AlphaAgents: Large Language Model based Multi-Agents for Equity Portfolio Constructions
Abstract: The field of AI agents is evolving rapidly, driven by the capabilities of LLMs to autonomously perform and refine tasks with human-like efficiency and adaptability. In this context, multi-agent collaboration has emerged as a promising approach, enabling multiple AI agents to work together to solve complex challenges. This study investigates the application of role-based multi-agent systems to support stock selection in equity research and portfolio management. We present a comprehensive analysis performed by a team of specialized agents and evaluate their stock-picking performance against established benchmarks under varying levels of risk tolerance. Furthermore, we examine the advantages and limitations of employing multi-agent frameworks in equity analysis, offering critical insights into their practical efficacy and implementation challenges.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper builds a “team” of AI helpers to pick stocks for an investment portfolio. Each helper (called an agent) has a different job—one reads company reports, one checks the news, and one studies prices—and they talk to each other, argue when they disagree, and then settle on a shared decision. The goal is to see if this teamwork helps choose better stocks than using a single AI or just following the market.
In simple terms: it’s like putting three smart classmates with different strengths on a group project to decide which companies to invest in, then seeing whether their teamwork beats going solo.
What questions were they trying to answer?
- Can a team of specialized AI agents pick stocks better than one AI working alone or a basic market list (a benchmark)?
- Does giving the AI a “personality” about risk (risk-averse vs. risk-neutral) change the choices and results?
- Does having the agents debate reduce mistakes and biases (like being too confident or missing information)?
How did they do it?
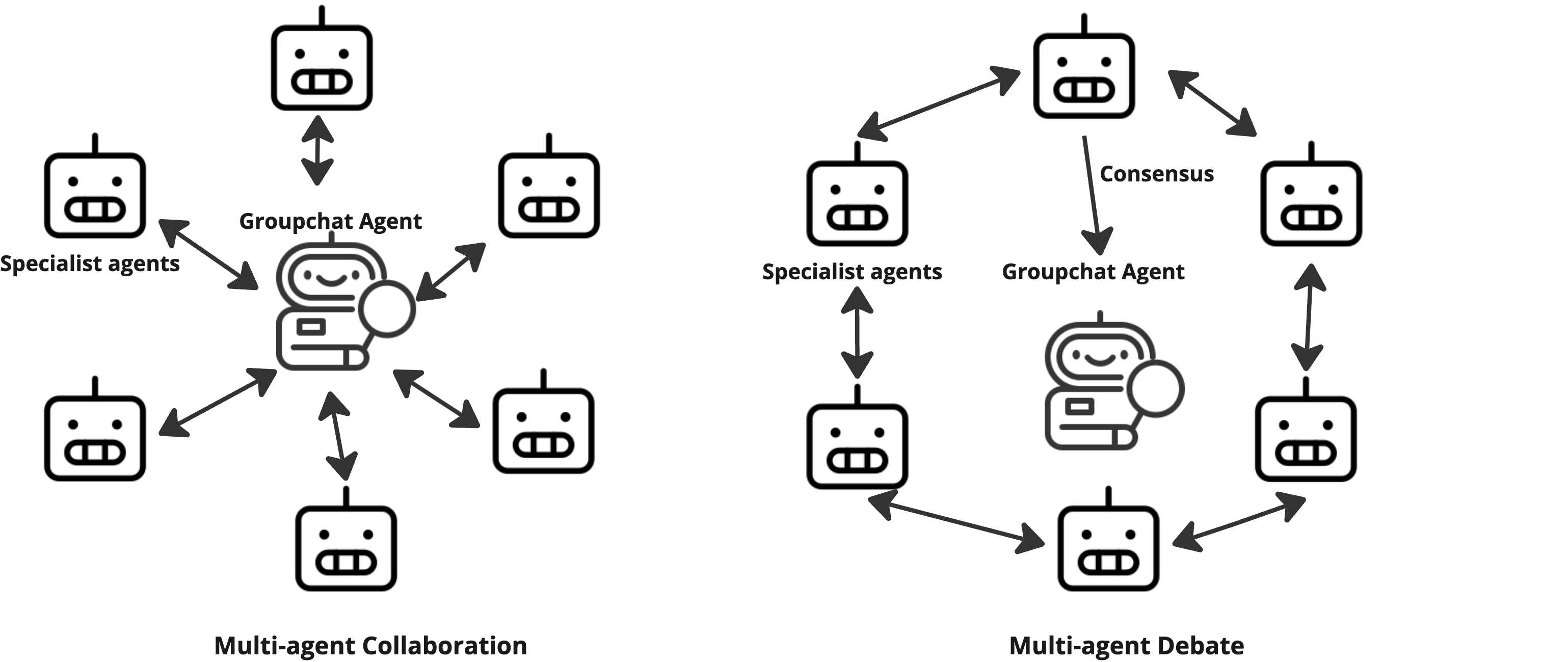
The AI team (three roles)
- Fundamental Agent: Reads official company documents (like 10-K and 10-Q reports) to judge a company’s health (revenues, profits, costs, plans).
- Sentiment Agent: Reads financial news and analyst opinions to sense the mood around a stock (positive, negative, or mixed).
- Valuation Agent: Looks at stock prices and trading volumes to see trends, momentum, and how “bumpy” or risky a stock is.
Think of them as:
- Fundamental = the deep researcher,
- Sentiment = the news watcher,
- Valuation = the numbers/price trend tracker.
Data and tools they used
- Company filings (10-K/10-Q), news articles, and stock price/volume history.
- “Role prompts” told each AI exactly how to act (like job descriptions).
- Special tools:
- A calculator for returns and volatility (how much prices swing).
- A summarizer for news so the Sentiment Agent can quickly digest lots of articles.
- A search-and-retrieve tool for company reports so the Fundamental Agent can quote the right sections.
Plain meaning of key terms:
- Volatility: How much a stock’s price jumps up and down. More jumpy = higher risk.
- Benchmark: A simple comparison set, like a basic list of stocks, used to judge performance.
- Risk tolerance:
- Risk-averse: prefers safer, steadier choices.
- Risk-neutral: okay with more ups and downs if the average payoff looks good.
Getting them to agree
The agents used a “group chat” system to share their analyses. If they disagreed (for example, one says BUY while another says SELL), they entered a structured debate—taking turns to respond—until they reached a consensus. This helps reduce random errors or “hallucinations” (when an AI makes something up) and balances different viewpoints.
Testing the idea (backtesting)
- They picked 15 technology stocks at random to form both the “pool to choose from” and the benchmark.
- The AIs analyzed these stocks in January 2024.
- On February 1, 2024, they built portfolios and then tracked performance for four months.
- Every chosen stock got the same weight (to keep it simple).
- They tested:
- Single-agent portfolios (e.g., only Fundamental or only Valuation).
- The multi-agent portfolio (after debate and consensus).
