities."
- Agentic AI: AI systems that act as autonomous agents interacting over long trajectories in complex environments. "AWorld, a framework for Agentic AI designed around the ``learning from practice'' paradigm."
- AReaL: A reinforcement learning framework integrated for training agents. "including OpenRLHF~\citep{hu2024openrlhf}, VeRL~\citep{sheng2025hybridflow}, AReaL~\citep{fu2025areal}, and SWIFT~\citep{zhao2025swift}"
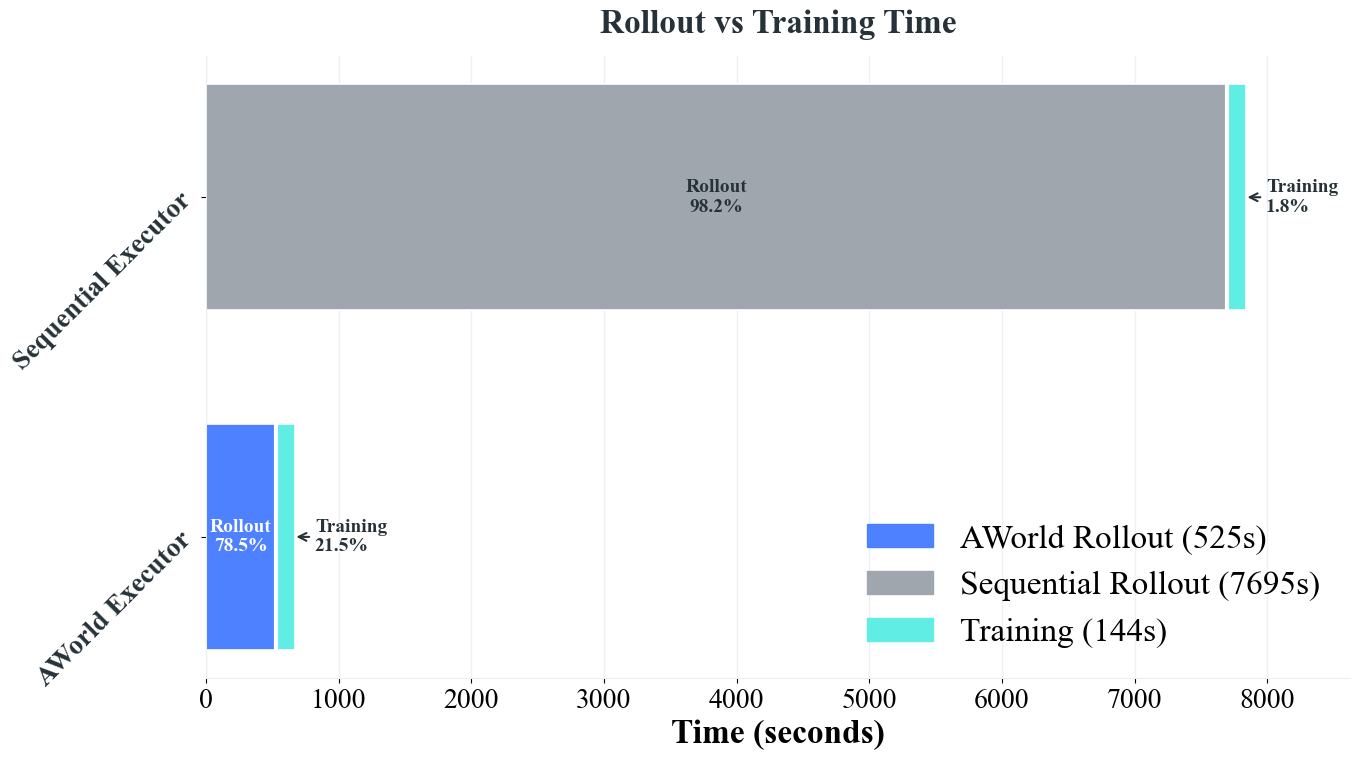
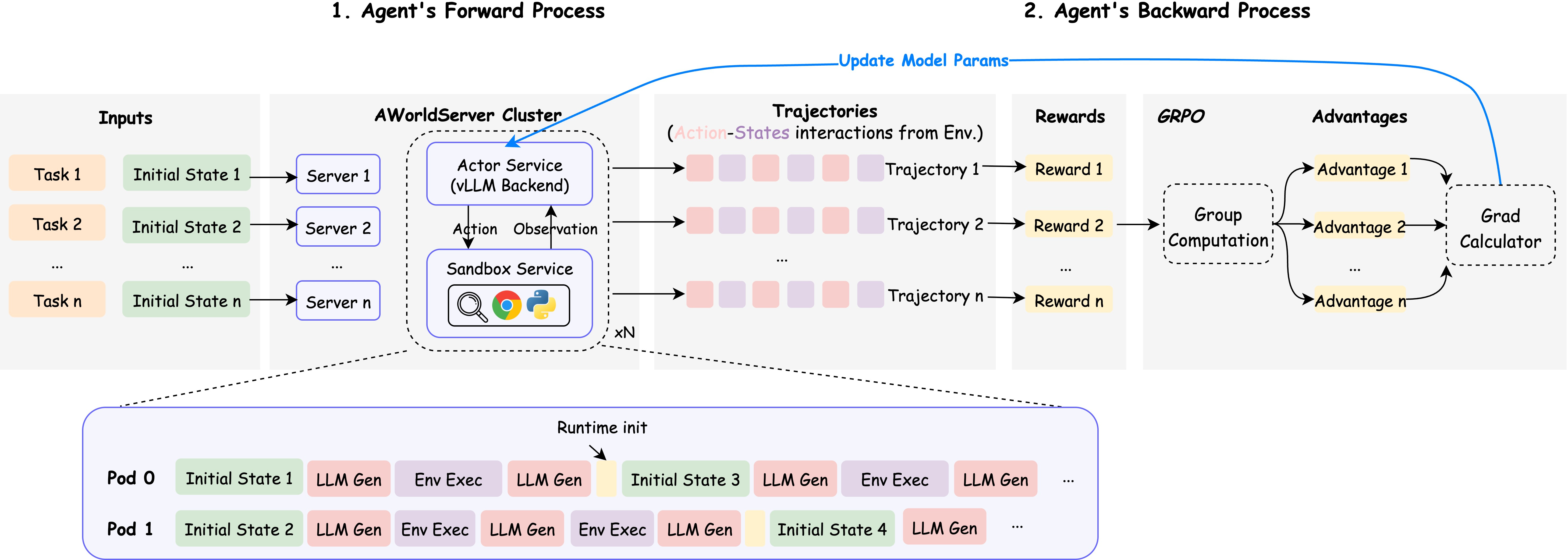
- AWorld Executor: The distributed rollout engine that executes agent tasks concurrently across environments. "As shown in \cref{tab:rollout_time}, the efficiency gains are substantial. The AWorld Executor completes the rollout phase in just $525$ seconds,"
- Backward Pass: The training flow where collected trajectories are used to update the agent via RL. "a Backward Pass (bottom; \ding{175}-\ding{177}), where these trajectories are used as experience to train agents and optimize the entire system via reinforcement learning."
- Combinatorial action space: A large set of possible actions and parameters that agents must search over. "characterized by a combinatorial action space of diverse tools and their parameters,"
- DeepSpeed ZeRO3: A memory-optimization strategy enabling large-model training across GPUs. "memory-intensive optimization strategies such as DeepSpeed ZeRO3~\citep{rajbhandari2020zero}."
