Agent Lightning: Train ANY AI Agents with Reinforcement Learning
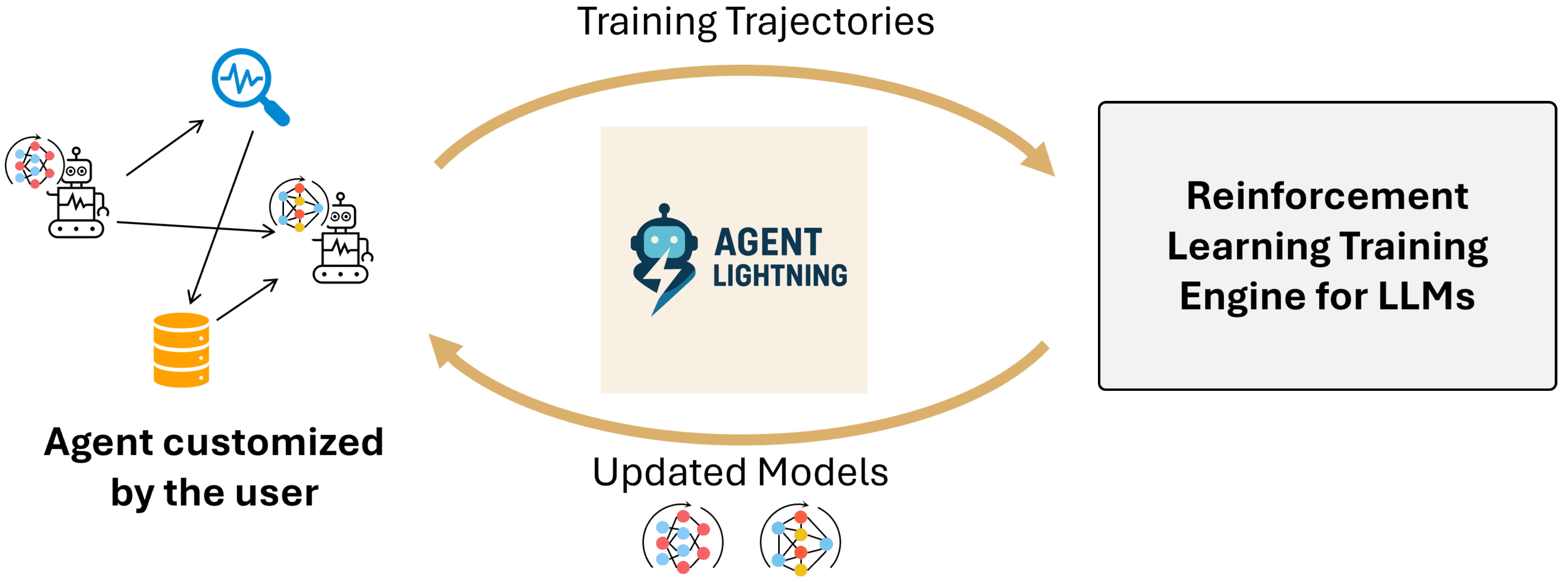
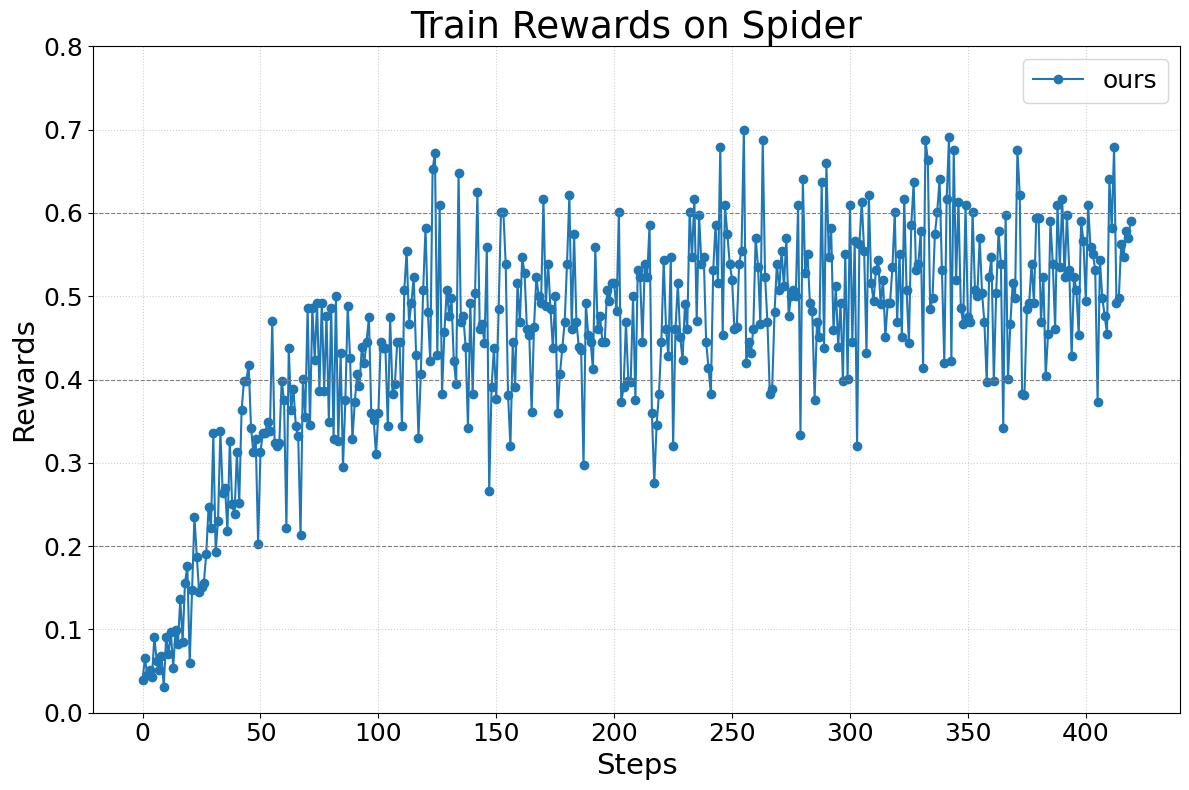
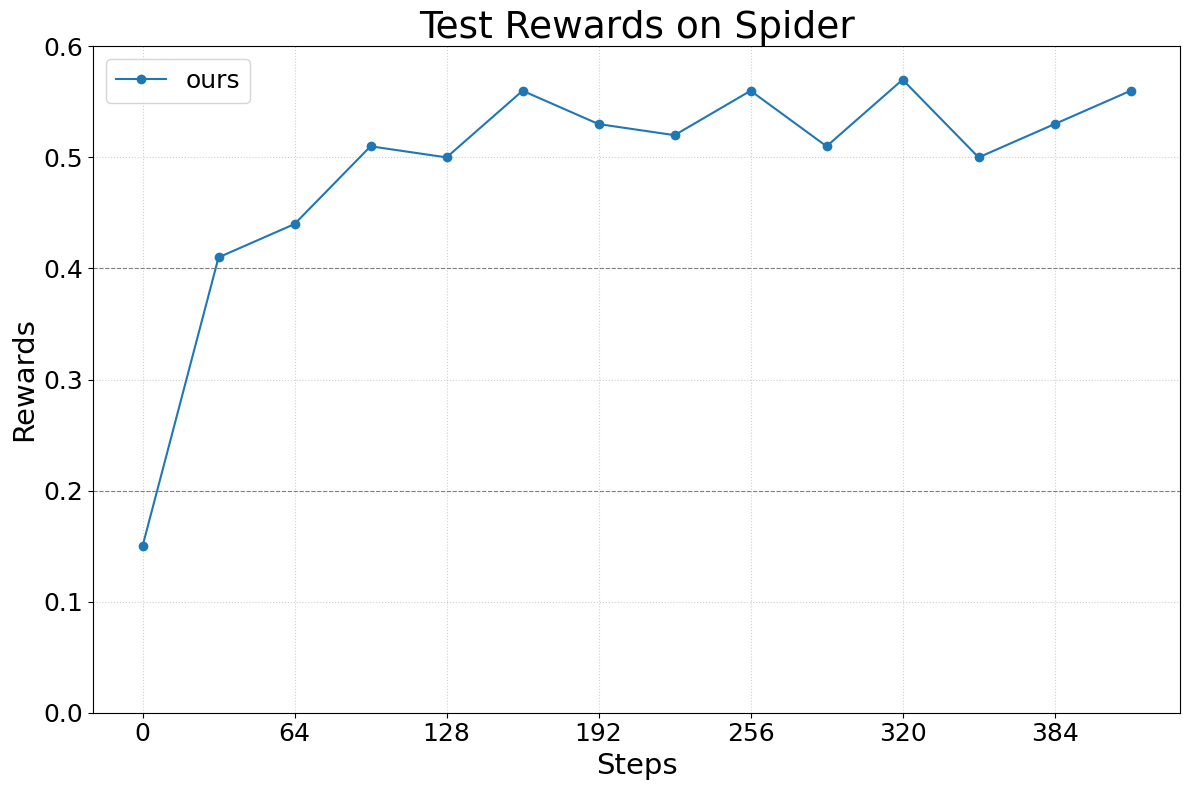
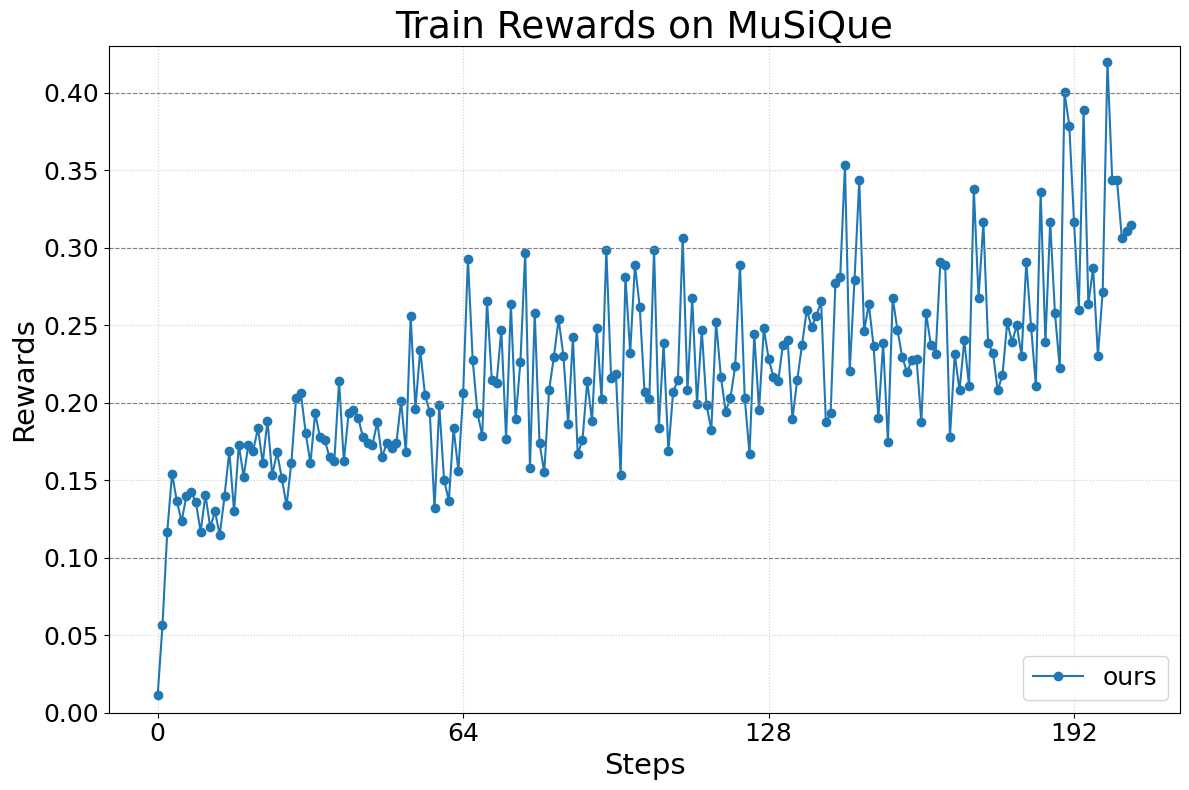
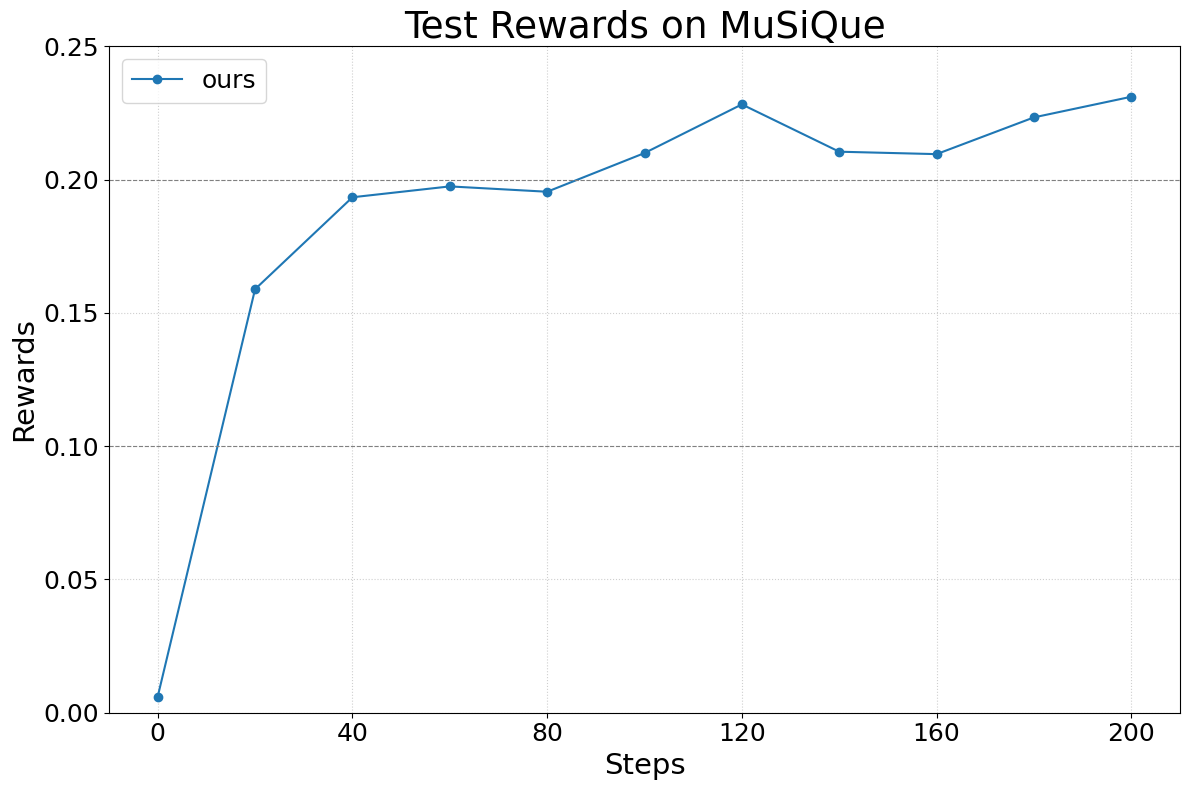
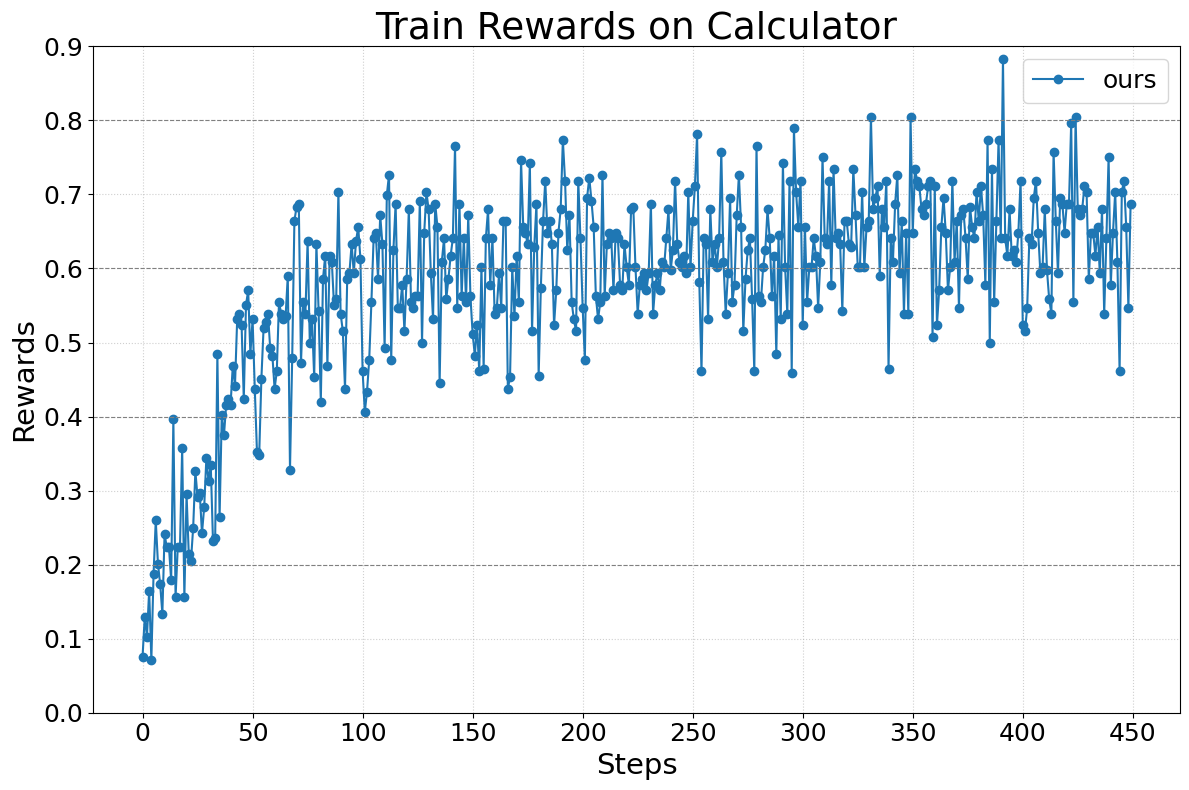
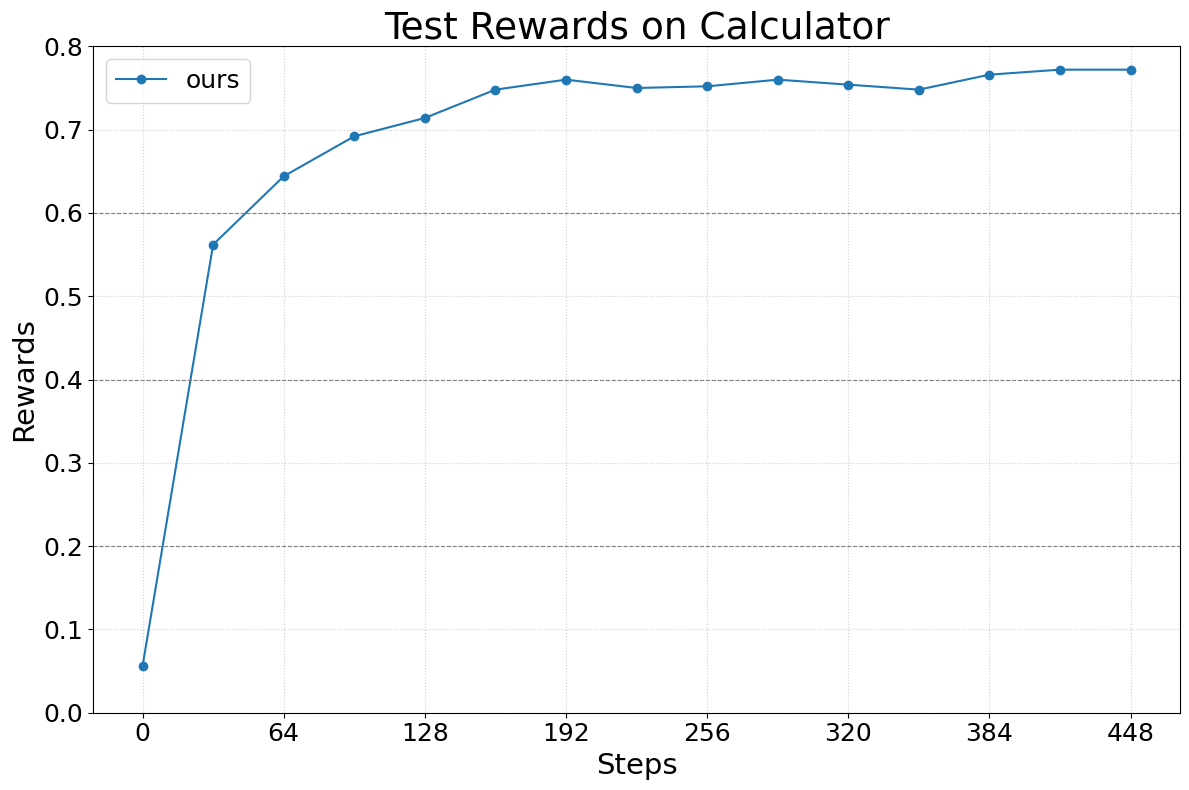
Abstract: We present Agent Lightning, a flexible and extensible framework that enables Reinforcement Learning (RL)-based training of LLMs for any AI agent. Unlike existing methods that tightly couple RL training