AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenges
Abstract: This study critically distinguishes between AI Agents and Agentic AI, offering a structured conceptual taxonomy, application mapping, and challenge analysis to clarify their divergent design philosophies and capabilities. We begin by outlining the search strategy and foundational definitions, characterizing AI Agents as modular systems driven by LLMs and Large Image Models (LIMs) for narrow, task-specific automation. Generative AI is positioned as a precursor, with AI Agents advancing through tool integration, prompt engineering, and reasoning enhancements. In contrast, Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy. Through a sequential evaluation of architectural evolution, operational mechanisms, interaction styles, and autonomy levels, we present a comparative analysis across both paradigms. Application domains such as customer support, scheduling, and data summarization are contrasted with Agentic AI deployments in research automation, robotic coordination, and medical decision support. We further examine unique challenges in each paradigm including hallucination, brittleness, emergent behavior, and coordination failure and propose targeted solutions such as ReAct loops, RAG, orchestration layers, and causal modeling. This work aims to provide a definitive roadmap for developing robust, scalable, and explainable AI agent and Agentic AI-driven systems. >AI Agents, Agent-driven, Vision-Language-Models, Agentic AI Decision Support System, Agentic-AI Applications

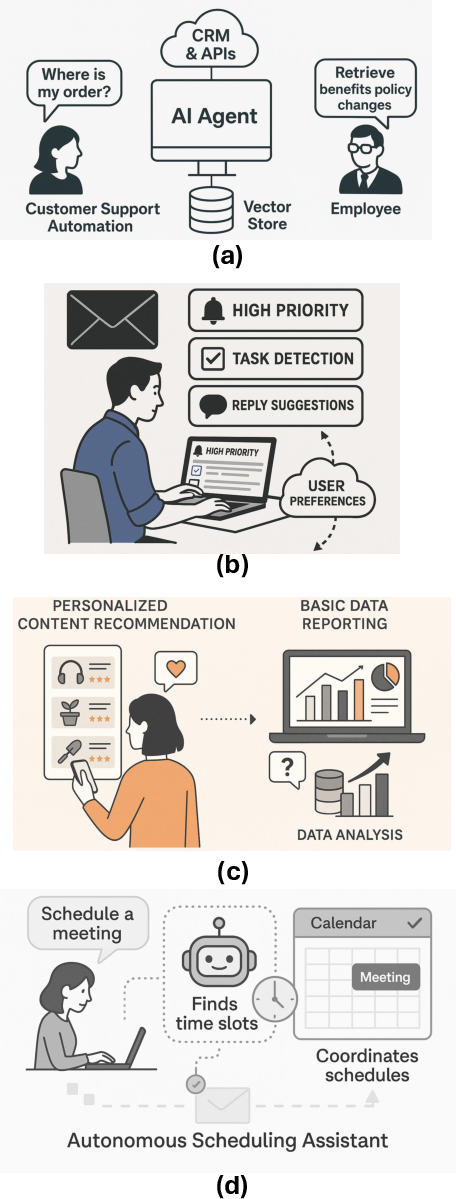
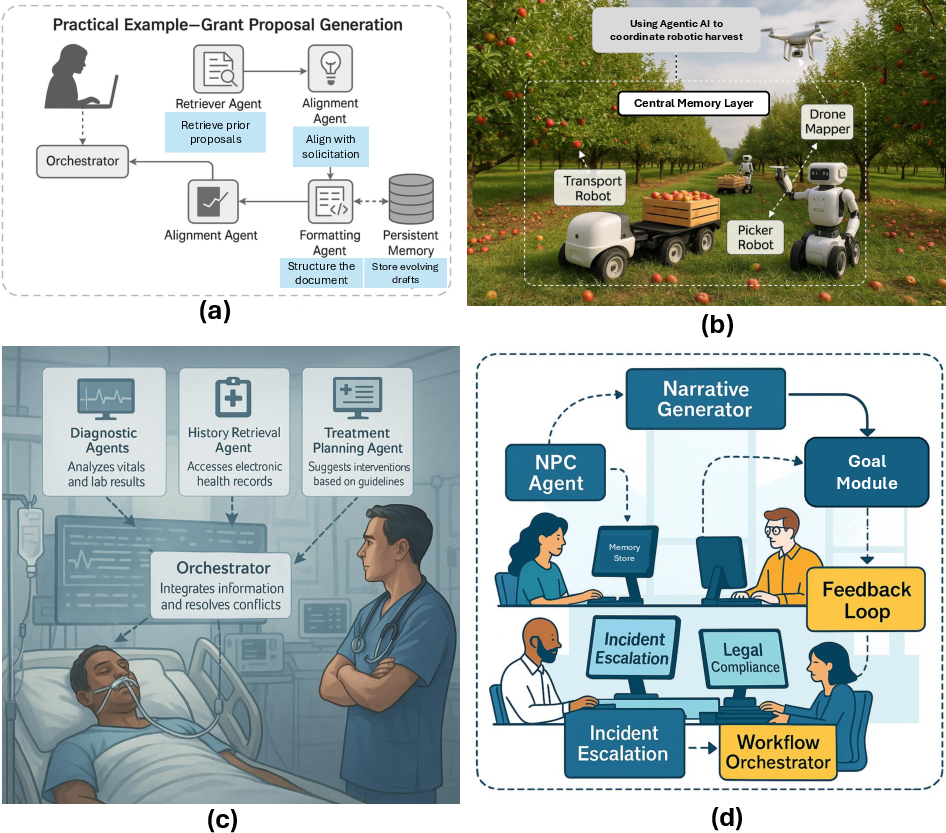 *Figure 6: Illustrative Applications of Agentic AI Across Domains: Figure (b)-(d) visualizes sophisticated multi-agent systems for tasks like robotic coordination, medical decision support. *
*Figure 6: Illustrative Applications of Agentic AI Across Domains: Figure (b)-(d) visualizes sophisticated multi-agent systems for tasks like robotic coordination, medical decision support. *Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Operational definition of “Agentic AI”: Clear, measurable criteria to distinguish AI Agents from Agentic AI (e.g., thresholds for dynamic task decomposition, inter-agent communication effectiveness, persistent memory utilization, and autonomy levels) are not formalized.
- Quantitative benchmarking: No standardized, reproducible benchmarks compare AI Agents vs. Agentic AI across representative tasks (task success rate, time-to-completion, cost, error propagation, robustness), nor agreed-upon datasets or evaluation harnesses.
