AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Abstract: Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AgentGym-RL, a “training gym” for AI assistants (LLM agents) that must solve tasks that take many steps, like browsing the web to book a flight or playing a strategy game. Instead of learning from lots of example answers, these agents learn by trial and error—just like a person practicing a sport and getting feedback after each try. The authors also propose a new training strategy, called ScalingInter-RL, that helps these agents learn safely and steadily by starting with short practice sessions and gradually allowing longer ones.
What questions did the researchers ask?
The researchers focused on four simple questions:
- How can we build one flexible, practical training system that lets AI agents learn by interacting with many different kinds of environments (websites, games, science simulators) over multiple steps?
- Can these agents learn “from scratch” with reinforcement learning (RL)—without first being taught with example answers—and still do well on real tasks?
- How do we balance “exploring new ideas” vs. “sticking with what works” so training is both stable and effective?
- Can a smaller, open-source model trained well with RL match or beat bigger, commercial models on multi-step tasks?
How did they do it?
The team built a framework (AgentGym-RL) and a training approach (ScalingInter-RL). Here’s the idea in everyday language:
What is an LLM agent and multi-turn tasks?
An LLM agent is like a smart digital helper that can think through a task step by step. Multi-turn (or “long-horizon”) tasks need many actions in a row. For example, to “plan a trip,” the agent might:
- search for flights,
- compare prices,
- check dates,
- book tickets. Each step depends on what happened before.