- Two risk styles: risk-neutral and risk-averse.
- They measured:
- Returns (how much the portfolio grew).
- Sharpe ratio (returns per unit of risk). You can think of the Sharpe ratio as “how much gain you got for each amount of bumpiness.”
They also checked that:
- The Fundamental and Sentiment agents were using the right sources.
- The Valuation agent actually used the calculator tool for math (to avoid guesswork).
What did they find?
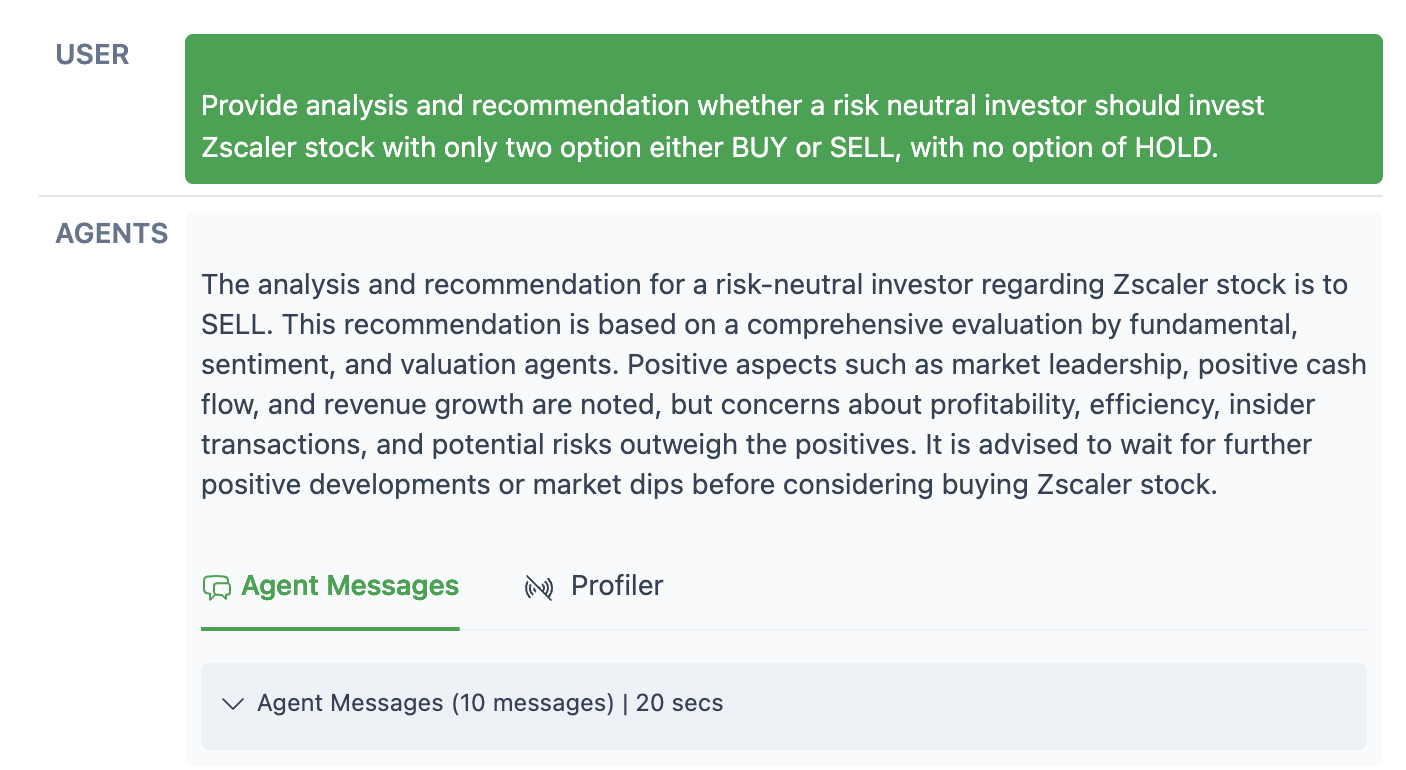
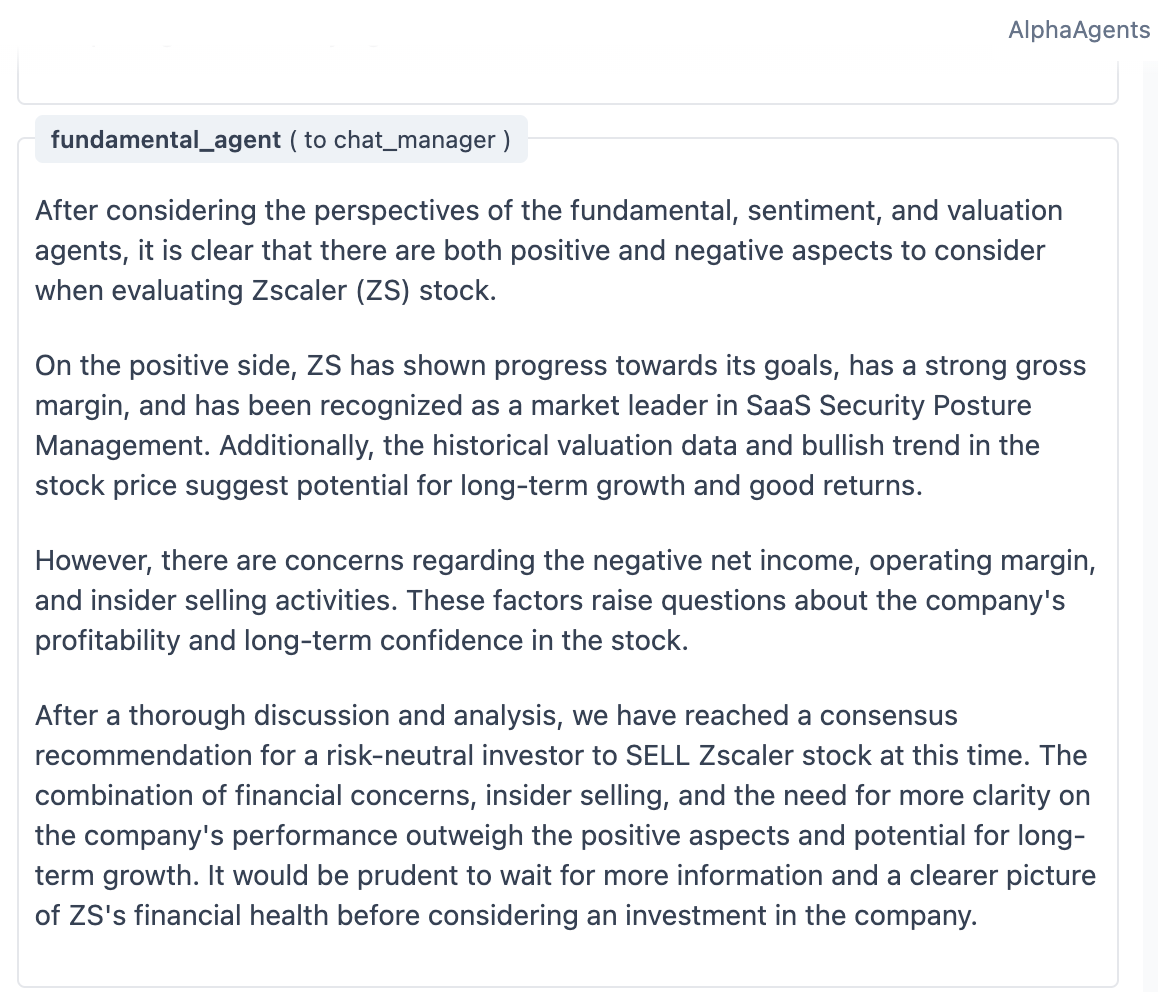
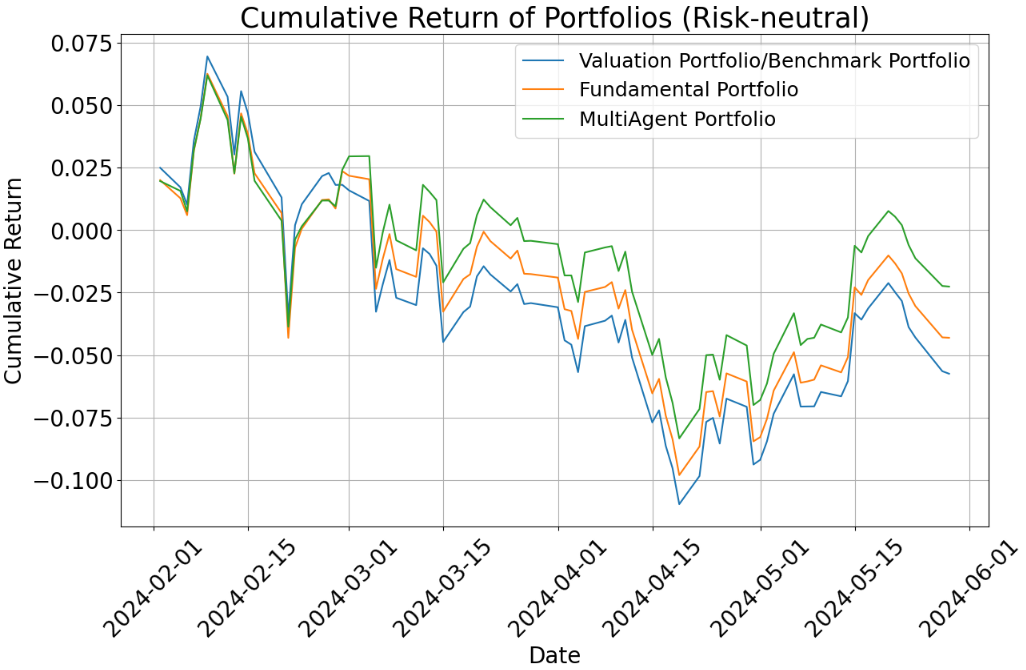
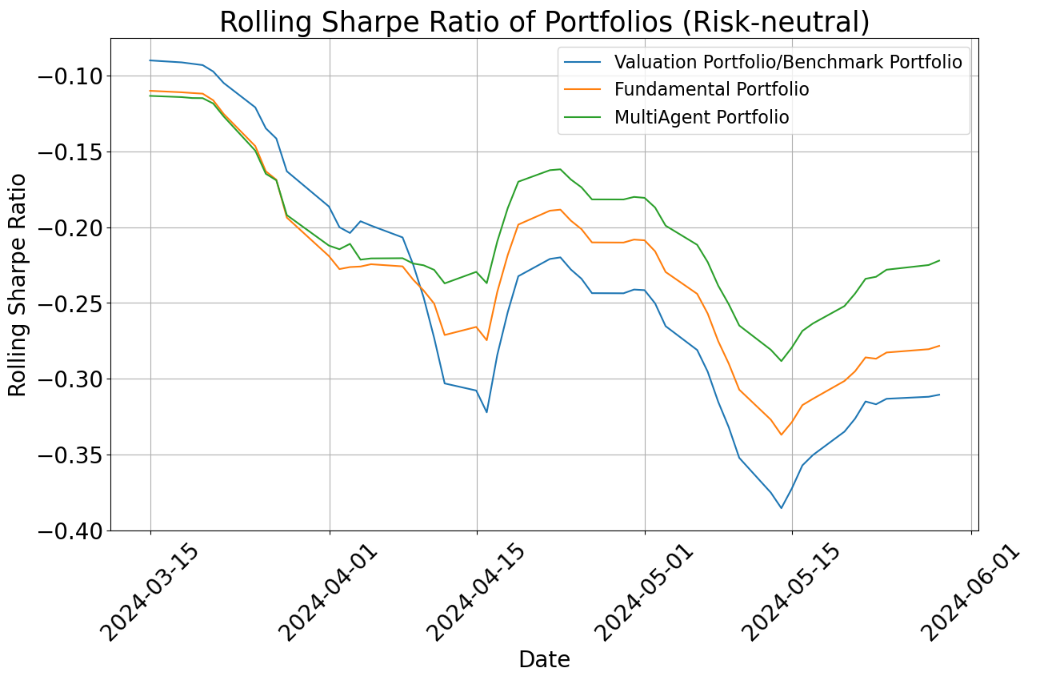
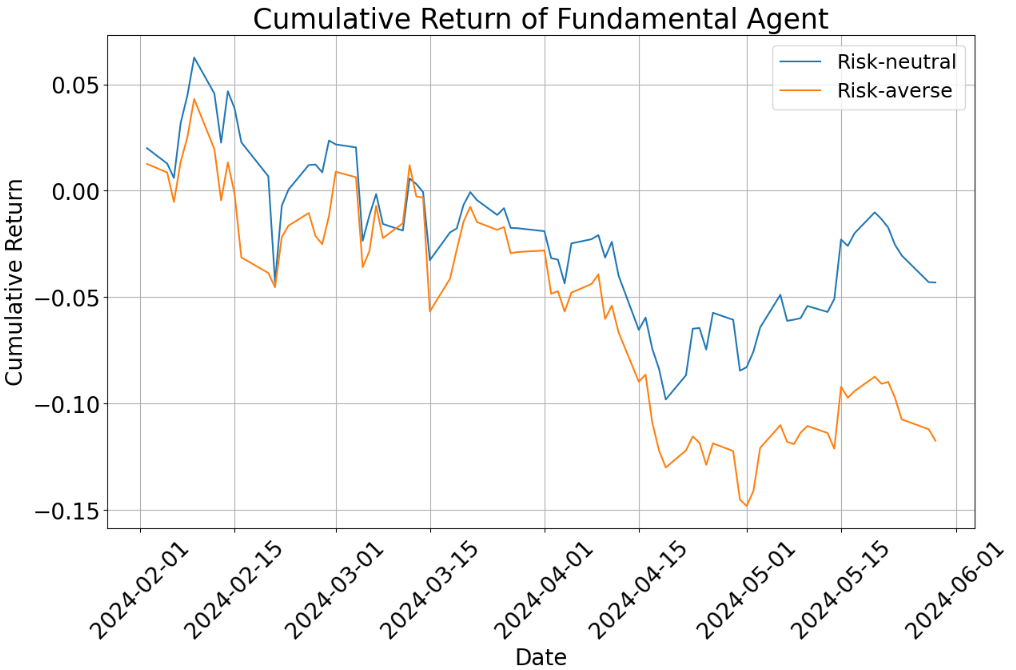
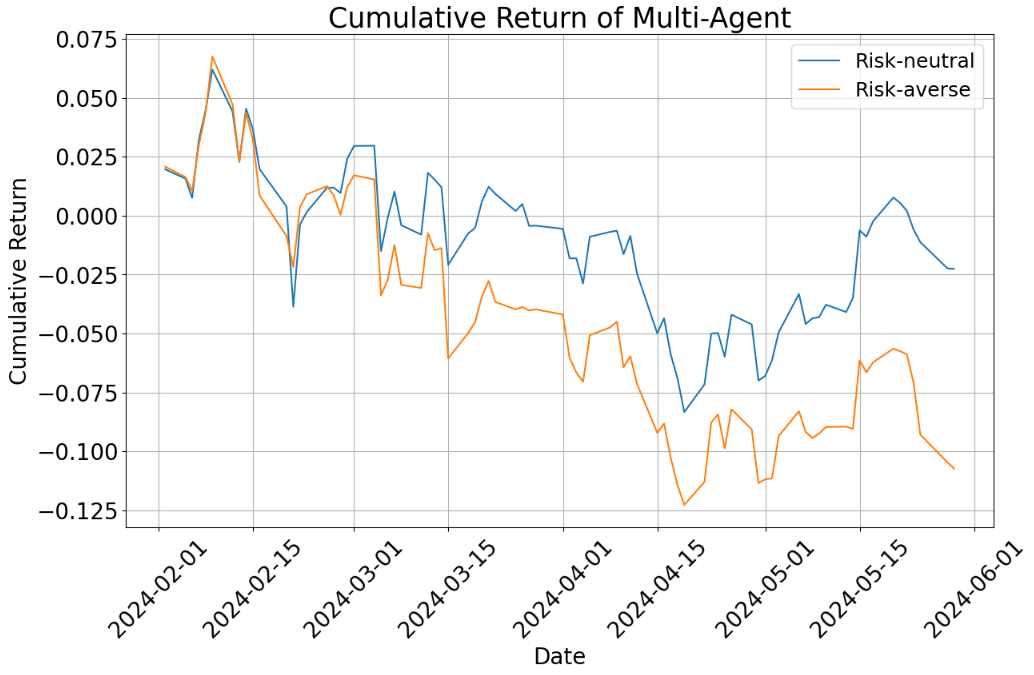
- Risk-neutral setting (okay with normal ups and downs):
- The multi-agent portfolio did better than both the single-agent portfolios and the benchmark during the test period.