with agent or rely on sequence concatenation with masking, Agent Lightning achieves complete decoupling between agent execution and training, allowing seamless integration with existing agents developed via diverse ways (e.g., using frameworks like LangChain, OpenAI Agents SDK, AutoGen, and building from scratch) with almost ZERO code modifications. By formulating agent execution as Markov decision process, we define an unified data interface and propose a hierarchical RL algorithm, LightningRL, which contains a credit assignment module, allowing us to decompose trajectories generated by ANY agents into training transition. This enables RL to handle complex interaction logic, such as multi-agent scenarios and dynamic workflows. For the system design, we introduce a Training-Agent Disaggregation architecture, and brings agent observability frameworks into agent runtime, providing a standardized agent finetuning interface. Experiments across text-to-SQL, retrieval-augmented generation, and math tool-use tasks demonstrate stable, continuous improvements, showcasing the framework's potential for real-world agent training and deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- Advantage estimate: A scalar used in policy gradient methods to weigh token log-probabilities, typically reflecting how much better an action performed compared to a baseline. "where is a token-level advantage estimate, and is the task set."
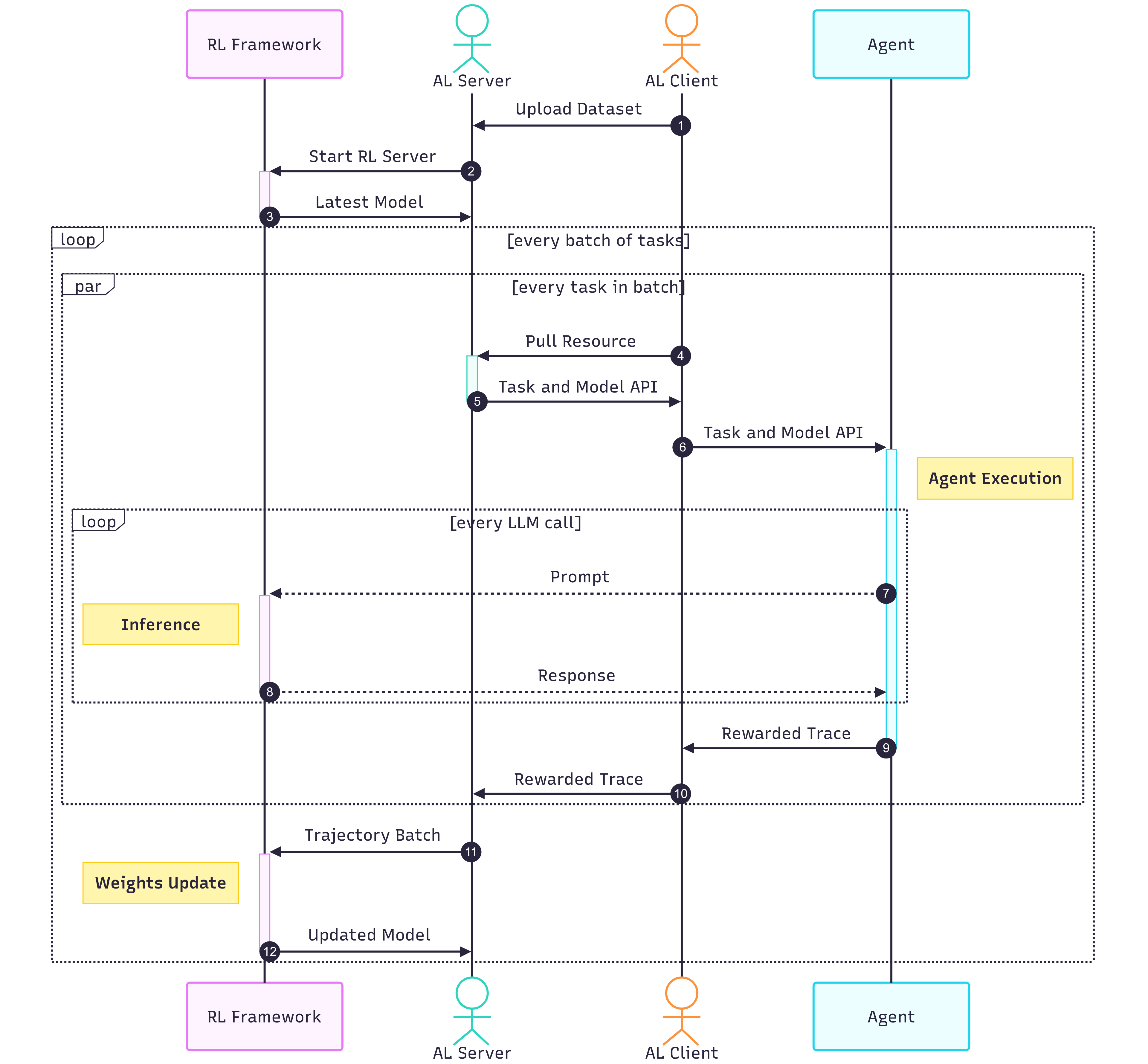
- Agent runtime: The execution environment that runs the agent, manages its operations, and collects data during training. "the other runs the agent and performs data collection, serving as the agent runtime."