What is reinforcement learning (RL)?
Reinforcement learning is learning by doing. The agent tries actions, sees what happens, and gets a score (a “reward”) at the end—higher if it completed the task well, lower if not. Over time, it learns which decisions lead to better results, similar to learning a game by playing it many times.
- Exploration means trying new strategies to discover better ways.
- Exploitation means using strategies that are already known to work. Good training balances both.
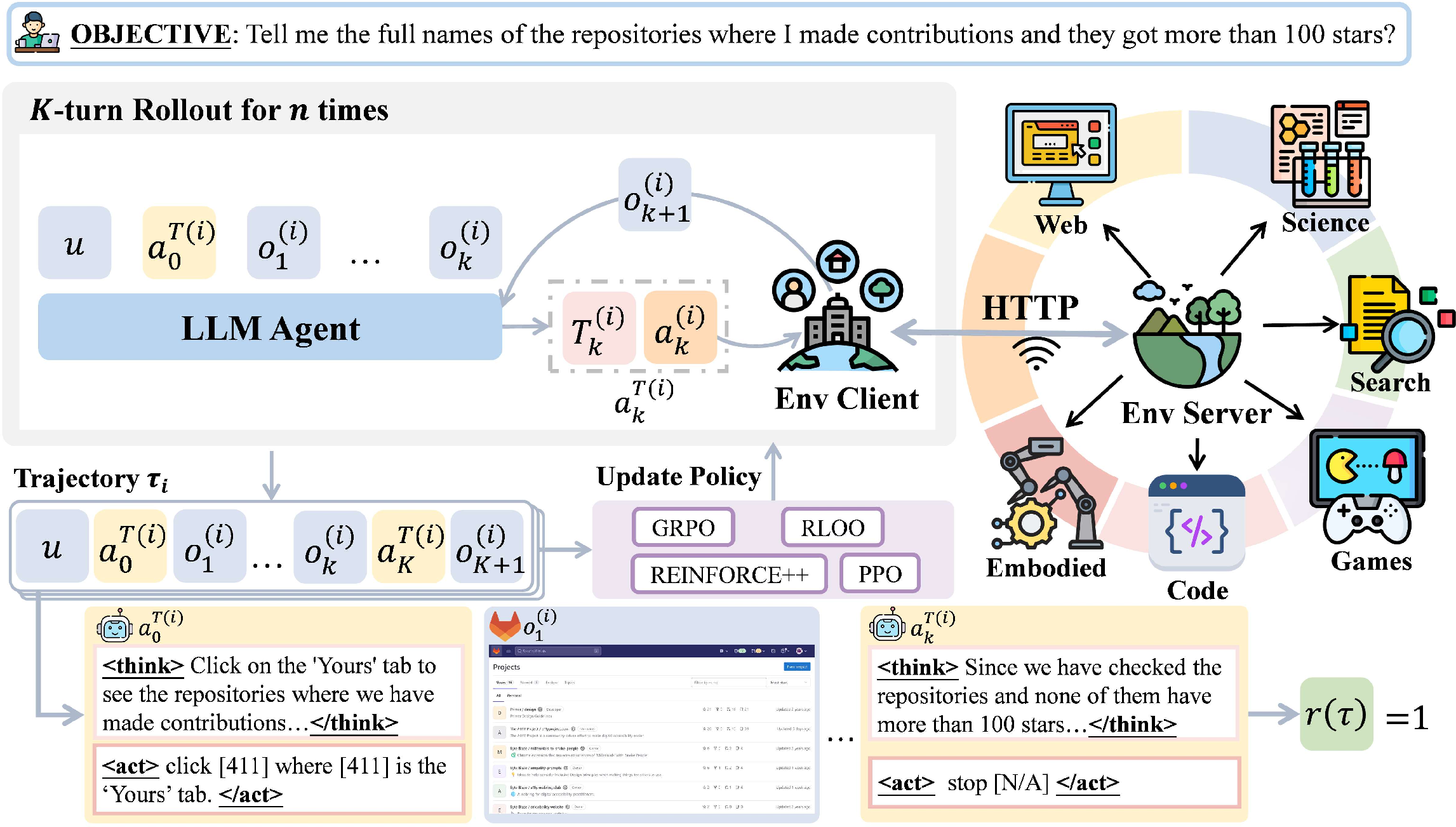
The AgentGym-RL framework: a “training gym” for agents
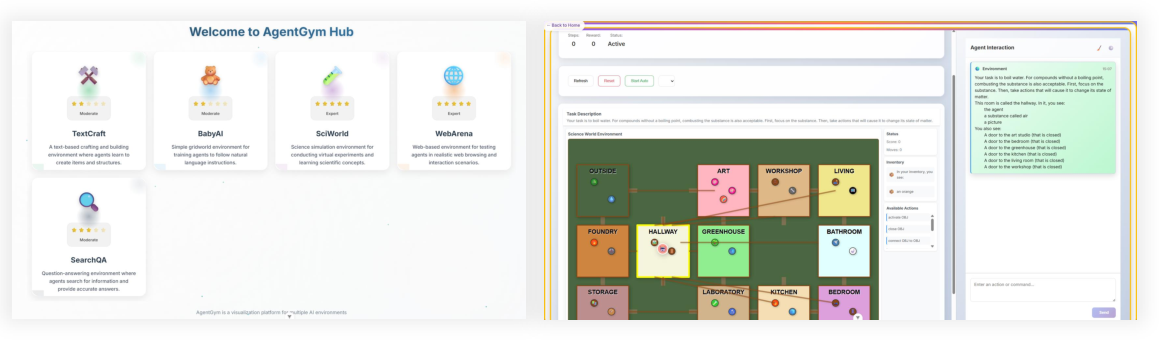
AgentGym-RL is organized into three plug-and-play parts, like stations in a training facility:
- Environment: the place where the agent acts (websites, search tools, games, robot-like grid worlds, science labs). The paper includes five kinds:
- Web navigation: use real websites to follow instructions.
- Deep search: ask the web multiple questions to find answers.
- Digital games: text-based puzzle/crafting games.
- Embodied tasks: move and act in a small virtual world following commands.
- Scientific tasks: run virtual experiments and reason about results.
- Agent: the brain that reads observations and chooses actions step by step. It can plan ahead and reflect on mistakes.
- Training: the coach that improves the agent using RL. They support well-known RL “coaching styles” (like PPO, GRPO, REINFORCE++), which are standard ways to safely adjust the agent’s behavior based on rewards.
They also engineered the system to run many training episodes in parallel, fixed memory issues in some environments, and built a visual interface to replay what the agent did—so researchers can watch, debug, and improve it. Everything will be open-sourced to help the community.