- Why? The team combined short-term signals (news and price trends) with long-term fundamentals (company reports). This balance helped.
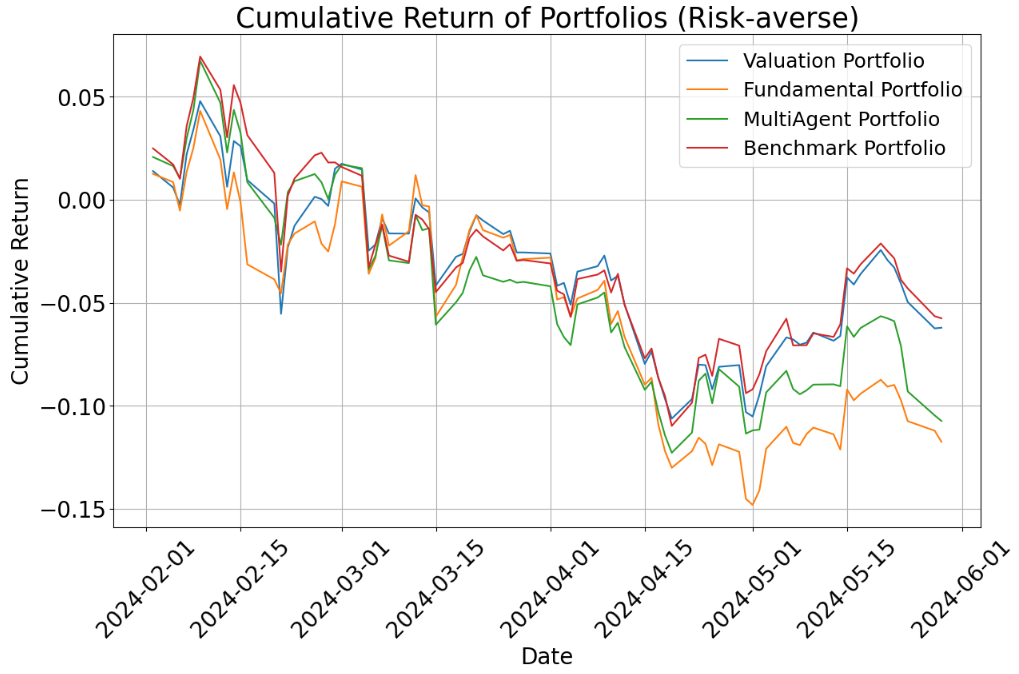
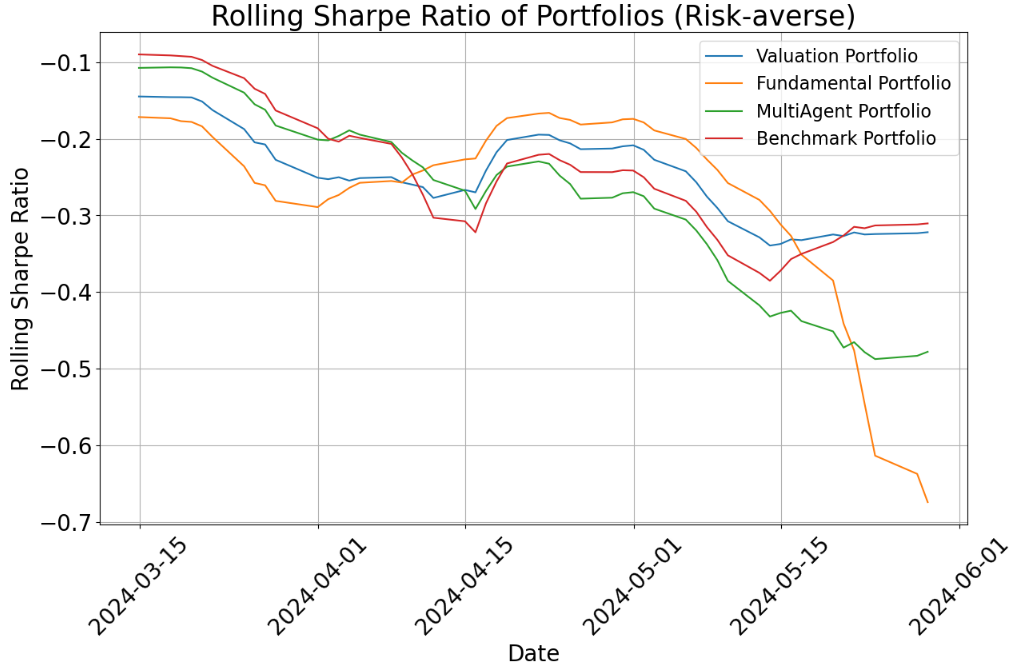
- Risk-averse setting (prefers safety):
- All risk-averse portfolios underperformed the benchmark over these months because tech stocks did very well—and risk-averse portfolios avoided many of those (since tech can be volatile).