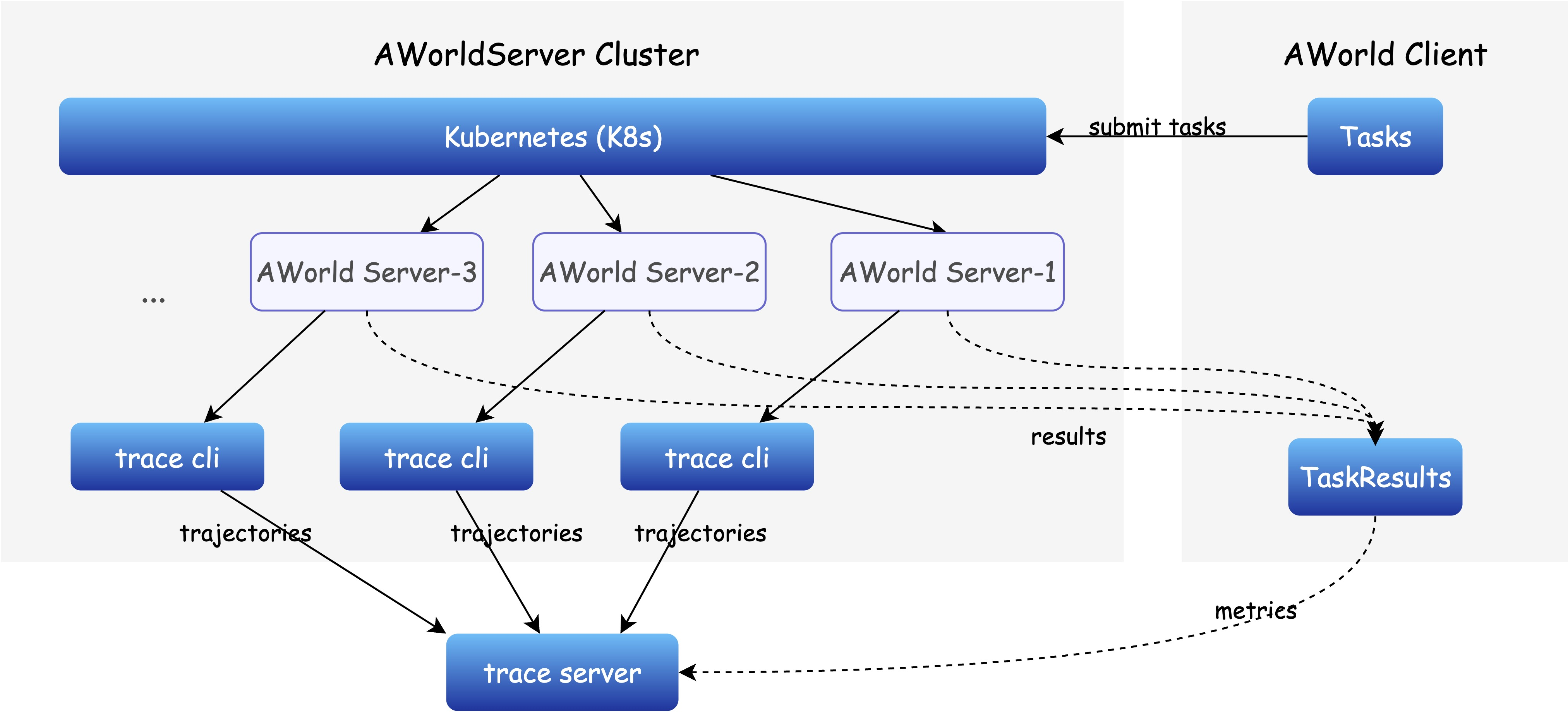
- Distributed architecture: A system design that spreads computation and state across multiple nodes for scalability. "AWorld adopts a distributed architecture that prioritizes robustness and scalability."
- End-to-End learning-from-practice pipelines: Complete workflows from interaction to training that continuously improve agents. "position AWorld as an ideal platform for implementing End-to-End learning-from-practice pipelines,"
- Epoch timestamp: A time value representing seconds since the Unix epoch used for message creation. "timestamp (float): Epoch timestamp for message creation."