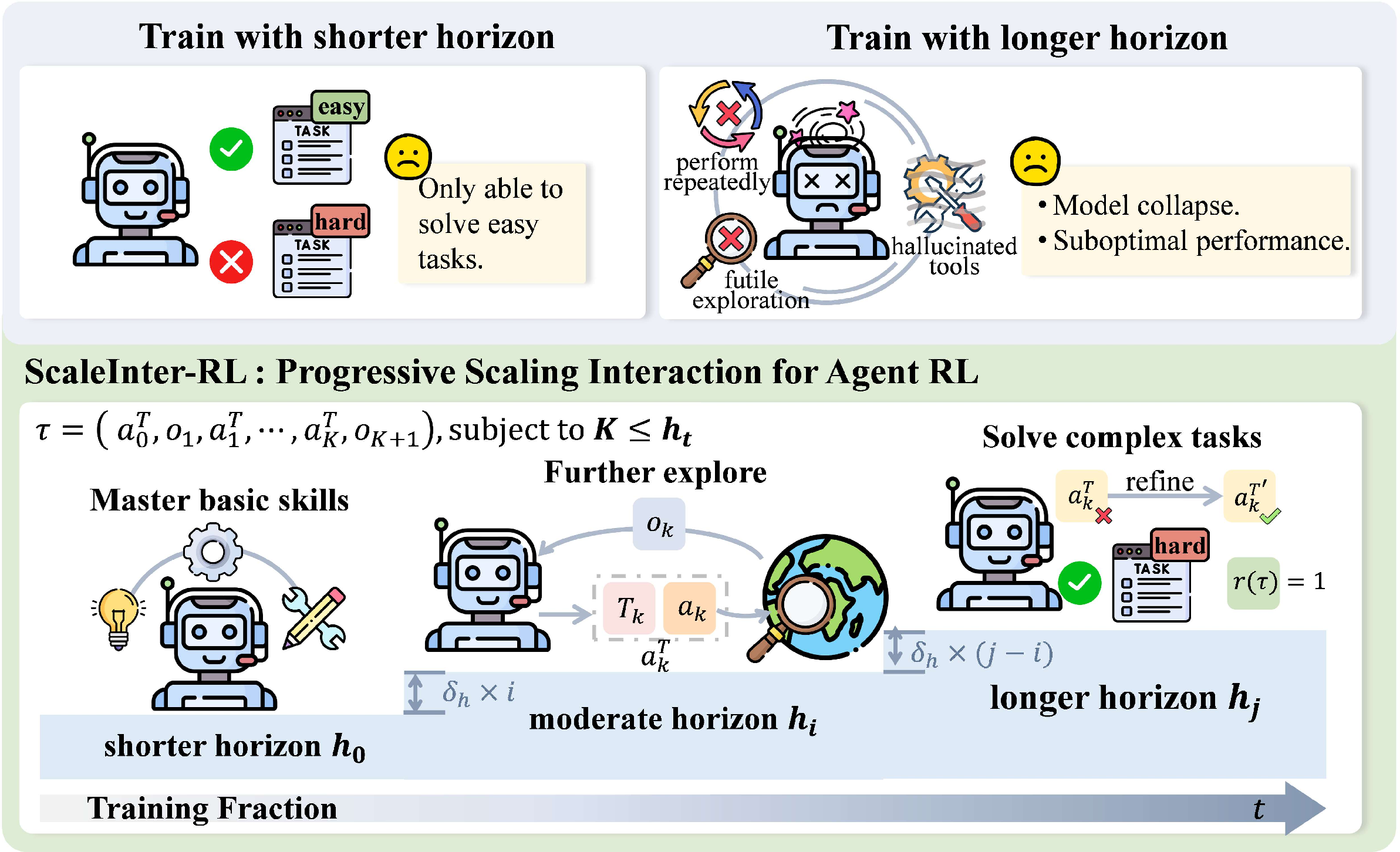
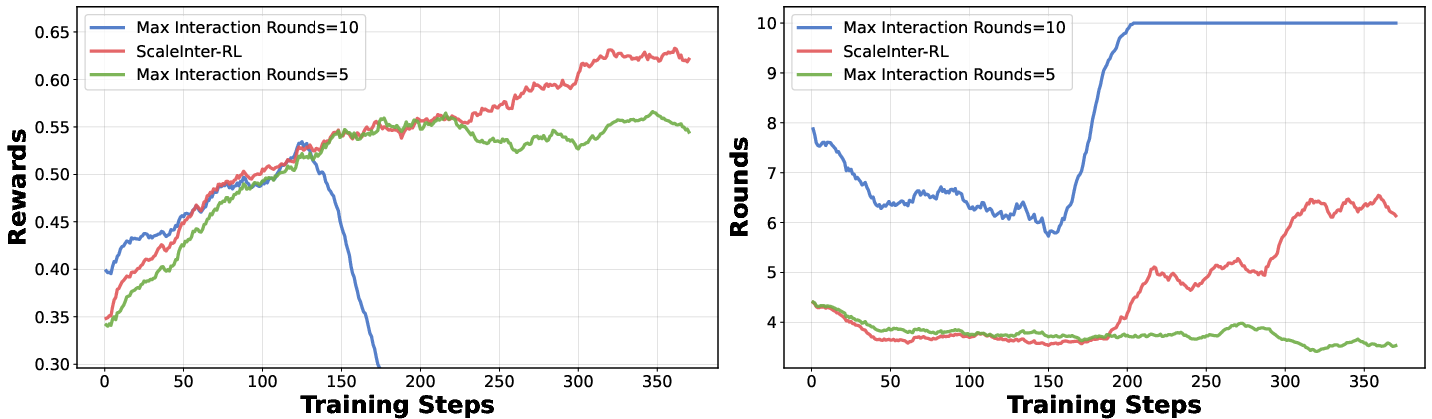
The ScalingInter-RL training strategy: start short, grow longer
Imagine learning a new game. If you play super long, messy sessions at the start, you might get confused and pick up bad habits. If you only practice tiny bits forever, you’ll never master full levels. ScalingInter-RL solves this by:
- Phase 1: Short interactions. The agent practices quick, simple runs, focusing on “what works” (exploitation). This builds reliable basic skills.