- AgentOps: An observability and tracing toolkit for AI agents, used here to capture execution data without modifying agent code. "based on OpenTelemetry~\citep{OpenTelemetry} and AgentOps~\citep{AgentOps}."
- Automatic Intermediate Rewarding (AIR): A mechanism that converts system monitoring signals into intermediate rewards to mitigate sparse reward problems. "by the Automatic Intermediate Rewarding (AIR) mechanism."
- AutoGen: A framework for building multi-agent systems and tool-using agents. "a math question answering agent with tool usage developed via AutoGen."
- Batch accumulation: An optimization technique that accumulates gradients over multiple smaller batches to effectively train with long contexts or limited memory. "enabling the use of techniques like batch accumulation for efficient updates."
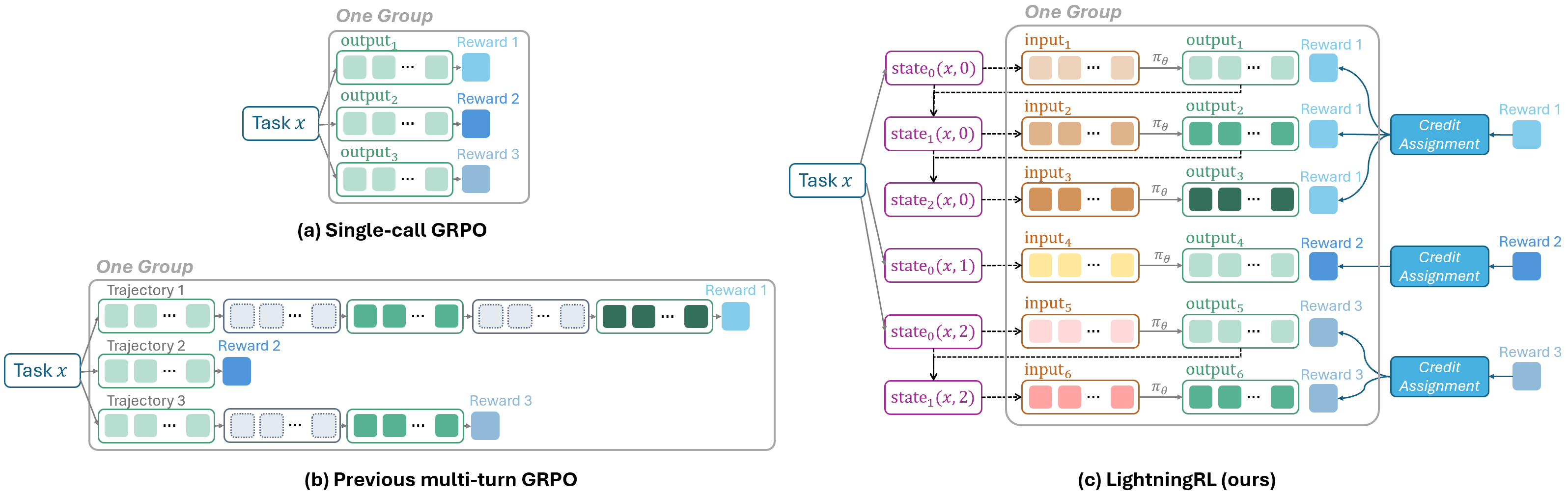
- Credit assignment module: A component that allocates trajectory-level returns to individual actions or transitions within an episode. "which contains a credit assignment module"
- Data parallelism: Running multiple instances of an agent concurrently to increase throughput during rollout. "leveraging data parallelism to maximize throughput and minimize latency."
- Directed acyclic graph (DAG): A graph with directed edges and no cycles, used to represent agent execution flows. "can be represented as a directed acyclic graph (DAG)"
- Event-driven system: A control mechanism where the server switches between generation and training based on events, enabling coordination with clients. "manages the transitions between generation and training stages using an event-driven system"
- GRPO: Group Relative Policy Optimization, a value-free RL algorithm that normalizes rewards across multiple samples for the same prompt. "In GRPO, samples generated from the same prompt are grouped to estimate the advantage."
- Hierarchical Reinforcement Learning (HRL): An RL approach that decomposes decision-making into multiple levels, here assigning credit at the action level then at the token level. "a simple hierarchical reinforcement learning (HRL) approach, called LightningRL."
- Inventory manner: A scheduling approach where the server maintains a record of available tasks and allocates them to clients as they are ready. "Task batches are dispatched to clients via an inventory manner"
- KL divergence: A regularization term that penalizes deviation from a reference policy during RL training. "such as importance sampling ratio, clipping, and KL divergence terms are omitted"
- LangChain: An orchestration framework for building LLM-powered applications and agents. "using frameworks like LangChain, OpenAI Agents SDK, AutoGen"
- LLMs: Transformer-based models trained on vast text corpora, used here as policy models within agents. "Reinforcement Learning (RL)-based training of LLMs for any AI agent."