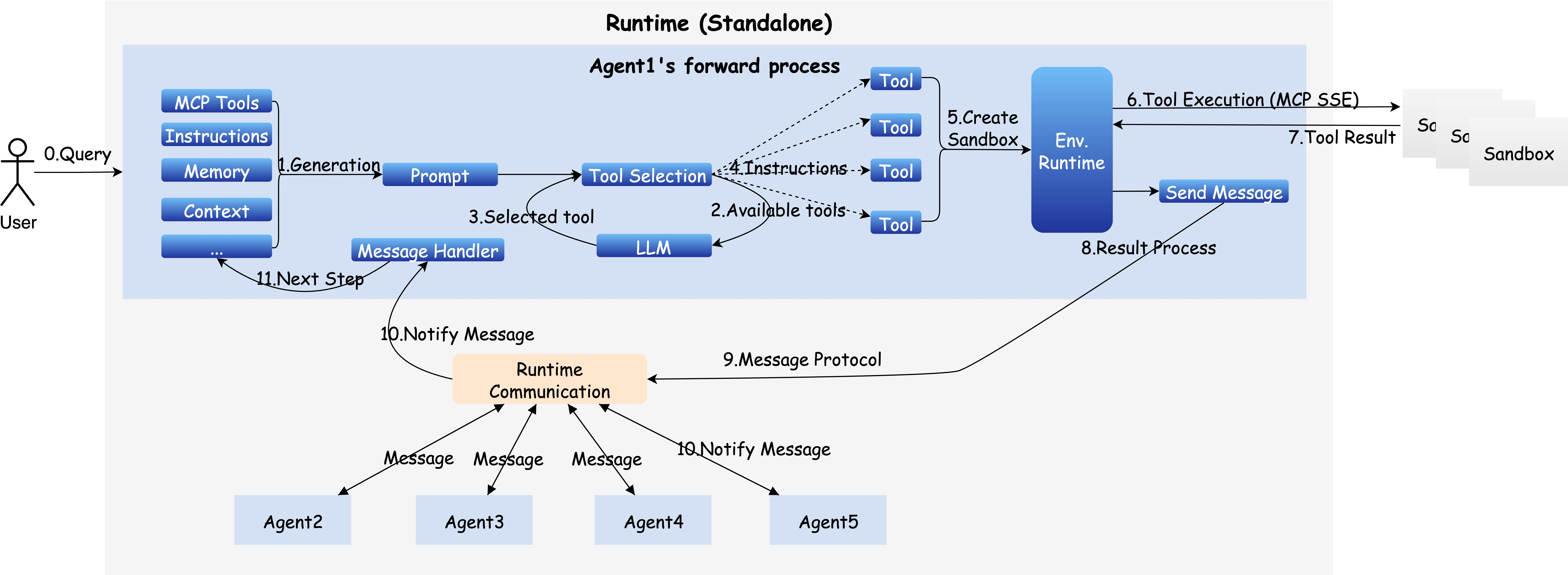
- Event-driven communication: A messaging pattern where agents react to events to coordinate and delegate tasks. "This event-driven communication enables agents to notify, coordinate, and delegate tasks dynamically,"
- Exploration (rollout): The RL phase where agents interact with environments to collect experience. "A standard RL algorithm, such as GRPO, generally involves three key stages: exploration (rollout), feedback (reward), and learning (gradient update)."
- Forward Pass: The execution flow where agents interact with environments to generate trajectories. "a Forward Pass (top; \ding{172}-\ding{174}), where agents are constructed and interact with complex environments to generate task-solving trajectories;"
- GAIA benchmark: A challenging evaluation suite for agentic AI with complex, multi-step tasks. "on the challenging GAIA benchmark~\citep{mialon2023gaia}, even closed-source models like GPT-4~\citep{achiam2023gpt} achieve only 3.99\% accuracy,"
- GRPO: A policy-gradient RL algorithm used for exploration, reward modeling, and updates. "A standard RL algorithm, such as GRPO, generally involves three key stages: exploration (rollout), feedback (reward), and learning (gradient update)."
- Headless Excel engine: An Excel-processing service without a GUI for reading/writing .xlsx sheets. "excel & Lightweight headless Excel engine that reads and writes on .xlsx sheets."
- Heterogeneous workloads: Diverse task types and resource demands managed across a cluster. "By efficiently managing heterogeneous workloads and maximizing resource utilization,"
- High Concurrency: The capability to run many agent tasks simultaneously across a cluster. "High Concurrency."
- Inference engine: The serving component that generates actions from the current model during rollout. "interacts with the inference engine of the RL framework to query actions at each step."
- Inter-agent communication: Messaging between separate agents for coordination and collaboration. "inter-agent communication (e.g., Google's A2A protocol~\citep{googlea2a})."
- Intra-agent communication: Interaction between an agent’s internal components, such as models and tools. "intra-agent communication between models and tools (e.g., Anthropicâs MCP~\citep{mcp2024});"
- Kubernetes: A container orchestration system used for scheduling parallel rollout environments. "managed by Kubernetes"
- LLMs: Powerful neural models trained on large corpora for language tasks. "LLMs~\citep{anthropic2024claude37sonnet,touvron2023llama,team2023gemini}"
- Long-horizon reasoning: Multi-step reasoning across extended sequences of actions and observations. "and the necessity for long-horizon reasoning across extended trajectories."