- Phase 2+: Gradually longer interactions. The agent is allowed more steps each time, encouraging exploration, planning, backtracking, and more complex strategies—without collapsing into chaos.
This “short first, longer later” schedule keeps training stable and pushes performance higher over time.
What did they find, and why does it matter?
- Reinforcement learning from scratch works across many tasks. The agents learned directly from feedback in realistic environments (no initial supervised fine-tuning required) and became strong decision-makers.
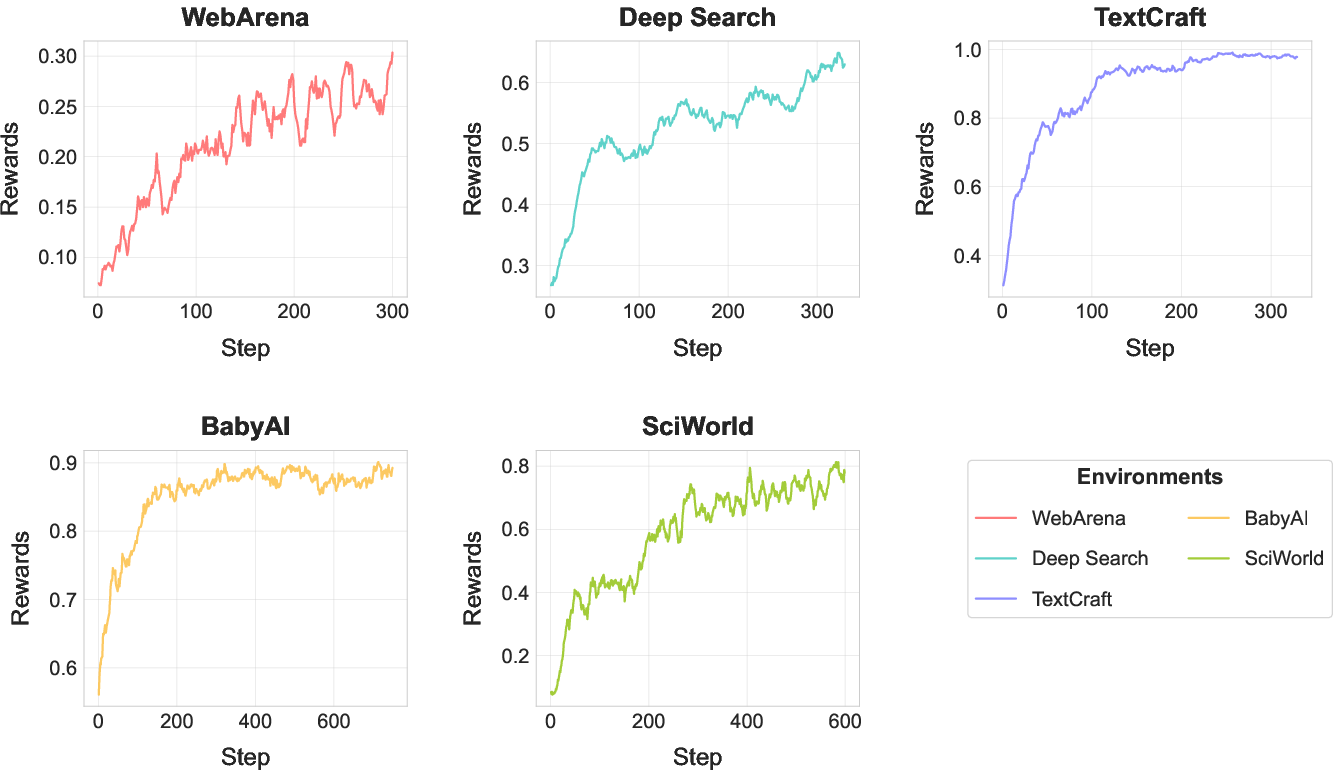
- The new schedule (ScalingInter-RL) consistently improved results. Starting short and scaling up made training steady and effective. Always short hit a ceiling; always long often collapsed. The progressive schedule beat both.