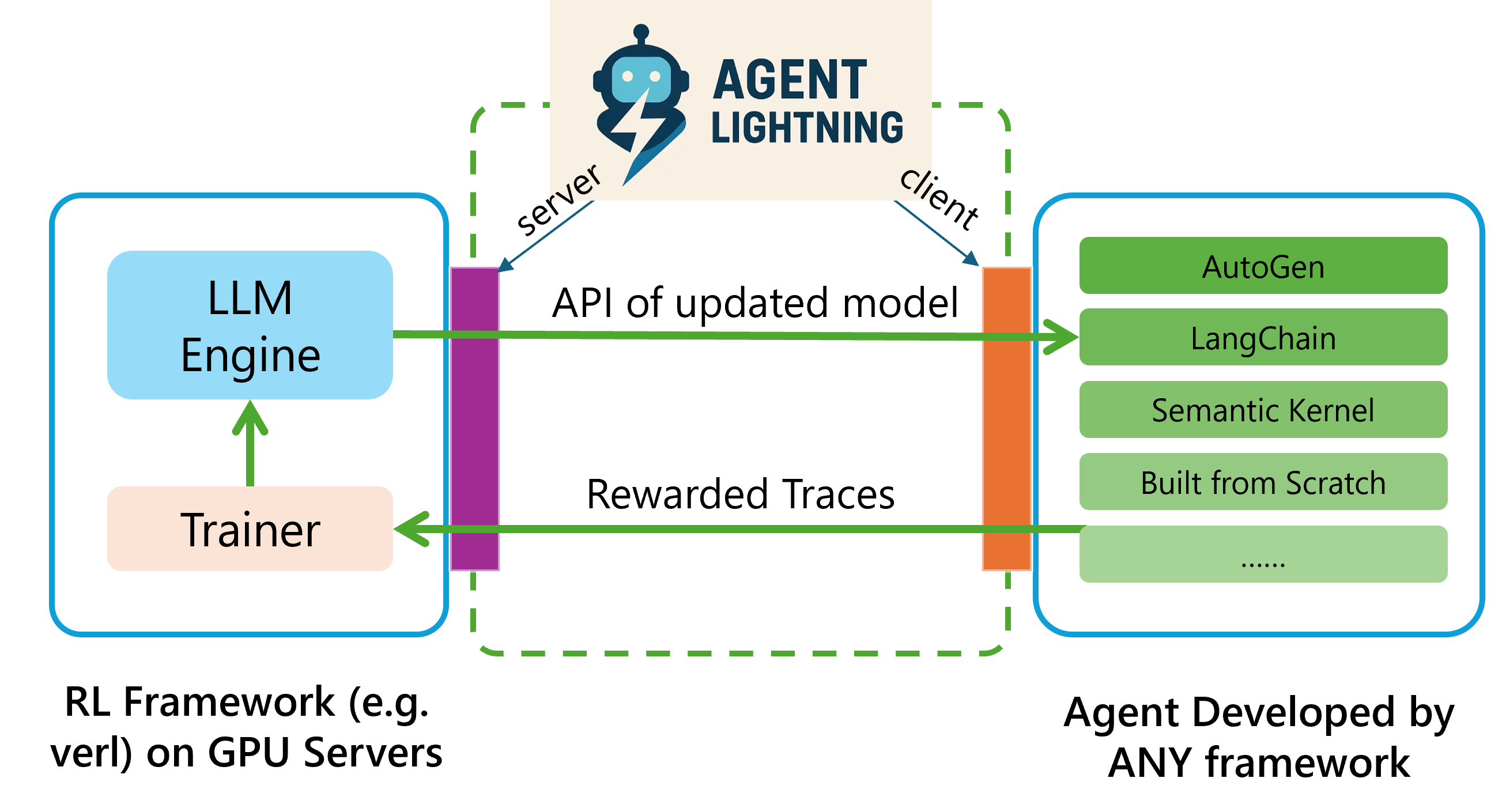
- Lightning Client: The client-side component that runs agents, captures trajectories, and communicates with the training server. "The Lightning Client comprises two functional components"
- Lightning Server: The server-side component that manages RL training, exposes an OpenAI-like API, and coordinates with clients. "The Lightning Server functions as the controller of the RL training system"
- LightningRL: The proposed hierarchical RL algorithm that decomposes agent episodes into transitions and integrates single-turn RL methods. "we introduce LightningRL, a hierarchical RL algorithm specifically designed for agent training."
- Markov Decision Process (MDP): A mathematical framework for modeling decision-making where outcomes depend on current state and action. "This decoupling is grounded in formulating agent execution as a Markov decision process (MDP)"
- MCP (Model Context Protocol): A standard protocol for tool and agent interoperability that structures tool interactions. "follow the MCP (Model Context Protocol)~\citep{mcp}"
- Multi-agent reinforcement learning (MARL): RL methods where multiple agents (policies) learn and interact simultaneously. "a more principled approach would use multi-agent reinforcement learning (MARL) or game theory"
- OpenAI Agents SDK: A toolkit for building agent workflows and tool integrations. "a retrieve-augmented generation agent built with OpenAI Agents SDK"
- OpenTelemetry: An open-source observability framework used to instrument and trace agent executions. "observability frameworks like OpenTelemetry~\citep{OpenTelemetry}"
- Partially Observable Markov Decision Process (POMDP): An extension of MDPs where the agent receives observations instead of full states. "we can model its decision-making process as a Partially Observable Markov Decision Process (POMDP)"
- Position encoding: Techniques for encoding token positions in transformer models to preserve sequence order. "which is assumed in the widely used position encoding approaches, such as Rotary Positional Embeddings (RoPE)"
- PPO: Proximal Policy Optimization, a widely used RL algorithm that stabilizes policy updates via clipping and value estimation. "Standard PPO~\citep{ouyang2022training} employs a learned critic model"
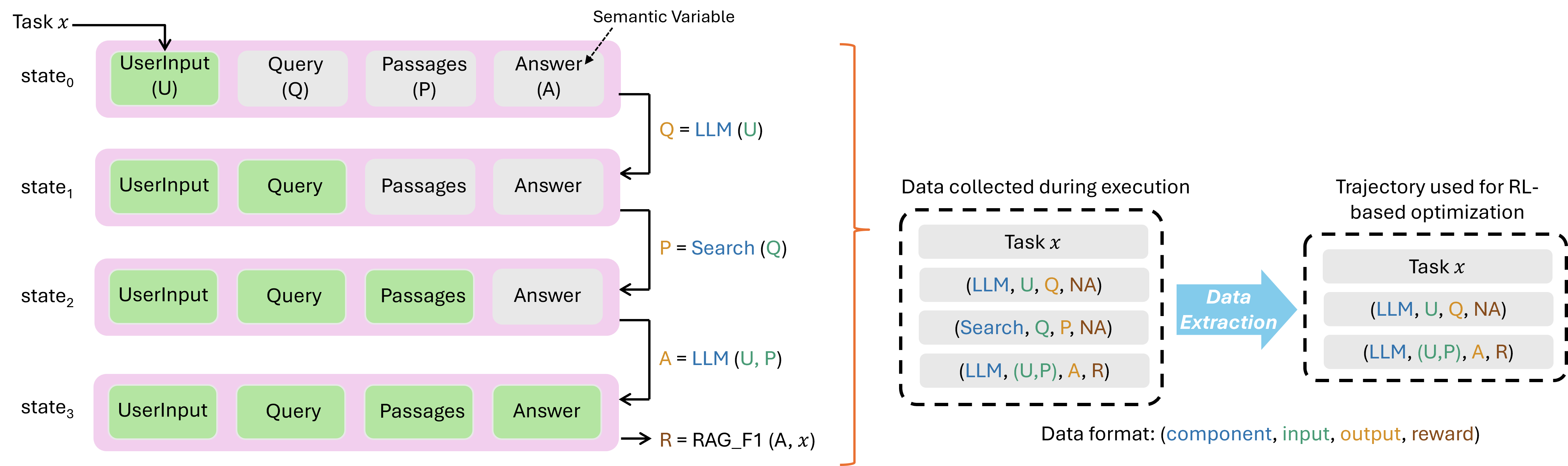
- RAG_F1: An evaluation and reward metric for RAG tasks that measures answer quality based on F1 score. "a reward function (e.g., RAG_F1) evaluates the quality of the generated Answer."