- Even so, the multi-agent portfolio generally did a bit better than the single-agent ones in this cautious mode and had slightly smaller losses when the market dipped (lower drawdowns).
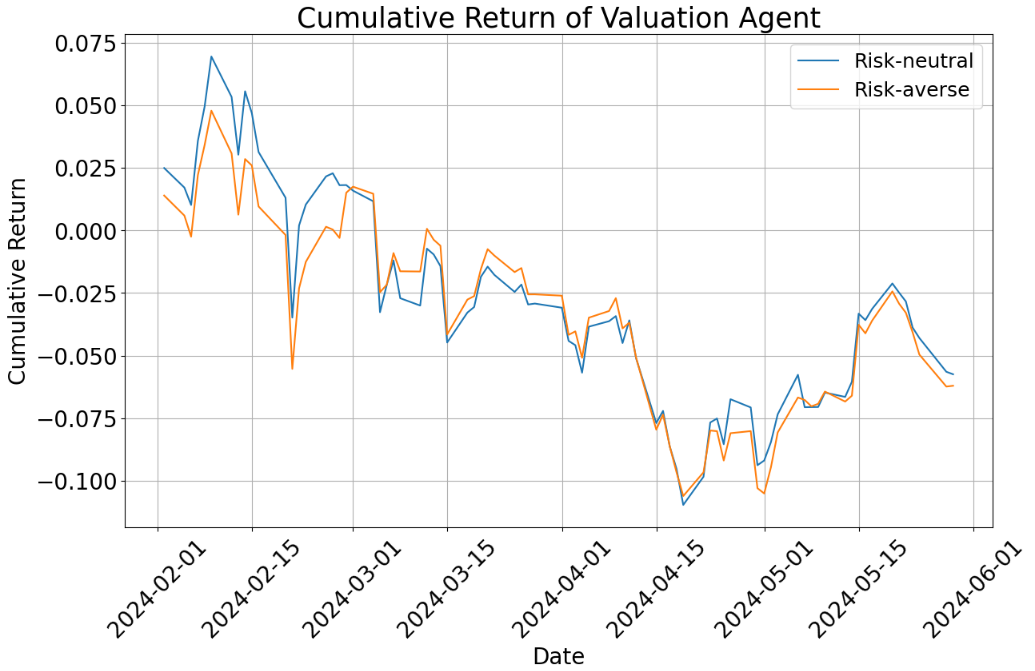
- Risk personality matters:
- Changing the instructions to be risk-averse vs. risk-neutral led to different picks and results.
- A “risk-seeking” version looked a lot like risk-neutral in practice (a limitation of prompt-only changes).
- Debating helps:
- The agents’ structured debates improved reasoning, reduced mistakes, and produced clearer, more balanced decisions.
- They kept logs of their discussions, so people can review how decisions were made.
Important note: This was a small, short test (15 tech stocks over four months), so results are early and not a guarantee.
Why does this matter?
- Teamwork can beat solo: Combining different AI “specialists” and letting them debate can lead to better stock choices than using one model alone.
- Less bias, more balance: The system can help cut down on human biases (like being swayed by one flashy piece of news) and AI-specific errors, because each agent checks the others.
- Clearer decisions: The debate logs make the reasoning transparent, which is useful for real investment teams.
- Building blocks for the future: While this system focused on picking which stocks to include, it could plug into more advanced portfolio tools later (like strategies that decide how much money to put into each stock).
- Limits and next steps: The test was short and focused on tech stocks. In the future, they could add more agents (like a macroeconomics expert), better risk controls, and broader data to make the system more robust.
In short: a small AI “committee” that reads reports, watches news, and checks prices—then debates—can make smarter, more balanced stock picks than one AI alone, especially when risk preferences are clearly defined.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is intended to guide concrete follow-up work.
- Sample size and scope: The backtest relies on 15 randomly selected technology stocks over a four-month window; replicate with larger cross-sections, multiple sectors, and multi-year horizons to assess generalization and regime robustness.
- Benchmark choice: The benchmark is constructed from the same 15-stock pool; compare against standard market indices (e.g., sector ETFs, S&P 500) and widely used quant baselines to avoid circular benchmarking.
- Statistical rigor: No statistical significance tests are reported; add hypothesis testing (e.g., bootstrapped confidence intervals, p-values) to assess whether outperformance is statistically meaningful and robust to random seeds.
- Transaction costs and market frictions: Results ignore trading costs, slippage, spreads, liquidity constraints, shorting restrictions, and capacity; incorporate realistic execution assumptions and turnover penalties.
- Weighting strategy: Portfolios are equal-weight; develop and evaluate signal-to-weight mappings (e.g., confidence calibration, Bayesian aggregation, Black-Litterman integration, optimization under risk budgets).
- Rebalancing and turnover: Rebalance rules and frequencies are unspecified; examine performance sensitivity to rebalancing cadence, turnover constraints, and holding horizons.
- Risk modeling: Risk tolerance is encoded via prompt text only; explore formal utility functions (e.g., CRRA/CARA), risk budgets, CVaR constraints, and explicit volatility/Drawdown targets to achieve distinguishable behaviors across risk profiles.
- Risk-seeking profile indistinguishability: Risk-seeking outputs are “nearly indistinguishable” from risk-neutral; investigate alternative conditioning mechanisms (reward shaping, structured prompts, policy constraints) that yield measurable differentiation.
- Debate mechanics: The Round Robin “speak at least twice” rule and consensus termination criteria are heuristic; compare arbitration schemes (e.g., majority voting, weighted voting, judge agents, Delphi methods) and study debate length vs. performance/cost trade-offs.