- A smaller, well-trained model can rival or beat bigger ones. A 7-billion-parameter open-source model trained with AgentGym-RL matched or surpassed commercial models on 27 tasks across web browsing, deep search, games, embodied, and science tasks. In some cases it even outperformed much larger open-source models (like 70B+ parameters). This suggests that smart training and allowing more “thinking/action steps” can matter more than just making models bigger.
- Clear, rule-based environments saw the biggest boosts. Tasks with structured rules (like the TextCraft game, BabyAI, and the ScienceWorld simulator) showed huge gains. Messier, open-ended environments (like real websites and web search) still improved, but they’re harder because real-world noise makes learning optimal strategies tougher.
- Engineering and openness matter. The framework is modular, scalable, and built to be reliable over long runs. It includes visualization tools and standardized evaluation, and it will be open-sourced—helping others reproduce, compare, and extend the work.
What are the broader implications?
- Better multi-step AI assistants: This work moves us closer to agents that can reliably complete complicated tasks in the real world—like handling online errands, doing research, or helping with lab-like procedures.
- Training > size, in many cases: The study shows that how you train (and how much thinking/action time you give the agent) can matter more than just making the model huge. This is useful for teams with limited compute who want top-tier performance.
- A shared foundation for research: By releasing a unified, robust framework with many environments and standard RL methods, the paper provides a common “gym” where researchers can build, compare, and improve agents more quickly and fairly.
- Paths to safer, steadier learning: The ScalingInter-RL approach offers a practical recipe for stable training on long, complex tasks—something many agent systems struggle with.
Key terms explained (in simple words)
- Multi-turn or long-horizon: Tasks that require many steps/actions in a row to finish.
- Reinforcement Learning (RL): Learning by trial and error—try actions, get feedback (reward), get better over time.
- Reward: A score from the environment telling the agent how well it did.
- Exploration vs. Exploitation: Trying new strategies vs. using what already works. Good training balances both.
- PPO/GRPO/REINFORCE++: Popular RL methods—think of them as different coaching techniques to safely and steadily improve the agent during training.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concise list of missing pieces, uncertainties, and unexplored directions that, if addressed, could strengthen the work and guide future research.
- Reward design is under-specified across environments (e.g., terminal vs. step-wise rewards, shaping strategies, penalty terms); concrete definitions and ablations per task are needed to clarify credit assignment and variance.
- ScalingInter-RL’s horizon schedule is not operationalized (e.g., how to set h0, δh, Δ, stopping criteria); no ablation over schedule shapes (linear, exponential, performance-triggered) or adaptivity based on learning progress.
- No theoretical analysis of ScalingInter-RL (e.g., bias–variance tradeoffs, convergence properties, conditions for monotonic improvement, relation to curriculum learning and horizon-induced variance reduction).
- Compute and sample efficiency are unreported (wall-clock time, tokens/steps, GPU hours/energy, rollouts per update); scaling laws vs. compute and interaction budget remain unknown.
- Generalization beyond trained tasks/environments is unclear (cross-task splits, cross-domain transfer, out-of-distribution robustness, catastrophic forgetting when adding new scenarios).
- Fairness of baseline comparisons is uncertain (test-time compute and action budgets, interaction horizons, tool access, retrial policies) across proprietary/open-source models; need standardized, budget-matched evaluation.
- The role of critics and advantages is not disentangled (PPO/GRPO vs. REINFORCE++); missing ablations on value-learning, KL control, entropy schedules, and their interaction with horizon scaling.
- No exploration bonuses or intrinsic motivation are used; open question: how curiosity, coverage penalties, or state-novelty metrics interact with progressive horizon scaling in long-horizon tasks.
- Memory mechanisms are not detailed (episodic memory, retrieval, long-context caching); unclear how persistent knowledge across turns/episodes influences performance and stability.
- Safety and reliability under real-world noise and failures (tool/API errors, network latency, UI drift, broken links) are not systematically evaluated; recovery and fallback strategies are unspecified.
- Real web generalization is untested; WebArena is sandboxed and may not reflect live-site variability, access restrictions, CAPTCHAs, or changing DOM structures.
- Visual grounding for web tasks is under-addressed (image/GUI understanding); it is unclear whether models are text-only (DOM/ARIA extraction) or truly multimodal; impact on tasks requiring visual perception is unknown.
- Multi-agent or collaborative decision-making (coordination, role allocation, communication protocols) is not explored; potential benefits to complex web/science tasks remain open.