- Retrieval-Augmented Generation (RAG): A pattern where the model retrieves documents and grounds its answers in them. "retrieval-augmented generation agent built with OpenAI Agents SDK"
- REINFORCE++: A value-free RL method that uses batch-level baselines for advantage estimation. "Similarly, REINFORCE++~\citep{hu2025reinforce++} uses a simpler baseline"
- RoPE (Rotary Positional Embeddings): A position encoding method that rotates embedding vectors to encode relative positions. "Rotary Positional Embeddings (RoPE)~\citep{su2024roformer}"
- Rollout: The process of executing agents to collect trajectories used for training. "the rollout captures trajectories, which are data used by the trainer."
- Semantic Variable: A key variable in the agent’s state that captures meaningful program intent and is used by components. "which we call Semantic Variable~\citep{lin2024parrot}."
- SGLang: A serving framework for LLM inference. "SGLang~\citep{sglang}"
- Transition: A single step in an agent trajectory comprising the current input, the model output, and its reward. "Each transition contains the current state (LLM input), action (LLM output), and reward."
- Transition dynamics: The (often unknown) probabilistic rules that govern movement from one state to the next after an action. "defines the (usually unknown) transition dynamics to the new state"
- Unified data interface: A standardized schema capturing inputs, outputs, and rewards from agent calls for RL training. "we propose a unified data interface"
- vLLM: A high-throughput LLM serving system. "vLLM~\citep{vllm}"
- Value function: A learned estimator of expected return used for advantage computation in RL. "defining the advantage with a value function."
- Value-free methods: RL approaches that avoid training a critic/value function and instead use reward normalization or baselines. "especially value-free methods that are typically lightweight and efficient."
- VeRL: An RL training framework referenced as compatible with the proposed architecture. "the training framework (e.g., VeRL~\citep{sheng2024hybridflow}) agent-agnostic"
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented with little to no modification to existing agent code, taking advantage of Agent Lightning’s unified data interface, Training-Agent Disaggregation architecture, LightningRL, and observability-driven reward shaping.
- Enterprise RAG optimization (software, knowledge management)
- Use case: Fine-tune existing retrieval-augmented chatbots on internal corpora to improve query generation, passage selection, and grounded answer quality.
- Workflow/product: Lightning Client instruments LangChain/OpenAI Agents SDK-based RAG pipelines via OpenTelemetry; Lightning Server exposes an updated “shadow” model endpoint for A/B testing; AIR provides intermediate rewards from tool-call success/failure and citation checks.
- Assumptions/dependencies: Access to internal documents and telemetry; reward functions (e.g., groundedness, citation match, factuality); GPU capacity for RL; privacy-compliant logging.
- Text-to-SQL agents on private databases (data platforms, analytics, finance)
- Use case: Train SQL assistants to generate more accurate queries for BI dashboards, ad-hoc analytics, and operational reporting.
- Workflow/product: Integrate with existing LangChain SQL agents and DB executors; use execution success, schema-consistency checks, and query runtime/errors as AIR signals; employ RL loops with minimal code changes.
- Assumptions/dependencies: Well-defined success metrics (execution success, result accuracy); safe DB sandboxes; telemetry on query runtime/errors; change-management to prevent damaging writes.
- Tool-use math and calculation assistants (education, productivity)
- Use case: Improve multi-step calculation agents that use external calculators or symbolic tools for homework support, accounting checks, or engineering calculations.
- Workflow/product: AutoGen-based tool-use agent trained via LightningRL; AIR from tool-call status and equivalence checks; expose updated endpoint for downstream apps.
- Assumptions/dependencies: Robust correctness/consistency reward; tool availability and reliability; user privacy for logged inputs.
- Production agent performance tuning without refactoring (software engineering, DevOps)
- Use case: Add a training layer to existing agents (e.g., workflow or multi-agent systems) with “almost ZERO” code changes to improve task completion rates and latency.
- Workflow/product: Training-Agent Disaggregation enables remote RL training while agents run in place; inter/intra-node parallel rollouts; OpenTelemetry tracing and error handling; batch accumulation from transition-level data.
- Assumptions/dependencies: Existing agent frameworks (LangChain, AutoGen, OpenAI Agents SDK); telemetry availability; defined rewards; compute budget.
- Prompt and policy optimization as first-class knobs (software tooling)
- Use case: Selective optimization of prompts/roles in multi-agent workflows without changing orchestration code.
- Workflow/product: LightningRL transition-level grouping by task and call; reward-based credit assignment per call; prompt variants tracked and tuned via the unified interface.
- Assumptions/dependencies: Clear per-call rewards (or proxies); versioning for prompts/models.
- Observability-driven reward shaping libraries (MLOps)
- Use case: Build AIR policies that convert monitoring signals (tool API statuses, timeouts, format validation, citation checks) into intermediate rewards to mitigate sparsity.
- Workflow/product: AgentOps/OpenTelemetry traces mapped to rewards; configurable reward adapters per tool; consistent schema for state/call logging.
- Assumptions/dependencies: High-quality, consistent monitoring; careful calibration to avoid reward hacking; governance for reward policies.
- Safe rollout at scale with robust error handling (IT operations)
- Use case: Run large-batch RL rollouts across heterogeneous infrastructure while gracefully handling crashes/timeouts.