- Hallucination reduction claims: Debate is asserted to reduce hallucinations without quantitative evidence; measure factuality error rates, external fact-check pass rates, and tool-use adherence, and correlate these metrics with downstream portfolio outcomes.
- RAG evaluation link to performance: Faithfulness/relevance scores (Phoenix) are reported but not connected to portfolio returns; test whether retrieval quality predicts investment performance and identify thresholds that materially affect outcomes.
- Agent ablation and contribution analysis: No ablation studies quantify each agent’s marginal value; run controlled experiments removing one agent at a time, varying toolsets, and measuring additive/synergistic effects on performance and risk.
- Baseline comparisons: Comparisons omit standard quant baselines (e.g., momentum/value factors), RL portfolio agents, and non-agentic LLM approaches (single-agent CoT, tool-augmented pipelines); include these to isolate the value of multi-agent coordination.
- Modalities with sparse coverage: The sentiment agent is excluded when news is sparse; design robust fallbacks (imputation, cross-agent uncertainty propagation, confidence downgrades) for missing modalities and quantify the impact on decisions.
- Data provenance and alignment: The fundamental agent’s “Report Pull Tool” references yfinance for 10-K/10-Q retrieval (inconsistent with SEC sources); clarify and harden the pipeline (EDGAR timestamps, exact filings, versioning) and verify time alignment to prevent look-ahead bias.
- Embeddings and chunking: GPT-4o is stated as the embedding model (unusual); compare dedicated embedding models (e.g., text-embedding variants) and evaluate chunking/section strategies (“context trucking”) for retrieval quality and latency.
- Sentiment pipeline design: The summarization tool “learns through all the data” without clear constraints; assess risks of overcompression, omission of critical details, and bias amplification, and compare summarize-then-classify vs. RAG-grounded sentiment extraction.
- Numerical tool correctness: Monitoring checks whether tools are invoked, not whether outputs are numerically correct; add independent validations (e.g., re-computation via tested libraries), unit tests, and discrepancy alerts for computed metrics.
- Formula accuracy and documentation: Several LaTeX formulas appear malformed (e.g., annualization, rolling Sharpe); ensure canonical definitions, document implementation details (day count conventions, risk-free conversion), and test sensitivity to these choices.
- Regime robustness: Evaluate across bear/bull/sideways regimes (e.g., 2020 crash, 2022 drawdown) to quantify stability of multi-agent benefits under adverse conditions and shifting market correlations.
- Sector and geography generalization: Extend beyond U.S. tech to value/cyclical sectors, small/mid caps, international equities, and multi-asset portfolios; study transferability and domain-specific agent tuning.
- Latency, throughput, and cost: Multi-agent chat increases inference overhead; measure end-to-end latency, cost per analysis, scaling behavior with agent count, and practical feasibility for real-time research workflows.
- Security and safety: Address prompt injection, tool misuse, data exfiltration, and adversarial inputs; add guardrails, content filters, and audit trails, and test resilience under red-teaming scenarios.
- Compliance and reproducibility: Reliance on proprietary Bloomberg news raises reproducibility issues; provide open-data alternatives or controlled-access artifacts, and detail licensing/compliance implications for institutional deployment.
- Explainability evaluation: While debate logs provide transparency, no explainability metrics are applied; evaluate clarity, completeness, and consistency of rationales (e.g., human scoring, rubric-based assessments) and their relation to decision quality.
- Human bias mitigation: Claims that agents mitigate behavioral biases are not empirically tested; design human-in-the-loop experiments measuring bias proxies (loss aversion, overconfidence, herding) with and without agent augmentation.
- Risk and drawdown metrics: Focus on Sharpe; include Sortino, maximum drawdown, Calmar, tail risk (VaR/CVaR), and factor exposure decomposition to better characterize risk-return trade-offs.
- Market impact and capacity: No assessment of capacity constraints or market impact for scaling strategies; simulate execution under realistic volumes and measure degradation as assets under management increase.
- Confidence calibration: BUY/SELL signals are not calibrated to probabilities or expected returns; develop calibration procedures (Platt scaling, isotonic regression) and map to weights or Black-Litterman views with uncertainty estimates.
- Aggregation policy: The system informally balances short-term (sentiment/valuation) and long-term (fundamental) signals; design a formal meta-aggregator (e.g., hierarchical Bayesian fusion, regime-aware weighting) and test adaptability across regimes.
- Handling contradictory signals: Consensus logic is opaque when agents strongly disagree; define tie-breaking rules, escalation paths (expert judge agent), and quantify decision consistency across repeated runs.
- Rebalancing under new information: The framework’s responsiveness to incremental data (new filings, news) is untested; evaluate continuous deployment, event-driven updates, and their impact on turnover and performance.
- Additional agents: The paper suggests future agents (macro, technical) but provides no empirical plan; quantify incremental value, interaction effects, and potential diminishing returns from more agents.
- Governance and oversight: Specify how human analysts can override, audit, or constrain agent outputs; define accountability, version control, and change management for production use.
- Versioning and model drift: GPT model upgrades can alter behaviors; institute model/version tracking, reproducible pipelines, and stability tests to manage drift and ensure consistent outputs over time.
Glossary
- 10-K: Annual annual report filed with the SEC by U.S. public companies, detailing financial performance and disclosures. "10-K and 10-Q reports"
- 10-Q: Quarterly report filed with the SEC by U.S. public companies, providing interim financial statements and updates. "10-K and 10-Q reports"
- Alpha: Excess return of an investment relative to a benchmark, often attributed to skill. "generate alpha for clients"
- Arize Phoenix: An open-source toolkit for evaluating LLMs and RAG systems, including retrieval and relevance metrics. "we deployed Arize Phoenix"
- AutoGen (Microsoft AutoGen framework): A framework for building multi-agent LLM applications via conversational collaboration. "We utilize the Microsoft AutoGen framework"
- Autogen Studio: A UI for configuring and interacting with AutoGen agent workflows. "Autogen Studio serves as the user interface."
- Back-testing: Evaluating a strategy by simulating its performance on historical data. "Back-testing as a Down-stream Metric"
- Behavioral Finance: A field studying how psychological biases affect financial decisions. "Behavioral Finance"
- Black-Litterman: A portfolio construction model that blends market equilibrium with subjective views to estimate returns. "Mean-Variance Optimization or Black-Litterman"
- Bloomberg ID: The unique identifier used by Bloomberg to refer to a security. "Bloomberg ID"
- Chain-of-thought prompting: A technique that encourages LLMs to reason step by step in their outputs. "chain-of-thought prompting"
- Cognitive biases: Systematic deviations from rational judgment that affect decisions. "mitigate congnitive biases"
- Cumulative return: Total return of an asset or portfolio over a period, without annualization. "cumulative return"
- Drawdowns: Peak-to-trough declines in portfolio value, measuring downside risk. "all portfolios experience larger drawdowns"
- Efficient frontier anchoring: Using the efficient frontier as a reference point in portfolio decisions, which can bias choices. "efficient frontier anchoring"
- Embedding model: A model that converts text into numerical vectors for retrieval or semantic tasks. "use GPT 4-o as embedding model."