- Reward hacking and shortcut behaviors are not audited; need diagnostics to detect spurious strategies, evaluator exploitation, or gaming of environment-specific metrics.
- Human preference alignment is not investigated (DPO or RLHF variants for agentic behavior quality, safety, and user satisfaction) and how it trades off with task rewards in multi-turn settings.
- Off-policy data reuse and replay are unsupported; opportunity to improve sample efficiency with mixed on-/off-policy pipelines, prioritized replay, or dataset aggregation is unexplored.
- Continual and lifelong learning is unaddressed (stability–plasticity, rehearsal, elastic weight consolidation) when adding new environments or increasing horizons over time.
- Policy transfer and distillation are not studied (e.g., distilling long-horizon skills from 7B to 3B, or warm-starting larger models with smaller RL-trained agents).
- Hyperparameter sensitivity is not reported (KL coefficients, entropy bonus, clipping ranges, batch sizes, λ/γ settings) nor robustness across environments/seeds; confidence intervals and multiple runs are missing.
- Agent architecture is insufficiently specified and ablated (planning, reflection, tool-use prompting, memory, self-correction loops); which components drive gains remains unclear.
- Potential data contamination is not ruled out (overlap between RL training tasks and evaluation sets in Deep Search/QA benchmarks); need strict splits, deduplication, and leakage checks.
- Sparse reward settings and hierarchical structure are not leveraged (option policies, subgoal discovery, subtask curricula) to improve credit assignment in very long horizons.
- Platform and deployment scalability details are missing (orchestration across thousands of env instances, cross-OS determinism, containerization, resource contention, and cost models).
- Ethical/legal aspects of using external services (rate limits, ToS compliance, privacy of queries) in Deep Search environments are not addressed; need reproducible caching policies and auditing.
- Robustness to partial observability is not analyzed (recurrent policies, memory-augmented transformers); how architectural choices mitigate POMDP challenges is left open.
- Constraints and safe RL are not considered (e.g., respecting website policies, avoiding harmful actions, budget-constrained optimization) in multi-turn web/embodied settings.
- Real-world embodied deployment is absent (sim-to-real transfer, sensor noise, actuation delays); current embodied tasks are simulated and may not reflect physical constraints.
- Interaction between post-training compute and test-time compute is not quantified (marginal gains per additional training vs. inference tokens/turns; optimal budget allocation).
- Environment-specific reward and tool API specifications (e.g., error taxonomies, retry policies, throttling) are not documented; lack of standardized interfaces hinders reproducibility and cross-benchmark comparisons.
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s framework (AgentGym-RL), methods (ScalingInter-RL), engineering innovations, and empirical insights. Each item names a concrete use case, the sector(s) it impacts, indicative tools/workflows/products, and key assumptions/dependencies for feasibility.
Immediate Applications
The following applications can be piloted or deployed now using the open-sourced framework, supported environments, and mainstream RL algorithms (PPO, GRPO, RLOO, REINFORCE++), together with the provided UI, scripts, and standardized evaluation.
- Web RPA and process automation for complex sites
- Sectors: software, e-commerce, operations
- Use case: Train agents to reliably execute multi-step web tasks (procurement, form filling, data extraction, account maintenance) in realistic, resettable sandboxes (e.g., WebArena).
- Tools/workflows: Headless browser farms; reward shaping for task completion/accuracy; CI pipelines that auto-train and re-evaluate policies on regression suites; compute-budget schedules via ScalingInter-RL to stabilize training; telemetry dashboards via the provided UI.
- Assumptions/dependencies: High-fidelity sandbox environments that mirror production UIs; ToS and compliance constraints for live-site interactions; privacy/PII safeguards; clear, measurable terminal rewards.
- Enterprise search, due diligence, and research assistants
- Sectors: enterprise software, legal, consulting, pharma R&D
- Use case: Multi-turn, tool-using agents for literature review, competitive intelligence, patent search, and report synthesis using Deep Search environments (browser + retrieval + Python).
- Tools/workflows: Retrieval pipelines with verified sources; domain-specific reward functions (e.g., citation coverage, factuality checks); preference data or outcome rewards; per-task dynamic horizon schedules to trade off speed vs thoroughness.
- Assumptions/dependencies: API access (search, internal knowledge bases), robust factuality scoring, governance guardrails (source transparency, bias checks).
- Customer support copilots that navigate internal tools
- Sectors: customer service, SaaS, BPO
- Use case: Agents learn to follow playbooks across multiple web back-ends (ticketing, CRM, billing) through multi-turn RL, reducing hand-offs and error rates.