- Autonomy metrics: A formal scale and measurement protocol for autonomy, reactivity, adaptation, and orchestration complexity across domains is absent.
- Efficacy of proposed mitigations: The paper lists solutions (RAG, ReAct, orchestration layers, causal models) without ablation studies, comparative evaluations, or guidance on when and why each works (and their failure modes).
- Memory architectures: Design, scaling, and evaluation of persistent/shared memory (forgetting mechanisms, contamination control, retrieval fidelity, privacy guarantees, and catastrophic memory leak prevention) are not specified or benchmarked.
- Inter-agent communication protocols: No standardized message formats, semantics, negotiation/consensus mechanisms, conflict resolution strategies, or interoperability guidelines across frameworks are provided, nor metrics for communication overhead and alignment quality.
- Orchestration topology trade-offs: Empirical comparisons of centralized vs. decentralized coordination (fault tolerance, scalability curves, latency, throughput, resource usage, resilience to node failure) are missing.
- Safety and governance: Formal threat models, verification/validation methods, guardrails for emergent behavior, and governance frameworks for coordinated multi-agent systems in high-stakes domains are not articulated.
- Adversarial robustness: No red-team methodologies, attack taxonomies (prompt/tool injection, supply-chain attacks on APIs), or standardized defense evaluations for multi-agent settings are provided.
- Explainability and provenance: Methods to trace decision-making across agents (provenance logs, counterfactual analysis, standardized introspection, chain-of-thought transparency under safety constraints) are not specified.
- Resource and cost modeling: Quantitative analyses of compute, latency, energy/carbon footprint, and cost-performance trade-offs for agentic orchestration are absent.
- Human-in-the-loop design: Criteria for oversight insertion points, escalation policies, trust calibration, UX patterns, and user study metrics for supervising multi-agent workflows are not addressed.
- Regulatory compliance: Concrete pathways and assurance cases for deployment in regulated settings (e.g., HIPAA, GDPR), auditability, accountability, and liability allocation for agentic decisions are not detailed.
- Real-world robotic deployment: Sim2real transfer, real-time constraints, hardware-in-the-loop validation, and formal safety assurances for embodied agentic systems are not examined.
