- The paper introduces SWEET-RL, a method that uses privileged critic training and token-level reward modeling to improve credit assignment in multi-turn collaborative tasks.
- It applies turn-level direct preference optimization and the Bradley-Terry objective to achieve a 6% absolute performance gain over standard RL baselines in backend programming and frontend design tasks.
- Empirical evaluations on the ColBench benchmark demonstrate improved sample efficiency and generalization, setting a promising foundation for future collaborative agent research.
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Introduction and Motivation
The paper addresses the challenge of training LLM agents to perform collaborative multi-turn tasks requiring complex reasoning, such as backend programming and frontend web design. Most existing multi-turn reinforcement learning (RL) algorithms for LLM agents suffer from ineffective credit assignment across multiple decision steps, particularly when faced with partial observability and long-horizon objectives typical in real-world scenarios. Single-turn RLHF methods and naive trajectory-level algorithms often display poor sample efficiency and limited generalization, as their loss functions misalign with the underlying structure of token-based LLMs.
To support rigorous evaluation and accelerate research on multi-turn RL algorithms, the paper introduces the Collaborative Agent Benchmark (ColBench), which encompasses diverse, realistic artifact creation tasks. ColBench features simulated human collaborators and scalable, reliable measurement via functional evaluators, thereby providing a standardized protocol for multi-turn RL agent evaluation.
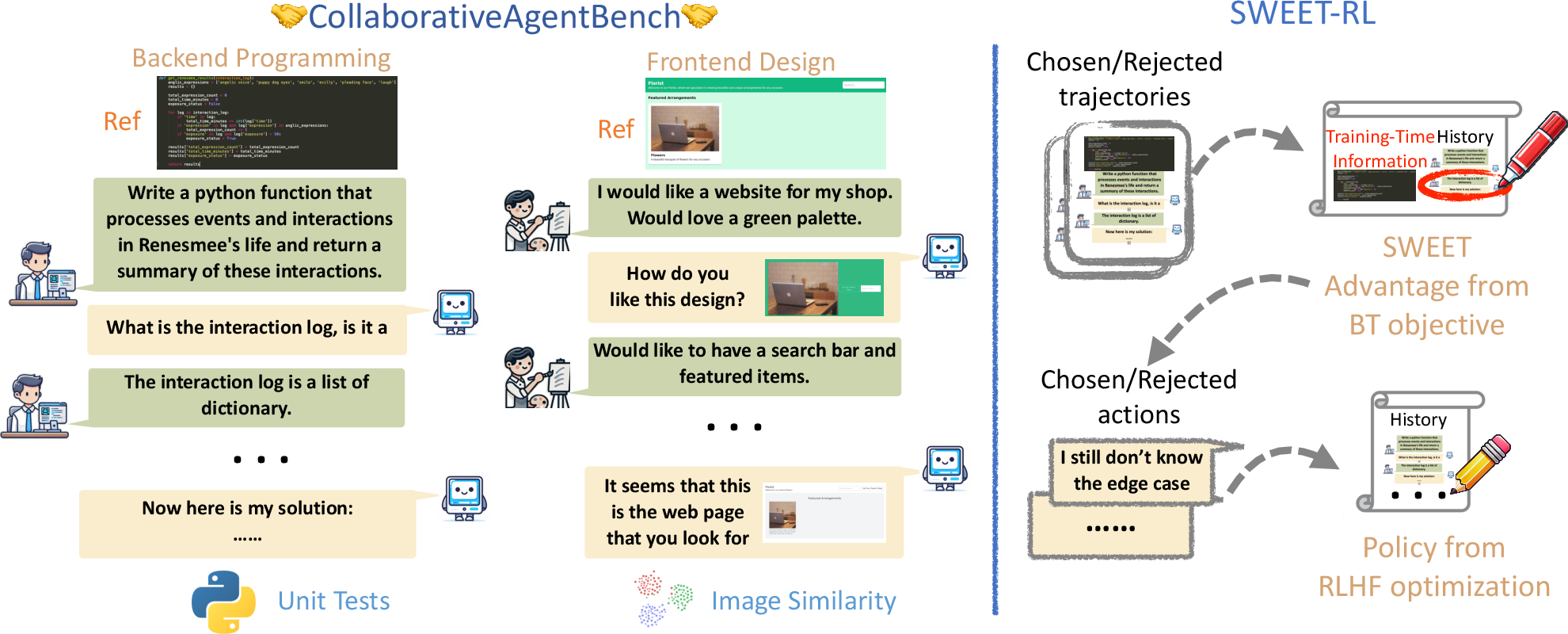
Figure 1: ColBench overview, including backend programming and frontend design tasks, and the SWEET-RL motivation for leveraging additional training-time information with the Bradley-Terry objective for effective credit assignment.
ColBench structures agent collaboration as a finite-horizon partially observable Markov decision process (POMDP) where training-time privileged information (e.g., the reference solution) is available to the critic during training but not to the acting LLM agent at deployment. The benchmark focuses on two domains:
- Backend Programming: Agents collaborate to write custom Python functions based on incomplete descriptions, clarifying requirements interactively and evaluated via hidden unit tests.
- Frontend Design: Agents iteratively generate and refine HTML snippets based on feedback on rendered web pages, evaluated using CLIP-based perceptual similarity.
