- The paper introduces AgentFly, a framework that integrates reinforcement learning with LM agents using token-level masking to isolate agent outputs.
- It presents a decorator-based interface to simplify tool and reward integration while employing asynchronous rollouts with centralized resource management.
- Experimental results demonstrate improved reward trajectories across RL algorithms, though discrete token evaluations can lead to instability in some models.
AgentFly: Extensible and Scalable Reinforcement Learning for LM Agents
AgentFly is a framework aimed at expanding the capabilities of LLM agents by integrating reinforcement learning (RL) approaches. It addresses the challenges in the union of LM agents and RL through scalable and extensible design choices, allowing LM agents to effectively leverage reinforcement learning strategies.
Introduction to AgentFly Framework
AgentFly tackles the problem of multi-turn interactions in RL setups by introducing token-level masking, enabling the framework to learn solely from the agent's outputs without interference from external elements. This approach is vital for distinguishing the agent's generated tokens from environmental observations and other components within a trajectory.
Additionally, the framework employs a decorator-based interface for tool and reward definitions. This design simplifies the integration and extension processes, making the framework accessible for developers aiming to customize tool and reward functions without exploring detailed training configurations.
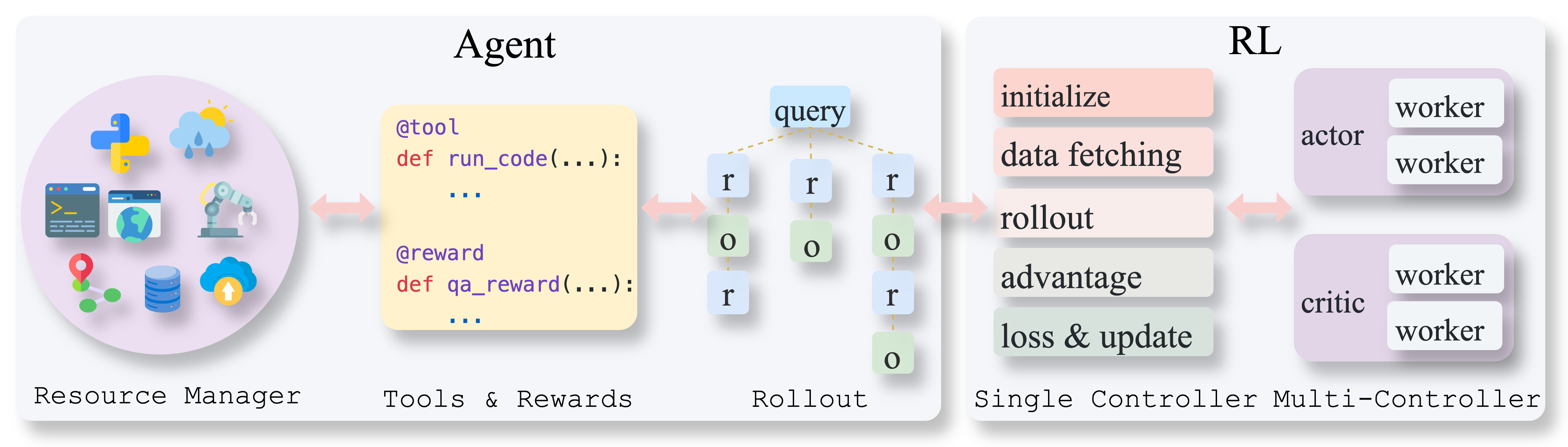
Figure 1: Overview of the AgentFly training framework. The left part follows the standard RL training setup in Verl. The right part illustrates the extension for agent rollout, including the chain run logic, dynamic tool and reward systems, and interactions with a shared resource pool.
AgentFly adopts a practical approach to handle complex multi-turn interaction trajectories. The RL algorithms are modified to mask out non-LM-generated tokens, ensuring RL optimization remains focused on the agent's actions.