- Cross-modal reasoning: Systematic evaluation of vision-language integration (alignment quality, latency budgets, failure analysis) and multimodal memory in agentic pipelines is not provided.
- Bridging to classical agent theory: A formal mapping from LLM/LIM-based architectures to MAS/BDI frameworks (assumptions, guarantees, mechanism design for incentives, social choice) remains underdeveloped.
- Standardization and ontology: A machine-actionable ontology and schema for agent roles, tasks, tools, memory, and communications to ensure interoperability and reduce misapplication is missing.
- MLOps for agentic systems: Operational practices (monitoring, logging, rollback, policy/version control, memory hygiene, drift detection, incident response) are not outlined.
- Scalability laws: Quantitative scaling analyses relating performance, stability, and emergent phenomena to the number of agents, network topology, and coordination frequency are absent.
- Tool selection and reliability: Algorithms for dynamic tool choice, sandboxing, fallbacks, rate-limit handling, error recovery, and reliability metrics for external services are not specified.
- Bias, fairness, and social impact: Methods to detect and mitigate bias propagation across agents, fairness in negotiation/coordination, and socio-economic impacts (e.g., displacement, power asymmetries) are not addressed.
- Emergent behavior measurement: Standard metrics and detectors for emergence (unintended coordination, collusion, cascades), predictability assessments, and control mechanisms are lacking.
- Evaluation platform: An open-source, reproducible testbed for agentic experiments (tasks, environments, logging, metrics, seeds/versioning) is not proposed.
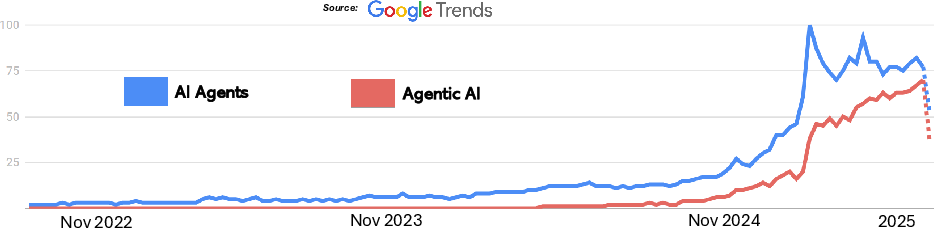
- Trend analysis rigor: The Google Trends analysis lacks replicable query definitions, time windows, regional controls, and confounder analysis to support claims of rising interest.
- Review methodology transparency: The hybrid search lacks PRISMA-style reporting (date ranges, inclusion/exclusion criteria, quality/risk-of-bias assessment, inter-rater reliability, corpus list) to ensure reproducibility.
- Formalization of “orchestrated autonomy”: No mathematical/logic-based specification (e.g., temporal logic, contract-based constraints, verifiable properties) for orchestrated autonomy and coordination safety is provided.
- Non-stationarity and continual learning: Protocols and guarantees for handling domain shift, drift, and online adaptation in long-running agentic systems are missing.
- Data sharing across agents: Privacy-preserving shared memory (access control, encryption, federated memory, differential privacy) and their performance/security trade-offs are not explored.
- Failure modes in coordination: Analyses and mitigations of multi-agent deadlocks, livelocks, race conditions, cascaded failures, and error propagation across roles are not provided.
Glossary
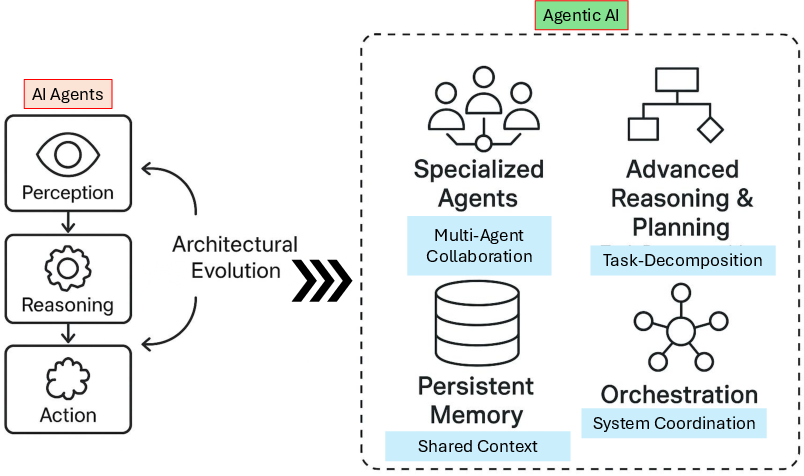
- Agentic AI: A paradigm of coordinated multi-agent systems exhibiting collaboration, dynamic planning, memory, and autonomy. "Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy."