- Workflow/product: Lightning Client’s two-level parallelism; retry/reassign mechanisms; detailed error logs; inventory-based task dispatch; updated models served via OpenAI-like endpoints.
- Assumptions/dependencies: Distributed coordination; task queueing; observability; standardized failure modes and retries.
- Academic benchmarking of agent RL (research)
- Use case: Rapidly test RL methods on diverse agent tasks (text-to-SQL, RAG QA, tool-use math) with unified trajectories and credit assignment.
- Workflow/product: LightningRL transitions enable plug-and-play with PPO/GRPO/REINFORCE++; dataset/task scaffolding; reproducible pipelines via disaggregated training.
- Assumptions/dependencies: Access to tasks/rewards; compute; careful documentation of state/observation choices.
- Policy and compliance auditability for agent training (governance)
- Use case: Use standardized observability traces to produce audit trails of agent decisions and training signals for compliance and incident review.
- Workflow/product: OpenTelemetry-based agent traces; documented reward sources (AIR rules); versioned model endpoints; opt-in privacy controls.
- Assumptions/dependencies: Organizational policies for telemetry retention; PII handling; clear audit requirements.
- Personal productivity assistants with self-improving workflows (daily life)
- Use case: Adapt personal assistants to user preferences for search, summarization, and task planning using implicit rewards (click-through, task completion, time saved).
- Workflow/product: Local or hosted Lightning Client captures tool outcomes (calendar updates, email sends); Shadow model endpoint for A/B comparisons; per-user reward proxies.
- Assumptions/dependencies: Consent for telemetry; lightweight reward proxies; privacy-preserving storage.
Long-Term Applications
The following applications require further research, scaling, safety validation, new tooling, or ecosystem development.
- Continuous self-improving agents in production (software, SaaS)
- Concept: Closed-loop training that learns from live interactions and telemetry to continually improve agents.
- Potential product/workflow: “Train-in-the-loop” service with gated deployment, automated A/B, rollback, and reward drift monitoring.
- Dependencies: Strong safety guardrails, bias/fairness monitoring, drift detection, privacy-preserving data pipelines, cost control.
- Multi-LLM coordination via MARL (multi-agent systems, robotics, complex workflows)
- Concept: Train multiple specialized LLMs jointly with cooperative/competitive objectives for planning, tool dispatch, and negotiation.
- Potential product/workflow: MARL orchestration where each agent has its own policy/reward; learned credit assignment and coordination graphs.
- Dependencies: Stable MARL algorithms for LLMs, credit assignment research, inter-agent communication standards, safety constraints, compute scale.
- Learned credit assignment and high-level value functions (RL methodology)
- Concept: Move beyond equal-credit heuristics to learned per-call value estimates and hierarchical critics.
- Potential product/workflow: Value models that predict call-level returns; off-policy training with logged transitions; task-specific reward modeling.
- Dependencies: Labeling or self-supervised signals; robust training that avoids reward hacking; interpretability tools.
- Sector-specific safety-constrained RL (healthcare, finance, public sector)
- Concept: Train agents under domain constraints (e.g., medical correctness, regulatory compliance) with multi-objective rewards.
- Potential product/workflow: Constrained RL and safe exploration; policy shields and validator tools; formal checks integrated as AIR signals.
- Dependencies: High-quality validators, domain approvals, liability frameworks, rigorous evaluation protocols.
- Standardized agent observability and reward schemas (ecosystem, policy)
- Concept: Industry standards for agent telemetry (state/call schemas), reward definition, and audit trails.
- Potential product/workflow: Open standards based on OpenTelemetry/MCP for tool interactions and reward adapters; certification processes.
- Dependencies: Cross-vendor collaboration; regulatory buy-in; privacy/security standards.
- Federated/privacy-preserving agent training (data governance)
- Concept: Train on decentralized, sensitive data with privacy guarantees (DP, federated RL, secure enclaves).
- Potential product/workflow: Federated Lightning Clients running local rollouts; privacy-preserving reward aggregation; secure endpoint serving.
- Dependencies: Privacy tech maturity, performance overhead management, legal/regulatory alignment.
- Large-scale environment and reward services (platforms, cloud)
- Concept: Serverless pools of heavy environments (e.g., mobile emulators, complex simulators) and reward computation services.
- Potential product/workflow: Elastic environment pools with autoscaling; reward microservices; cost-aware orchestration.
- Dependencies: Cloud infra, scheduler design, latency/QoS controls, cost predictability.
- Tool ecosystem and MCP-native training (developer tooling)
- Concept: Rich libraries of tool-side reward adapters, schema validators, and training hooks integrated with MCP/agent protocols.
- Potential product/workflow: “Reward SDKs” for common tools (DBs, search, code execution, CRM); standardized adapter marketplace.
- Dependencies: Tool vendor participation; stable MCP/agent APIs; developer adoption.
- Human-in-the-loop hybrid training (education, enterprise support)
- Concept: Combine AIR and automated rewards with selective human feedback for hard cases, policy violations, or rare events.
- Potential product/workflow: Reviewer queues integrated into rollouts; disagreement detection; calibration of human rewards.
- Dependencies: Annotation budgets, reviewer interfaces, active learning policies, quality control.
- Edge and embedded agent training (IoT, mobile)
- Concept: Train agents that interact with edge devices/tools, with local AIR signals from device telemetry.
- Potential product/workflow: Lightweight Lightning Clients on edge; on-device reward proxies (battery, latency, error rates); periodic sync to Server.
- Dependencies: Resource constraints, connectivity, on-device privacy, compact RL algorithms.
Notes on Feasibility and Dependencies
Across both immediate and long-term applications, key assumptions and dependencies include:
- Reward availability and design: Terminal rewards and robust AIR proxies are critical; reward hacking risks must be mitigated.
- Telemetry and observability: Reliable, privacy-compliant logging of states/calls (OpenTelemetry/AgentOps) is foundational.
- Compute and cost: RL training requires GPUs and scalable rollouts; batching and transition-level processing reduce cost but do not eliminate it.
- Safety and governance: Monitoring for harmful behavior, policy violations, and bias is necessary, particularly in regulated sectors.
- Integration constraints: Compatibility with existing agent frameworks (LangChain, OpenAI Agents SDK, AutoGen) and tool protocols (MCP) impacts adoption.
- Data governance: Consent, PII handling, retention policies, and auditability must be addressed before production deployment.
Collections
Sign up for free to add this paper to one or more collections.