- Earnings calls: Company-hosted conference calls discussing financial results and outlook. "earnings calls"
- Equity portfolio management: The process of constructing and maintaining a portfolio of stocks to meet investment objectives. "Equity portfolio management has traditionally relied"
- Equity research: Analysis of stocks’ fundamentals, valuation, and prospects to inform investment decisions. "equity research"
- Forrester Wave: An analyst report series evaluating vendors in specific technology markets. "Forrester Wave"
- Fundamental analysis: Evaluating a company’s intrinsic value using financial statements and business drivers. "fundamental equity analysis has been the cornerstone of equity research"
- Gross margin: The percentage of revenue remaining after cost of goods sold; a profitability measure. "gross margin"
- Hallucination: LLM-generated content that is fluent but factually incorrect or unfounded. "hallucination issues"
- Insider selling: Sales of company stock by executives or directors, often disclosed via filings. "Insider Selling: Recent sales by multiple directors"
- Insider trading: Trading in a company’s securities by individuals with access to non-public information. "insider trading disclosures."
- Loss aversion: A bias where losses loom larger than equivalent gains, influencing risk-taking. "loss aversion"
- Mean-Variance Optimization: A portfolio optimization method balancing expected return against variance (risk). "Mean-Variance Optimization or Black-Litterman"
- Momentum: A strategy or signal based on the tendency of assets to continue recent performance trends. "emphasizing momentum with caution."
- Operating margin: Operating income divided by revenue; indicates efficiency of core operations. "The operating margin for Company Z is -14.5\%"
- Portfolio diversification: Spreading investments across assets to reduce unsystematic risk. "portfolio diversification or optimization"
- Prospect Theory: A behavioral model describing decisions under risk, emphasizing loss aversion and reference dependence. "Prospect Theory"
- Prompt engineering: Designing inputs to LLMs to elicit targeted, high-quality outputs. "prompt engineering technique"
- RAG (Retrieval-Augmented Generation): An approach that augments LLMs with retrieved context to improve factuality. "RAG tool"
- Risk-adjusted return: Return calibrated by risk, commonly measured by ratios like Sharpe. "risk-adjusted return"
- Risk-averse: Preferring lower risk, even if it reduces expected return. "risk-averse prompt"
- Risk-neutral: Indifferent to risk, focusing solely on expected return. "risk-neutral profile"
- Risk-free rate: The theoretical return on a riskless asset, used as a baseline in finance. "risk-free rate"
- Risk tolerance: The degree of variability in returns an investor or agent is willing to withstand. "Risk tolerance plays a pivotal role"
- Rolling Sharpe ratio: A time-varying measure of risk-adjusted return computed over a moving window. "rolling Sharpe ratio"
- Round Robin approach: A coordination method where agents take turns in sequence to contribute or debate. "Round Robin approach"
- SaaS Security Posture Management: Tools/processes that assess and control the security posture of SaaS applications. "SaaS Security Posture Management"
- Sector research reports: Analyst publications assessing industry segments and their companies. "sector research reports"
- Sentiment analysis: The process of extracting positive/negative attitudinal signals from text. "overarching sentiment analysis"
- Sharpe ratio: A metric of risk-adjusted performance defined as excess return over volatility. "Sharpe Ratio"
- Volatility: The variability of returns, often measured by standard deviation. "higher volatility"
- yfinance API: A Python interface to Yahoo Finance data used for programmatic retrieval of market information. "yfinance API calls"
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented with existing data, models, and tooling described in the paper.
- Multi-agent assisted equity research reports
- Sector: Finance (sell-side/buy-side), Software
- What: Automate first-draft stock notes combining a Fundamental Agent (10-K/10-Q RAG), Sentiment Agent (news summarization), and Valuation Agent (return/volatility analytics), plus a debate transcript for explainability.
- Tools/products/workflows: Analyst workbench with AutoGen group chat, Arize Phoenix dashboards for RAG faithfulness/relevance, yfinance/EDGAR connectors, debate logs embedded in the research note.
- Dependencies/assumptions: Licensed news feeds (e.g., Bloomberg), model governance to control hallucinations, human-in-the-loop approval, stable access to filings; the paper’s backtest is short (4 months, 15 tech stocks), so do not rely on performance claims for production returns.
- Signal generation to feed portfolio construction engines
- Sector: Finance (asset managers, hedge funds), Software
- What: Use per-stock BUY/SELL consensus from multi-agent debate as return signals into existing Mean–Variance Optimization or Black–Litterman stacks.
- Tools/products/workflows: API that emits per-ticker signals with confidence and rationale; integration into existing risk/optimizer pipelines; rolling evaluation of signal Sharpe.
- Dependencies/assumptions: Risk tolerance needs to be set at strategy level; performance depends on market regime and coverage breadth; careful backtesting and transaction cost modeling required.
- Risk-profile–aware screening for client mandates
- Sector: Finance (wealth management), Fintech
- What: Generate risk-averse vs. risk-neutral stock screens conditioned by prompts reflecting client preferences and mandate constraints; use in model portfolios or SMA creation.
- Tools/products/workflows: Prompt templates for risk profiles; side-by-side output comparison to support advisors; “what changed” deltas between profiles.
- Dependencies/assumptions: Prompt-only risk modeling may blur neutral vs. risk-seeking cases (observed in the paper); consider adding hard constraints and volatility caps.
- Investment committee augmentation with debate transcripts
- Sector: Finance (institutional PM teams), Compliance
- What: Use structured multi-agent debate to surface disagreements (e.g., valuation vs. sentiment) and provide an auditable rationale trail for buy/sell decisions.
- Tools/products/workflows: Meeting packs that include agent consensus, dissenting views, and source snippets; archival in research management systems for Model Risk Management (MRM).
- Dependencies/assumptions: Policy for use of AI-generated rationales; data retention and audit controls; human sign-off remains mandatory.
- Real-time news triage and impact assessment
- Sector: Finance (trading desks, risk), Media analytics
- What: Summarize incoming news, infer sentiment and likely price impact, and push alerts with suggested watchlist actions.
- Tools/products/workflows: News ingestion queue → summarization agent → sentiment score + rationale → alerting; prioritization by portfolio exposure.
- Dependencies/assumptions: News licensing and latency; model guardrails for speculative headlines; coverage gaps lower utility (noted in paper).
- 10-K/10-Q navigator for analysts
- Sector: Finance (research), Education
- What: RAG-based interactive querying of filings to answer specific questions (cash flow, margin, risks), with section-level context tracking.