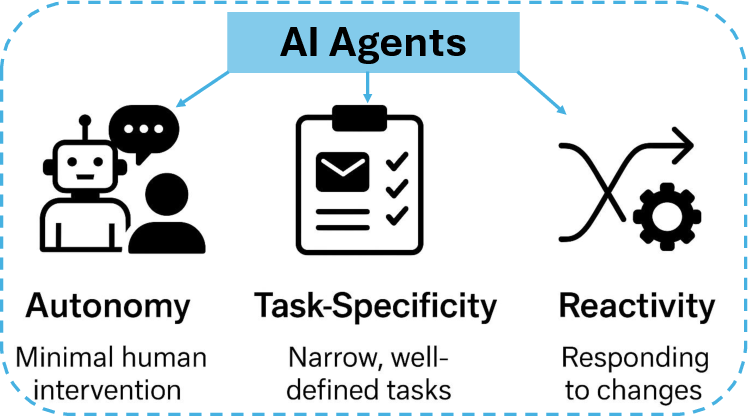
- AI Agents: Autonomous software entities that perceive, reason, and act to complete goal-directed tasks in bounded environments. "AI Agents are an autonomous software entities engineered for goal-directed task execution within bounded digital environments"
- Asynchronous messaging queues: Communication channels that enable decoupled, non-blocking message exchange among agents. "Inter-agent communication is mediated through distributed communication channels, such as asynchronous messaging queues, shared memory buffers, or intermediate output exchanges"
- Auction-based resource allocation: Market-inspired mechanisms where agents bid to distribute resources efficiently. "Multi-agent systems facilitated coordination among distributed entities, exemplified by auction-based resource allocation in supply chain management"
- AutoGen: A framework for building multi-agent LLM systems with coordinated workflows. "agent frameworks like LangChain \cite{pandya2023automating} and AutoGen \cite{wu2023autogen} to orchestrate LLM and LIM outputs"
- AutoGPT: An LLM-based agent framework that plans, acts, and iterates toward goals with tool use. "Frameworks such as AutoGPT \cite{yang2023auto} and BabyAGI (https://github.com/yoheinakajima/babyagi) exemplified this transition"
- BDI (Belief-Desire-Intention) architectures: Cognitive agent models that represent beliefs, desires, and intentions to guide actions. "BDI (Belief-Desire-Intention) architectures enabled goal-directed behavior in software agents"
- BLIP-2: A vision-LLM enabling image-to-text understanding and multimodal reasoning. "Large Image Models (LIMs) such as CLIP \cite{radford2021learning} and BLIP-2 \cite{li2023blip} extend the agentâs capabilities into the visual domain."
- Bounded autonomy: Constrained decision-making capacity aligned with predefined scopes and goals. "These agents distinguish themselves from general-purpose LLMs by exhibiting structured initialization, bounded autonomy, and persistent task orientation."
- Chain-of-Thought prompting: A prompting technique that elicits step-by-step reasoning from LLMs. "The ReAct framework \cite{yao2023react} exemplifies this architecture by combining reasoning (Chain-of-Thought prompting) and action (tool use)"
- CLIP: A model linking images and text for vision-language tasks through joint embeddings. "Large Image Models (LIMs) such as CLIP \cite{radford2021learning} and BLIP-2 \cite{li2023blip} extend the agentâs capabilities into the visual domain."
- Causal modeling: Methods that represent cause-effect relationships to improve reasoning and decision-making. "propose targeted solutions such as ReAct loops, RAG, orchestration layers, and causal modeling."