The tool system within AgentFly is designed to streamline interaction processes by using tools as abstractions that represent all interfaces, including functions, APIs, and environmental elements. This abstraction unifies interaction processes, formalizing the interaction between agents and external environments through systematic tool invocations.
For asynchronous rollouts, the framework leverages the vllm engine server integration, ensuring high throughput without blocking interactions—crucial for maintaining efficiency in environments demanding concurrent tool usage.
Environment Resource Management
AgentFly incorporates a centralized resource management system for orchestrating environment instances. Each stateful tool is associated with a dedicated environment instance, managing lifecycle events such as initiation, execution, and recycling. This ensures parallelism and scalability across tool and environment interactions, vital for processing expansive and dynamic observational data during RL tasks.
AgentFly includes various prebuilt tools and environments, catering to a range of task complexities:
- Code Interpreter: Executes code within an isolated container environment.
- Search and Retrieve Tools: Utilize APIs for information retrieval and web searching, optimizing search operations with caching mechanisms.
- ALFWorld and ScienceWorld: Complex simulators for embodied task management, offering substantial interaction diversity.
These components are preconfigured to support robust RL agent training within different scenarios, providing a scalable infrastructure for testing various models and algorithms.
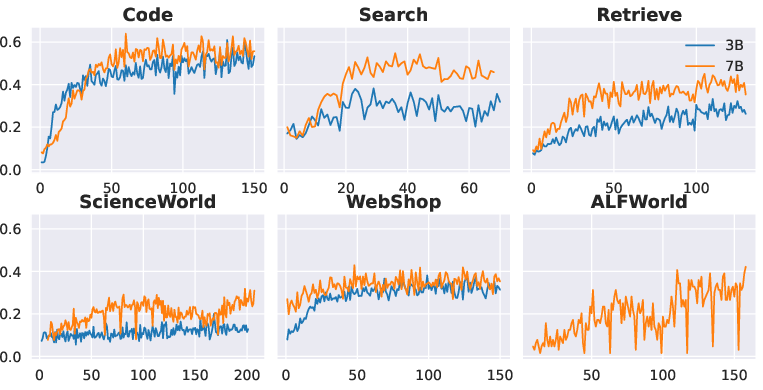
Figure 2: Reward curves for Qwen2.5-Instruct 3B and 7B models. For ALFWorld, we find it is too difficult for the 3B model, and the reward keeps around zero during training.
Experimental Evaluation
AgentFly's evaluation involves integrating four dominant RL algorithms within the framework: PPO, REINFORCE++, GRPO, and RLOO. The framework demonstrates versatile capacity across different model scales and complexity levels, highlighting rapid reward improvements and stable learning trajectories in shorter interaction sequences.
Interestingly, experiments reveal REINFORCE++ experiencing more instability compared to other algorithms, attributed to discrete token-level advantages impacting learning consistency—an area for further investigation on model-specific configurations.
In environment-specific tasks, such as ALFWorld and ScienceWorld, findings indicate slower reward progression compared to simpler tool usage scenarios, pointing to the heightened challenge in handling extended multi-turn sequences.
Implications and Future Developments
AgentFly sets a prominent foundation for advancing LM agent capabilities through systemic RL integration. While current implementations highlight the scalability and flexibility of AgentFly, future advancements could explore optimizing token-level evaluations, enhancing asynchronous processing mechanisms, and integrating novel RL methodologies for further performance gains.
The potential to support increasingly complex scenarios makes AgentFly a significant contributor to the development of adaptive and efficient LM agents. As models evolve, the framework may incorporate more diverse environments and task agents, broadening the scope of RL-enable LM agent applications.
Conclusion
AgentFly provides an adaptable and scalable RL framework for training LM agents across multi-turn interactions. By incorporating asynchronous tool systems and centralized resource management, the platform supports rigorous agent development processes, facilitating efficient tool and environment coupling. Empirical results underscore the potential for diverse Agent-RL setups, suggesting promising future directions for enhancing reasoning and task management capabilities in LLM agents.