- The paper introduces the Chain-of-Agents paradigm that unifies agentic reinforcement learning with multi-agent distillation for streamlined multi-agent collaboration.
- The paper employs a novel multi-agent distillation technique, converting successful MAS trajectories into training datasets to capture complex reasoning patterns.
- The paper demonstrates state-of-the-art performance on benchmarks like GAIA and BrowseComp, showcasing improved adaptability with unseen tools.
Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
The paper "Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL" introduces a novel approach called Chain-of-Agents (CoA), designed to enhance multi-agent systems' problem-solving capabilities by integrating agentic reinforcement learning and multi-agent distillation into a unified framework.
Introduction and Background
Multi-agent systems (MAS) have made strides in complex problem-solving by enabling collaboration among diverse agents equipped with specialized toolsets. Despite this progress, MAS's reliance on manual prompt engineering and complex workflow designs poses challenges in terms of efficiency, capability enhancement, and adaptability to new domains. Previous approaches like Tool-Integrated Reasoning (TIR) models have incorporated tool usage in the reasoning process, yet they fall short of supporting multi-agent systems' end-to-end execution.
The CoA paradigm addresses these limitations by simulating multi-agent collaboration within a single model framework. It activates various agents dynamically to mimic collaborative efforts, reducing computational overhead and supporting both supervised fine-tuning and reinforcement learning.
Method
Chain-of-Agents Paradigm
The CoA paradigm extends TIR by facilitating flexible agent activation, promoting diverse role-playing and tool agents. This intrinsically models multi-agent collaboration by maintaining persistent reasoning states explored through dynamic transitions.
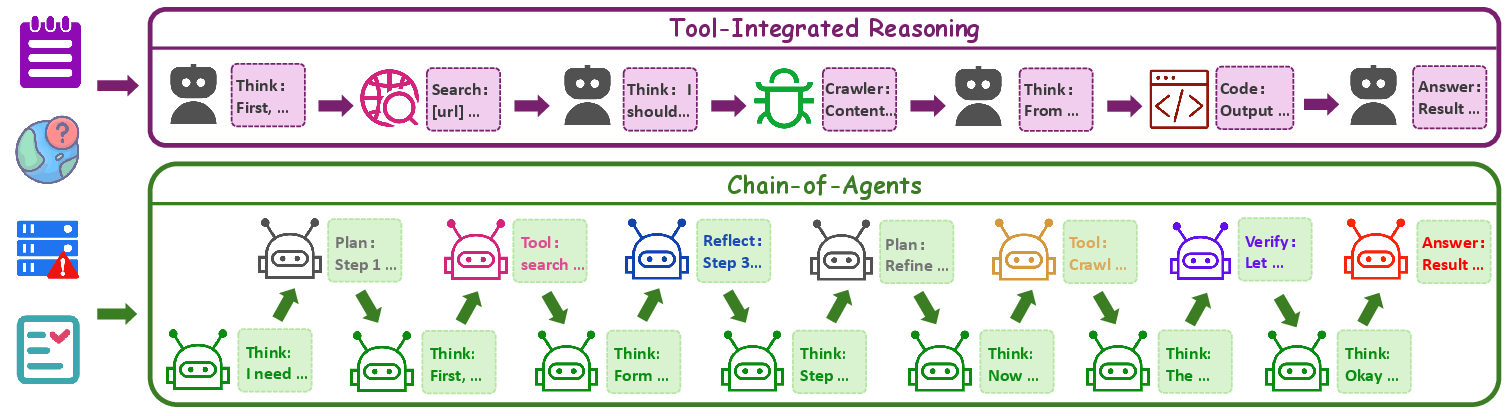
Figure 1: Illustration of TIR and CoA paradigms. TIR uses a static ``Think-Action-Observation'' workflow whereas CoA supports any workflow that can be modeled by a multi-agent system, supporting more diverse role-playing agents and tool agents.
By implementing CoA within a unified model, CoA eliminates redundant inter-agent communication seen in conventional multi-agent frameworks, thus achieving computational efficiency and contextual continuity.