- Context window: The limited span of tokens an LLM can attend to in a single interaction. "Nevertheless, the inclusion of tools also introduces new challenges in orchestration complexity, error propagation, and context window limitations"
- CrewAI: A multi-agent orchestration framework coordinating specialized agents toward shared objectives. "Architectures such as CrewAI demonstrate how these agentic frameworks can orchestrate decision-making across distributed roles"
- Decentralized protocol: A coordination method without a single central controller, enabling distributed agent interaction. "coordinated through either a centralized orchestrator or a decentralized protocol"
- Emergent behavior: Unanticipated system-level behaviors arising from agent interactions. "We further examine unique challenges in each paradigm including hallucination, brittleness, emergent behavior, and coordination failure"
- Expert systems: Rule-based AI systems using knowledge bases and inference engines for decision support. "For instance, expert systems used knowledge bases and inference engines to emulate human decision-making in domains like medical diagnosis (e.g., MYCIN \cite{shortliffe2012computer})."
- Function calling: Mechanism for LLMs to invoke external tools/APIs through structured calls. "These agents enhanced LLMs with capabilities for external tool use, function calling, and sequential reasoning"
- Generative AI: Models that synthesize new content (text, code, images) in response to prompts. "Generative AI is positioned as a precursor"
- Generative Agents: LLM-based systems focused on producing novel outputs rather than autonomous goal pursuit. "Generative Agents, which are LLM-based systems designed to produce novel outputs such as text, images, and code from user prompts"
- Goal decomposition: Breaking a high-level objective into manageable subtasks for agent assignment. "A key enabler of this paradigm is goal decomposition, wherein a user-specified objective is automatically parsed and divided into smaller, manageable tasks by planning agents"
- Governance risks: Systemic hazards related to oversight, accountability, and policy compliance in AI deployments. "We then assess key challenges faced by both paradigms including hallucination, limited reasoning depth, causality deficits, scalability issues, and governance risks."
- Hallucination: Fabrication of incorrect or non-existent facts by generative models. "We further examine unique challenges in each paradigm including hallucination, brittleness, emergent behavior, and coordination failure"
- Inference engine: The component that applies logical rules to a knowledge base to derive conclusions. "expert systems used knowledge bases and inference engines"
- Instruction fine-tuning: Training that adapts pretrained models to follow task instructions better. "instruction fine-tuning and reinforcement learning from human feedback (RLHF), enable natural language interaction, planning, and limited decision-making capabilities."
- Inter-agent misalignment: Conflicting objectives or behaviors among agents within a system. "For Agentic AI, we identify higher-order challenges such as inter-agent misalignment, error propagation, unpredictability of emergent behavior, explainability deficits, and adversarial vulnerabilities."
- LangChain: A toolkit to compose LLM-powered workflows, tools, and memory into agents. "agent frameworks like LangChain \cite{pandya2023automating} and AutoGen \cite{wu2023autogen} to orchestrate LLM and LIM outputs"
- LangGraph: A framework for building agent workflows as graphs with stateful execution. "Comparative architectural analysis is supported with examples from platforms like AutoGPT, CrewAI, and LangGraph."
- Large Image Models (LIMs): Vision models trained on image-text pairs that enable perception and visual reasoning. "Large Image Models (LIMs) such as CLIP \cite{radford2021learning} and BLIP-2 \cite{li2023blip} extend the agentâs capabilities into the visual domain."
- LLMs: Extensive neural LLMs powering understanding, reasoning, and generation. "LLMs such as GPT-4 \cite{achiam2023gpt} and PaLM \cite{chowdhery2023palm} are trained on massive datasets of text from books, web content, and dialogue corpora."
- Memory architectures: Designs for storing and retrieving past context to inform ongoing decisions. "we outline emerging solutions such as retrieval-augmented generation, tool-based reasoning, memory architectures, and simulation-based planning."
- Meta-agent coordination: Overseeing agents that manage, assign, and align other agents’ tasks. "We describe enhancements such as persistent memory, meta-agent coordination, multi-agent planning loops (e.g., ReAct and Chain-of-Thought prompting), and semantic communication protocols."
- Multi-agent collaboration: Cooperative interaction among multiple agents to achieve shared goals. "Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration"
- Multi-agent planning loops: Iterative coordination mechanisms for agents to plan and act across steps. "We describe enhancements such as persistent memory, meta-agent coordination, multi-agent planning loops (e.g., ReAct and Chain-of-Thought prompting), and semantic communication protocols."
- Multi-agent systems (MAS): Collections of interacting autonomous agents solving distributed problems. "foundational paradigms of artificial intelligence, particularly multi-agent systems (MAS)"
- Multi-turn workflows: Tasks spanning multiple interaction turns that maintain state and context. "selecting tools, and managing multi-turn workflows."