- Message object: The core data structure for sending messages between agents, users, and tools. "AWorld utilizes the Message object as the core abstraction to unify three primary communication channels:"
- Model Context Protocol (MCP): A protocol for standardized tool/model interaction contexts. "including available tools (such as MCP tools),"
- Multi-agent workflows: Task flows where multiple agents coordinate and collaborate. "supporting both single-agent and multi-agent workflows."
- OpenRLHF: An RLHF framework integrated with AWorld for training pipelines. "including OpenRLHF~\citep{hu2024openrlhf}, VeRL~\citep{sheng2025hybridflow}, AReaL~\citep{fu2025areal}, and SWIFT~\citep{zhao2025swift}"
- Pass@1: The metric measuring success rate when the agent makes a single attempt. "It achieves a pass@1 score that is highly competitive with frontier proprietary models like GPT-4o."
- Pass@k: The metric measuring success rate when the agent is allowed k attempts. "We plot the pass@k success rate for three leading models on the full $165$-question GAIA validation set,"
- Pod: A Kubernetes execution unit encapsulating an environment for agent rollout. "execution unit known as a pod."
- Pub-sub patterns: A messaging paradigm where senders publish to topics and receivers subscribe. "topic (Optional[str]): Topic-based routing channel (for pub-sub patterns)."
- Qwen3-32B: An open-source foundation LLM serving as the base model for the agent. "By using the AWorld framework to fine-tune and conduct reinforcement learning on the Qwen3-32B base model,"
- Reinforcement Learning (RL): A learning paradigm where agents improve via feedback from environment interactions. "There are two commonly used methods to improve the capabilities of the underlying LLM in post-training phase, namely SFT and RL."
- Resource contention: Performance degradation due to competing processes for limited CPU/memory. "leads to severe resource contention and process instability,"
- Rollout: The process of executing agent actions in an environment to generate experience trajectories. "experience generation (rollout) phase"
- Rollout module: The component in RL frameworks that manages environment interaction during exploration. "Specifically, the rollout module in conventional frameworks is replaced with the AWorld Executor."
- Sandboxed environment: An isolated execution environment for secure, reproducible tool actions. "interact with a sandbox, thereby ensuring secure and reproducible execution."
- State consistency: Ensuring coherent and synchronized task state across distributed nodes. "State consistency across distributed nodes is maintained via synchronized remote data storage and a centralized trace server,"
- Supervised Fine-Tuning (SFT): Post-training using labeled data to prime an agent’s initial policy. "SFT typically requires high-quality human-labeled data or a complex data synthesis pipeline,"
- SWIFT framework: An RL training framework integrated for fine-tuning and updates. "processed by the SWIFT framework~\citep{zhao2025swift}, which orchestrates the model's fine-tuning and reinforcement learning updates."
- Topic-based routing channel: A messaging field used to route messages via named topics. "topic (Optional[str]): Topic-based routing channel (for pub-sub patterns)."
- Trace server: A centralized service capturing traces and metadata for distributed execution. "and a centralized trace server,"
- Train-inference decoupled architecture: A design separating training resources from inference/rollout resources. "Our setup employs a train-inference decoupled architecture to optimize resource utilization for agent training."
- Training Orchestration: The coordination of rollout, reward, and gradient update across systems. "Training Orchestration: Finally, to complete the ``learning from practice'' loop, the framework channels the vast experiential data generated by the runtime into external training modules,"
- UUID: A universally unique identifier used to tag messages. "id (str): Unique message identifier (UUID)."
- vLLM: A high-throughput LLM serving system used during rollouts. "AWorld leverages the vLLM~\citep{kwon2023efficient} to manage high-throughput agent inference and interaction with the environment."
- VeRL: A reinforcement learning framework integrated for agent training. "including OpenRLHF~\citep{hu2024openrlhf}, VeRL~\citep{sheng2025hybridflow}, AReaL~\citep{fu2025areal}, and SWIFT~\citep{zhao2025swift}"
- Wall-clock time: Actual elapsed time measured for a full rollout-training cycle. "We measure the wall-clock time for a full cycle of experience generation and model training,"
- Worker nodes: The cluster machines that execute agent rollouts and tasks. "across a distributed cluster of worker nodes."
Collections
Sign up for free to add this paper to one or more collections.