- Tools/workflows: Internal WebArena-style sandboxes; outcome rewards tied to resolution/CSAT; offline-to-online loops (SFT from logs → RL in sandbox).
- Assumptions/dependencies: Instrumented sandbox replicas of internal tools; secure data handling; escalation policies for high-stakes cases.
- Software engineering triage across issue trackers and forums
- Sectors: software, DevOps
- Use case: Agents that read, triage, and link related GitLab/GitHub issues and Reddit/forum posts; propose next actions; label and route items.
- Tools/workflows: Synthetic GitLab/Reddit-like environments; rewards for correct routing/resolution; ScalingInter-RL to increase horizon as complexity grows.
- Assumptions/dependencies: Curated benchmarks reflecting real repos; robust evaluation metrics (e.g., precision/recall for triage outcomes).
- Scientific protocol checking in ELNs and education labs
- Sectors: scientific tooling, biotech education
- Use case: Agents plan steps, check protocols, and reason about expected outcomes within SciWorld-like simulations; classroom tutors for lab courses.
- Tools/workflows: Protocol-to-simulator mapping; terminal rewards for correct end-state; UI to inspect action-by-action decision-making for grading/feedback.
- Assumptions/dependencies: Coverage of domain-specific lab steps; alignment between simulator physics and real-world lab expectations.
- Curriculum-aligned problem-solving tutors with reflection
- Sectors: education
- Use case: Multi-step tutoring agents trained via RL to solve and explain procedural problems (math, science), with progressive interaction horizons.
- Tools/workflows: Item banks with verifiable solutions; rewards for correctness and reasoning quality; integration into LMS; compute-budget controllers for test-time depth.
- Assumptions/dependencies: Reliable auto-grading; age-appropriate safety policies; alignment with curricula.
- Agent evaluation and red-teaming laboratories
- Sectors: policy, safety, assurance
- Use case: Standardized evaluation harnesses and adversarial scenarios to audit web agents for prompt injection, tool misuse, data exfiltration, and unsafe actions.
- Tools/workflows: Resettable sandboxes; adversarial tasks; safety reward penalties; longitudinal logs via the UI to analyze failure modes.
- Assumptions/dependencies: Threat model design; coverage of realistic attacks; reproducible scoring protocols.
- Open research platform for multi-turn RL at scale
- Sectors: academia, AI labs
- Use case: Benchmarking RL algorithms for agents, ablations on horizon schedules, reward design studies, and reproducible agent training pipelines.
- Tools/workflows: Built-in PPO/GRPO/RLOO/REINFORCE++; standardized APIs and scripts; visualization UI; parallel rollout infrastructure (multi-browser, multi-env).
- Assumptions/dependencies: Compute availability; community contributions of new environments; adherence to evaluation protocols.
- Cost-effective post-training for smaller models
- Sectors: software, startups
- Use case: Achieve “large-model-like” multi-turn competence on 7B-class models through RL and test-time compute scaling instead of parameter scaling alone.
- Tools/workflows: RL fine-tuning on target tasks; dynamic horizon at inference; optional distillation of RL behaviors into lighter deployable policies.
- Assumptions/dependencies: Target tasks must yield stable reward signals; compute budgets for RL and inference; careful monitoring to avoid overfitting/spurious strategies.
- MLOps for large-scale agent RL farms
- Sectors: MLOps, cloud
- Use case: Production-grade training clusters using the framework’s engineering optimizations (parallel browsers, memory-leak fixes, robust resets).
- Tools/workflows: Kubernetes orchestration; rollout queueing; metrics collectors; failure recovery; dataset/version registries.
- Assumptions/dependencies: Reliable sandbox resets; resource isolation; observability to detect drifts.
Long-Term Applications
These applications are promising but need further research, scaling, environment fidelity, safety, integration with hardware, or regulatory approvals before wide deployment.
- Embodied robotics for household and industrial tasks
- Sectors: robotics, logistics, manufacturing
- Use case: Extend BabyAI-style RL to real robots for navigation, manipulation, and tool use with long-horizon planning and reflection.
- Tools/workflows: Sim-to-real transfer; curriculum with progressive horizons; sensor fusion; safety constraints in rewards.
- Assumptions/dependencies: High-fidelity simulators; robust perception-action loops; physical safety and liability frameworks.
- Clinical workflow copilots and EHR navigation
- Sectors: healthcare
- Use case: Agents that traverse EHR systems, clinical guidelines, and patient portals to support preauthorization, order sets, and documentation.