Tasks are procedurally generated to ensure diversity and scalability, and simulated users, informed by ground-truth artifacts, facilitate reliable closed-loop evaluation without expensive human annotation.
SWEET-RL: Methodology and Training Procedure
SWEET-RL (RL with Step-WisE Evaluation from Training-Time Information) proposes a two-stage framework:
- Critic Training: A turn-level advantage function is learned using preference pairs of agent trajectories. The critic leverages the Bradley-Terry (BT) objective to compare full sequences, assigning higher advantage to actions within trajectories with higher cumulative rewards. Importantly, the critic conditions on additional training-time information unavailable to the eventual deployed agent.
- The advantage function is parameterized using the mean log-probabilities from the LLM’s token-level head (normalized by response length). This aligns the RL credit assignment with the token-level architecture pretrained for next-token prediction, avoiding brittle value head regression on hidden states.
- Preference pairs {τ+,τ−} are constructed from existing data, and the BT objective encourages separation in cumulative advantage between positive and negative trajectories.
- Policy Optimization: The learned advantage function serves as a dense per-step reward model during policy fine-tuning. The acting policy is then trained using a turn-wise version of Direct Preference Optimization (DPO), ranking candidate actions at each turn and assigning loss according to their advantages.

Figure 2: Schematic of the SWEET-RL training procedure, showing BT-based advantage modeling and its use for turn-wise policy optimization with privileged critic inputs.
Empirical Evaluation and Comparative Results
On ColBench, SWEET-RL demonstrates consistent improvements over baselines (e.g., rejection fine-tuning, multi-turn DPO) and competitive proprietary models (e.g., GPT-4o). Specifically, Llama-3.1-8B-Instruct trained via SWEET-RL matches or exceeds the performance of much larger and proprietary models on success rate and win rate metrics, achieving a marked 6% absolute gain over alternative RL algorithms on both backend programming and frontend design tasks.
Credit Assignment Analysis
Through Best-of-N sampling experiments, SWEET-RL’s step-wise reward model, with access to training-time privileged information, notably outperforms value-function-based and LLM-as-a-judge heuristics. It robustly identifies high-utility actions in realistic multi-turn settings and generalizes to unseen scenarios with limited training data.
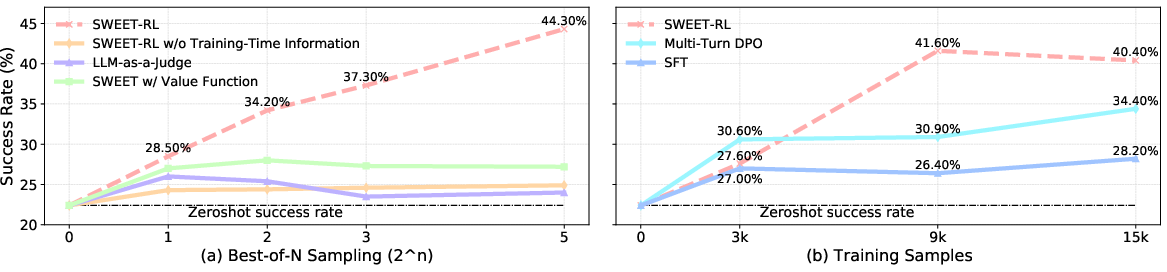
Figure 3: (a) Scaling curves illustrating that SWEET-RL’s critic yields superior Best-of-N performance in candidate selection; (b) Sample efficiency analysis showing SWEET-RL’s faster convergence with more data compared to baselines.
Ablation studies confirm that the specific choice of critic parameterization—mean token log-probabilities with normalization and privileged training inputs—substantially outperforms regression-head value function alternatives and LLMs without access to full training information.
Qualitative comparisons further indicate that standard model-judges are susceptible to irrelevant factors (e.g., response length, formatting), while SWEET-RL focuses on actionable utility and underlying task success.

Figure 4: Qualitative comparison of credit assignment approaches, demonstrating SWEET-RL’s ability to attend to action utility and task outcome, versus distractibility and poor generalization of alternatives.
Theoretical and Practical Implications
The SWEET-RL framework shows that turn-level reward modeling aligned with the LLM architecture is critical for efficient credit assignment in long-horizon collaborative tasks. By exploiting asymmetric information during training and integrating preference-based objectives with token-level modeling, the approach achieves superior performance and generalization. The methodology additionally provides theoretical guarantees that policy gradients computed with asymmetric critics remain unbiased under realistic occupancy distributions.
Practically, this advances the design of multi-turn RL for open-ended agentic tasks (e.g., codebases, web design), reducing reliance on extensive on-policy data collection and enabling rapid, lower-cost progress in agent training and deployment. The framework sets the stage for future work on incorporating richer modalities, larger context windows, and semi-automated evaluation schemes.
Conclusion
SWEET-RL introduces an effective and implementable paradigm for optimizing LLM agents on reasoning-intensive, multi-turn tasks via privileged critic training and architecture-consistent advantage modeling. Empirical results validate robust, sample-efficient generalization, closing the gap with larger and proprietary models. The ColBench benchmark provides a rigorous foundation for continued research in collaborative agent RL, with promising opportunities to extend multi-turn methodologies across broader domains and model architectures.