- The paper demonstrates that adopting the OAgents framework standardizes agent design and evaluation to achieve state-of-the-art performance.
- The study systematically compares design choices using the GAIA benchmark, revealing effective strategies in planning, memory, and test-time scaling.
- Empirical results show that integrating innovative memory methods and test-time scaling enhances reproducibility and operational efficiency.
An Empirical Study of Building Effective Agents
This essay examines the paper "OAgents: An Empirical Study of Building Effective Agents," which introduces a new framework for designing and evaluating agent models. The research critiques current agentic AI practices, identifying deficiencies in standardization and reproducibility, ultimately proposing OAgents as a solution.
Introduction to OAgents Framework
The paper highlights fundamental challenges in Agentic AI research: lack of standardized designs and non-reproducible experimental results. This fragmentation prevents accurate comparisons and hinders scientific progress. To address these issues, the authors present OAgents (Figure 1), a modular framework that emphasizes robust evaluation protocols and systematic design choices.
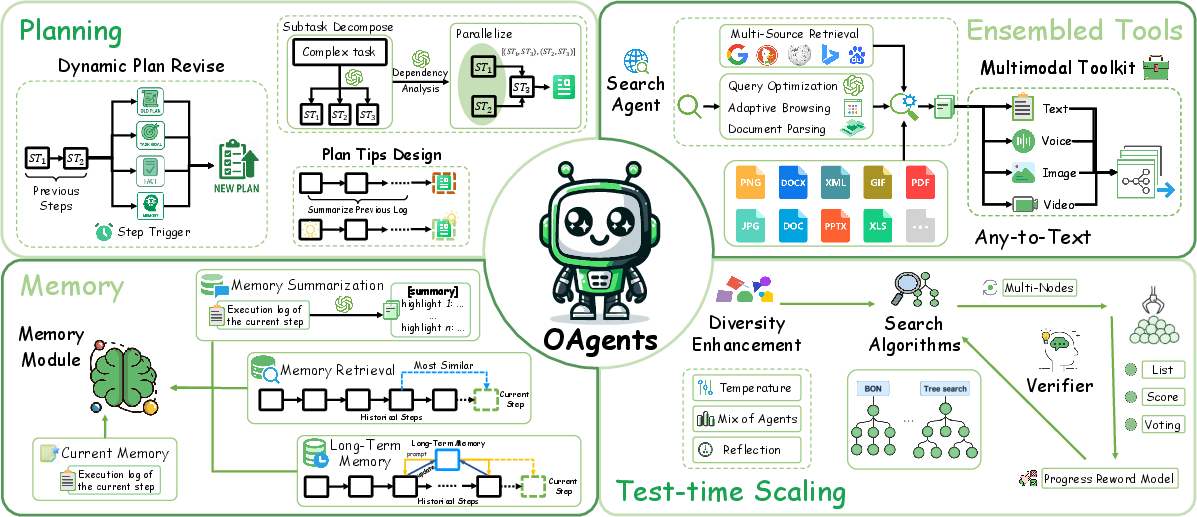
Figure 1: The key components of the OAgents framework, including planning, memory, tools, and test-time scaling.
Design and Evaluation
The study conducts a systematic empirical analysis using the GAIA benchmark, focusing primarily on the impact of design choices across critical agent components, including planning, memory, tools, and test-time scaling (TTS). The rigorous comparison reveals effective strategies for enhancing agent capabilities while identifying redundant components.
The paper discusses factual acquisition through tools and logical reasoning fidelity supported by dynamic plan generation, memory-augmented systems, and TTS. The performance is measured quantitatively against existing frameworks, showcasing improvements in experimental stability and reproducibility (Figure 2).
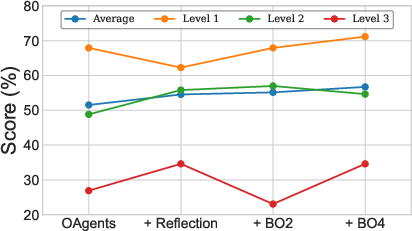
Figure 2: OAgents performance evaluation of TTS methods on GAIA.
Empirical Findings
The introduction of OAgents leads to significant performance improvements across various benchmarks, with the framework achieving state-of-the-art results. By integrating innovative memory strategies and test-time scaling methodologies, OAgents enhances its environmental adaptability and reasoning efficiency (Figure 3).
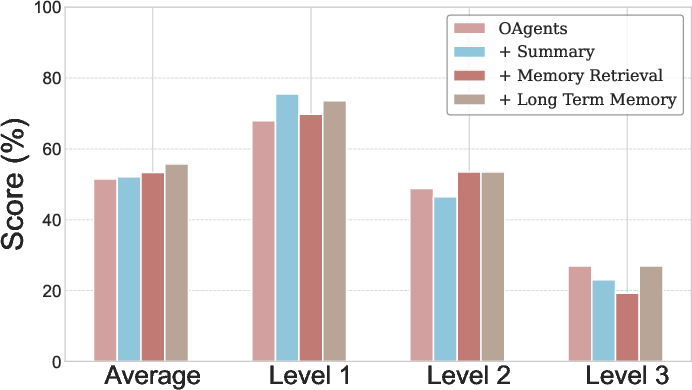
Figure 3: OAgents performance evaluation of various memory methods on GAIA.
Implications and Future Directions
The paper proposes OAgents as a foundational framework that aims to unify agentic research through standardized protocols. By encouraging open-source development and promoting modular integrative designs, the research sets the stage for future exploration in Agentic AI. The findings suggest that further exploration into scalable agent design and evaluation methodologies could drive more consistent and comparable advancements in the field.
Conclusion
"OAgents: An Empirical Study of Building Effective Agents" presents a thorough critique of existing agentic AI research practices and offers a robust alternative through the OAgents framework. The research not only establishes a standard evaluation protocol but also demonstrates how modular design choices lead to superior agent performance. The implication for the AI community is a clear call to refine methodologies for developing more capable and reliable autonomous agents.