- Ontological categories: Formal classifications of entities and relations used to model social action. "introducing ontological categories for social action, structure, and mind"
- Orchestration frameworks: Systems that coordinate components/agents, tools, and data flows. "The next section examines the architectural evolution from AI Agents to Agentic AI systems, contrasting simple, modular agent designs with complex orchestration frameworks."
- Orchestration layer: A control layer that manages tool calls, agent interactions, and workflow execution. "propose targeted solutions such as ReAct loops, RAG, orchestration layers, and causal modeling."
- Orchestrated autonomy: Structured independence where agents act autonomously under coordinated control. "Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy."
- PaLM: Google’s LLM used for advanced language understanding and generation. "LLMs such as GPT-4 \cite{achiam2023gpt} and PaLM \cite{chowdhery2023palm} are trained on massive datasets of text"
- PaLM-E: A multimodal model linking language and embodied perception for cross-modal tasks. "For instance, models like GPT-4 \cite{achiam2023gpt}, PaLM-E \cite{driess2023palm}, and BLIP-2 \cite{li2023blip} exemplify this capacity"
- Persistent memory: Storage that retains agent experiences across interactions to inform future behavior. "Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy."
- Planning agents: Specialized agents that parse goals and create task sequences for execution. "A key enabler of this paradigm is goal decomposition, wherein a user-specified objective is automatically parsed and divided into smaller, manageable tasks by planning agents"
- Prompt brittleness: Sensitivity of model output quality to small changes in phrasing or context. "For AI Agents, we focus on issues like hallucination, prompt brittleness, limited planning ability, and lack of causal understanding."
- ReAct: A framework combining reasoning steps with tool actions to solve tasks iteratively. "The ReAct framework \cite{yao2023react} exemplifies this architecture by combining reasoning (Chain-of-Thought prompting) and action (tool use)"
- Reflective reasoning: Mechanisms for agents to evaluate past actions to improve future decisions. "Furthermore, reflective reasoning and memory systems allow agents to store context across multiple interactions, evaluate past decisions, and iteratively refine their strategies"
- Retrieval-Augmented Generation (RAG): Augmenting LLMs with external retrieval to ground outputs in sources. "propose targeted solutions such as ReAct loops, RAG, orchestration layers, and causal modeling."
- RLHF (Reinforcement Learning from Human Feedback): Fine-tuning using human preference feedback to guide model behavior. "fine-tuned using techniques such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF)"
- Semantic communication protocols: Structured inter-agent messaging schemes emphasizing meaning and context. "We describe enhancements such as persistent memory, meta-agent coordination, multi-agent planning loops (e.g., ReAct and Chain-of-Thought prompting), and semantic communication protocols."
- Sensor fusion: Combining data from multiple sensors to improve perception and decision-making. "highlighting the integration of computer vision, SLAM, reinforcement learning, and sensor fusion."
- Sense-act cycles: Reactive control loops where agents sense the environment and perform actions accordingly. "Reactive agents, such as those in robotics, followed sense-act cycles based on hardcoded rules"
- Shared memory: Common storage accessible by multiple agents for coordination and context sharing. "shared memory \cite{xu2025mem, riedl2025ai}"
- SLAM: Simultaneous Localization and Mapping for building maps and tracking position in real time. "highlighting the integration of computer vision, SLAM, reinforcement learning, and sensor fusion."
- Supervised Fine-Tuning (SFT): Additional training with labeled examples to refine model outputs. "fine-tuned using techniques such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF)"
- Symbolic reasoning: Logic-based inference using explicit symbols and rules. "relying on symbolic reasoning, rule-based logic, or scripted behaviors"
- Tool Invocation: Steps where an agent issues structured calls to external tools or APIs. "Tool Invocation. When an agent identifies a need that cannot be addressed through its internal knowledge"
- Tool-augmented LLM agents: LLM-powered agents enhanced with external tools for data access and action execution. "researchers have proposed the concept of tool-augmented LLM agents"
- Vectorized academic databases: Embedding-based document stores that enable semantic retrieval. "systems like Paper-QA \cite{lala2023paperqa} utilize LLMs to query vectorized academic databases"
- Vision-language grounding: Linking visual inputs with textual descriptions to understand scenes and tasks. "LIMs enable perception-based tasks including image classification, object detection, and vision-language grounding."
Collections
Sign up for free to add this paper to one or more collections.