- Tools/products/workflows: EDGAR ingestion, chunking by section, embeddings (e.g., GPT-4o), source-cited answers; “teach me” mode for new analysts.
- Dependencies/assumptions: Correct chunking/embedding; mitigation of retrieval drift; continuous evaluation with Phoenix faithfulness metrics.
- Bias mitigation coaching in research workflows
- Sector: Finance (behavioral finance), HR/Training
- What: Use multi-agent adversarial reasoning to counter overconfidence/herding by surfacing alternative theses and evidence; embed as a “bias check” step before recommendations.
- Tools/products/workflows: Pre-trade checklist augmented by agent debate prompts; dashboards highlighting where agents diverged most.
- Dependencies/assumptions: Effectiveness depends on agent diversity and tool usage; ensure agents weigh sources rather than echoing each other.
- Research coverage scaling and gap detection
- Sector: Finance (sell-side/buy-side)
- What: Expand coverage to thinly analyzed tickers by generating baseline reports and flagging securities with insufficient news/fundamentals for high-confidence calls.
- Tools/products/workflows: Daily pipeline that triages universes by data coverage and confidence; “needs human review” queue.
- Dependencies/assumptions: Performance degrades when news coverage is sparse (noted for sentiment agent); define confidence thresholds.
- Academic teaching labs on multi-agent finance
- Sector: Academia, Education
- What: Course modules where students replicate the system (AutoGen + RAG + summarization), run small backtests, and study risk preference conditioning.
- Tools/products/workflows: Open datasets (EDGAR, yfinance), Phoenix for evaluation, curated prompts; assignments comparing single-agent vs. multi-agent outputs.
- Dependencies/assumptions: Replace proprietary data (Bloomberg) with open sources; institutional compute and API keys.
- Consumer-facing investing explainer (not advice)
- Sector: Consumer finance, EdTech
- What: App that summarizes a company’s filings and recent news in plain language, clarifies risks, and shows how risk tolerance changes a hypothetical screen.
- Tools/products/workflows: “Explain this stock” with source links; side-by-side risk-neutral vs. risk-averse rationale.
- Dependencies/assumptions: Strong disclaimers (education only); broker/dealer rules if recommendations are implied; supervise hallucinations.
Long-Term Applications
These opportunities require more research, scaling, or development before broad deployment.
- Autonomous multi-agent portfolio manager (“AI PM”)
- Sector: Finance (asset management), Software, Robotics for execution
- What: Extend agents with macro/technical/execution roles to handle end-to-end rebalancing, scenario analysis, and trade execution under strict guardrails.
- Dependencies/assumptions: Robust model risk management, regulatory approval, continuous monitoring; richer evaluation beyond a small backtest; broker/execution integration.
- Standardized audit trails for AI investment decisions
- Sector: Policy/Regulation, Compliance, Finance
- What: Industry frameworks where agent debate logs, data lineage, and tool-usage traces meet regulatory recordkeeping and suitability standards.
- Dependencies/assumptions: Regulator guidance on acceptable AI documentation; privacy and IP constraints on source content; interoperable logging standards.
- Risk preference modeling beyond prompt conditioning
- Sector: Finance (wealth/retirement), Research
- What: Learn calibrated risk profiles from client behavior, utility estimation, and stress tests that drive agent objectives, not just text prompts.
- Dependencies/assumptions: Access to historical client outcomes, preference elicitation protocols, and fine-tuning/RL; fairness and bias audits.
- Cross-asset, multi-modal research agents
- Sector: Finance (multi-asset), Data/AI
- What: Add agents for macroeconomics, credit, commodities, options, and earnings-call audio; unify textual, numerical, and audio/visual modalities.
- Dependencies/assumptions: Large-scale data licensing; multi-modal LLM reliability; domain-specific toolkits and evaluation suites.
- Retail robo-advisors with explainable agent committees
- Sector: Fintech, Consumer finance
- What: Consumer portfolios generated by agent committees with natural-language rationales and risk-path previews; client-specific glide paths.
- Dependencies/assumptions: Licensing, fiduciary/suitability compliance, model explainability to retail standards, robust KYC/AML integration.
- Organizational “Agentic Research OS”
- Sector: Enterprise software, Finance, Consulting
- What: A platform that orchestrates specialized agents, tools, and data catalogs to produce reports, signals, and decisions across teams, with built-in evaluation (e.g., Phoenix) and approvals.
- Dependencies/assumptions: Data governance, access controls, cost management for LLM calls, change management for analyst adoption.
- Benchmarks and leaderboards for financial agent systems
- Sector: Academia, Industry consortia
- What: Public benchmarks combining retrieval faithfulness, reasoning quality, and downstream portfolio metrics across regimes; ablations of debate strategies.
- Dependencies/assumptions: Shared datasets (open filings/news), reproducible backtesting frameworks, consensus metrics for reasoning quality.
- Integration with alternative data and tool-augmented analytics
- Sector: Finance (quant/alt data)
- What: Equip agents with APIs for fundamentals, supply chain, web traffic, and satellite data; have valuation agents compute factor exposures and scenario sensitivities.
- Dependencies/assumptions: Alt-data rights and cost; robust tool-calling and error handling; clear validation to avoid overfitting.
- Human–AI co-piloting and upskilling programs
- Sector: HR/Training, Finance
- What: Structured curricula that pair analysts with agents to reduce ramp time, standardize research quality, and codify firm playbooks into agent prompts/tools.
- Dependencies/assumptions: Dedicated training content, feedback loops for prompt/tool updates, cultural buy-in.
- Policy sandboxes for AI-enabled advisory
- Sector: Policy/Regulation
- What: Regulator-facilitated environments to test AI agents for advice under constrained settings, measuring suitability, bias, and disclosure effectiveness.
- Dependencies/assumptions: Cross-industry collaboration; standardized test cases; consumer protection safeguards.
Notes on cross-cutting assumptions and dependencies
- Data access and licensing: Bloomberg news and other premium feeds require licenses; ensure compliant EDGAR/yfinance use. Coverage gaps reduce sentiment agent utility.
- Model risk management: LLM hallucinations must be mitigated via tool-use, RAG, monitoring (e.g., Phoenix), and human review. Keep complete debate and source logs.
- Generalization: The paper’s performance evidence is limited (short window, small tech subset); institutions must perform broader, regime-aware backtests with transaction costs.
- Security and privacy: Consider on-prem or finance-tuned models (e.g., finance-specific LLMs) for sensitive data; apply access controls and redaction.
- Regulatory compliance: Suitability, disclosures, audit trails, and record retention need to be embedded; clarify that outputs are not advice unless licensed and supervised.
- Operational readiness: Establish SLAs for data latency, tool reliability, and cost containment; define escalation paths when agents disagree or confidence is low.
Collections
Sign up for free to add this paper to one or more collections.