- Tools/workflows: EHR sandboxes; medically grounded reward functions (safety, adherence); human-in-the-loop oversight; audit logs.
- Assumptions/dependencies: Regulatory approvals (HIPAA, FDA where relevant); bias/fairness audits; robust guardrails; gold-standard labels.
- Financial compliance, KYC/AML, and investigative workflows
- Sectors: finance, regtech
- Use case: Multi-turn agents that gather evidence across internal systems and external sources, draft SARs, and document case narratives.
- Tools/workflows: Synthetic financial sandboxes; reward signals for evidence sufficiency and accuracy; interpretable trajectory logs for audits.
- Assumptions/dependencies: Access to anonymized or synthetic data; explainability; model risk management compliance.
- Closed-loop autonomous science and lab automation
- Sectors: biotech, materials, chemistry
- Use case: Agents controlling lab devices to plan/execute experiments, analyze results, and iterate toward targets (yield, stability).
- Tools/workflows: Digital twins of instruments; outcome-based rewards; safety interlocks; scheduling orchestration.
- Assumptions/dependencies: Reliable hardware integration; robust causal feedback; safety certification; data provenance tracking.
- Enterprise orchestration across ERP/CRM/BI ecosystems
- Sectors: enterprise software
- Use case: End-to-end agents spanning multiple systems to handle procure-to-pay, quote-to-cash, or FP&A workflows with verifiable outcomes.
- Tools/workflows: Standardized agent-API adapters; environment reset for repeatable tests; SLAs tied to outcome rewards.
- Assumptions/dependencies: Comprehensive API coverage; change-management processes; strong RBAC and audit trails.
- Government and policy assistants for long-horizon synthesis
- Sectors: public policy, govtech
- Use case: Agents that gather legislation, economic data, stakeholder input to draft briefings, scenario plans, and impact assessments.
- Tools/workflows: Curation pipelines; multi-criteria reward signals (completeness, balance, evidence quality); transparency reports of sources and steps.
- Assumptions/dependencies: Nonpartisan oversight; bias mitigation; public record compliance; traceable decision logs.
- Personal digital secretaries for complex multi-app tasks
- Sectors: consumer software, productivity
- Use case: Assistants that plan and execute multi-step tasks across email, calendars, travel, and web accounts with dynamic horizon control for reliability.
- Tools/workflows: Local sandboxes; privacy-preserving policy training; compute-budget tuning for on-device vs cloud.
- Assumptions/dependencies: Strong privacy and security isolation; user consent; graceful fallbacks and handoffs.
- Energy system planning and operations support
- Sectors: energy, utilities
- Use case: Agents trained in simulators to plan grid operations, coordinate DERs, or optimize maintenance schedules over long horizons.
- Tools/workflows: Grid digital twins; safety-critical rewards; conservative action constraints; human review in the loop.
- Assumptions/dependencies: Accurate simulators; regulatory approvals; robust risk controls.
- Safety and alignment research for agentic systems
- Sectors: AI safety, standards bodies
- Use case: Systematic studies of reward hacking, long-horizon credit assignment, and safe exploration using standardized multi-env RL.
- Tools/workflows: Shared benchmarks, incident taxonomies, and common evaluation protocols; cross-lab red-teaming initiatives.
- Assumptions/dependencies: Community governance; shared datasets and reproducibility norms; reporting standards.
- Training-as-a-service platforms (“AgentGym Cloud”)
- Sectors: cloud, AI platforms
- Use case: Managed RL training/evaluation offerings where customers bring tasks and sandboxes, and receive tuned agent policies and dashboards.
- Tools/workflows: Multi-tenant MLOps; billing by rollout hours and compute budget; compliance reporting; integration SDKs.
- Assumptions/dependencies: Security isolation; SLA-backed reliability; clear IP/data ownership; cost transparency.
Notes on feasibility across applications:
- Reward design and environment fidelity are the primary dependencies. Outcome-based, verifiable rewards and deterministic, resettable environments make stable training practical; weak or noisy rewards slow progress or risk spurious strategies.
- Progressive interaction scaling (ScalingInter-RL) is a generalizable workflow knob to balance early exploitation and later exploration; it reduces collapse risk at long horizons and improves sample efficiency.
- The paper’s insight that post-training and test-time compute scale better than model size suggests a cost-effective adoption path: invest in RL post-training for target tasks, then modulate inference-time horizon per task criticality and latency budgets.
- Safety, compliance, and observability need first-class treatment: trajectory logging, auditability, and human-in-the-loop checkpoints are essential in regulated and high-stakes domains.
Collections
Sign up for free to add this paper to one or more collections.