Agentic Supervised Fine-tuning
The paper introduces multi-agent distillation combining agent-level and sequence-level knowledge distillation. Successful multi-agent system trajectories are converted into CoA-compatible ones to enrich training datasets, enabling the distillation of complex reasoning patterns.
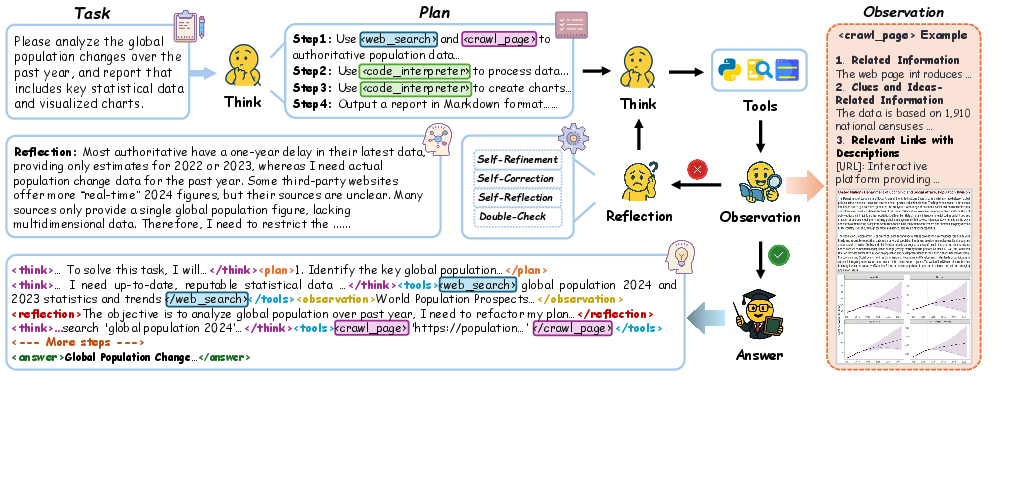
Figure 2: Illustration of the proposed multi-agent distillation framework, which synthesizes Chain-of-Agents trajectories with state-of-the-art multi-agent systems such as OAgents.
Reinforcement Learning and Reward Design
Agentic RL optimizes tool orchestration, balancing correctness and tool efficiency. Distinct reward functions cater to the web and code agent scenarios.
Experiments
Empirical results demonstrate AFM's state-of-the-art performance across multiple benchmarks, including GAIA and BrowseComp, highlighting its effectiveness in web agent tasks. The framework consistently surpasses traditional TIR methods in efficiency and reasoning capabilities.
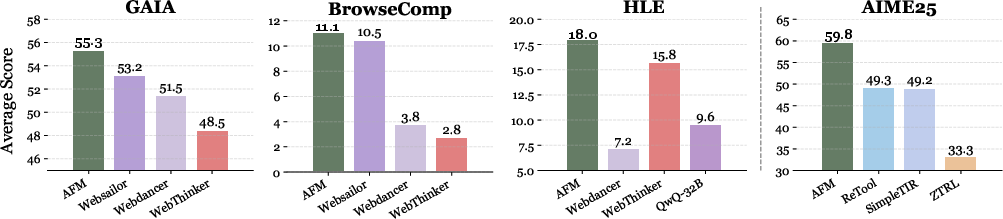
Figure 3: Performance comparison of AFM with the proposed Chain-of-Action paradigm against state-of-the-art tool-integrated reasoning (TIR) methods on GAIA, BrowseComp, HLE, and AIME25 benchmarks. AFM demonstrates consistent effectiveness across web agent and code agent benchmarks.
The study reveals AFM's superior generalization ability, functioning robustly with unseen tools, exemplified in dynamic web environments.
Conclusion
CoA integrates dynamic collaboration into a singular model, leveraging multi-agent distillation to unify complex problem-solving frameworks. This approach paves the way for more efficient, scalable, and adaptive agent systems, poised to redefine agent-based AI models. The research offers a foundational blueprint for future studies in agentic RL and MAS advancements.