Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design
Abstract: This paper investigates Reinforcement Learning (RL) approaches to enhance the reasoning capabilities of LLM agents in long-horizon, multi-turn scenarios. Although RL algorithms such as Group Relative Policy Optimization (GRPO) and Proximal Policy Optimization (PPO) have been widely applied to train multi-turn LLM agents, they typically rely only on sparse outcome rewards and lack dense intermediate signals across multiple decision steps, limiting their performance on complex reasoning tasks. To bridge this gap, we present the first systematic study of \textit{turn-level reward design} for multi-turn RL algorithms and agent applications. By integrating turn-level rewards, we extend GRPO and PPO to their respective multi-turn variants, enabling fine-grained credit assignment. We conduct case studies on multi-turn reasoning-augmented search agents, where we carefully design two types of turn-level rewards: verifiable and LLM-as-judge. Our experiments on multi-turn search tasks demonstrate that incorporating well-designed turn-level rewards enables RL algorithms to significantly outperform baseline methods with trajectory-level rewards. Both training and validation reward curves illustrate that our method achieves \textit{greater stability}, \textit{faster convergence}, and \textit{higher accuracy}. Numerical results across diverse question-answering datasets further show that our approach consistently delivers highest answer correctness and 100\% format correctness.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI chatbots (LLMs, or LLMs) to solve problems step by step over several turns, especially when they use tools like a search engine. The authors show how to give the AI useful feedback at each step (not just at the end), so it can learn faster, make better decisions, and produce answers in the right format.
Think of it like a long puzzle. If you only find out at the end whether you were right or wrong, it’s hard to know which steps helped. This paper designs “turn-level rewards,” like points or feedback after each move, to guide the AI through multi-step tasks.
Key Questions the Paper Tries to Answer
- How can we train LLM agents to make better multi-step decisions instead of judging them only at the end?
- What’s the best way to give feedback (rewards) at each turn so the AI knows which actions helped?
- Can adding turn-level feedback make training more stable, faster, and more accurate?
- How do popular training methods (GRPO and PPO) need to change to use turn-level rewards?
How They Did It (Methods and Ideas)
First, two important ideas:
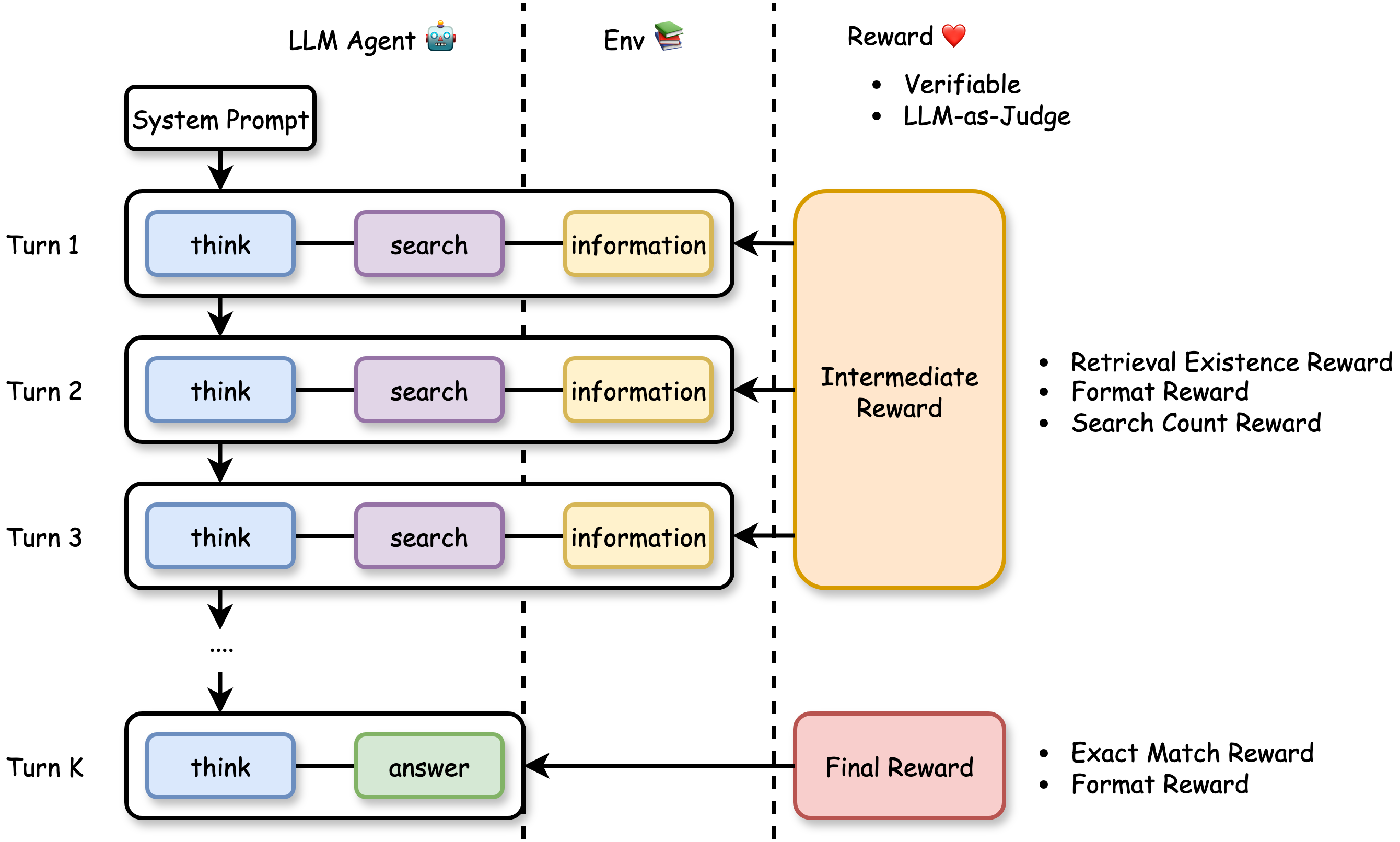
- Multi-turn tasks: The AI doesn’t just answer once. It thinks, searches for information, reads results, thinks again, and finally answers. Each cycle is a “turn.”
- Rewards: Like points in a game. Outcome rewards score the final answer. Turn-level rewards score each step to show if the AI is on the right track.
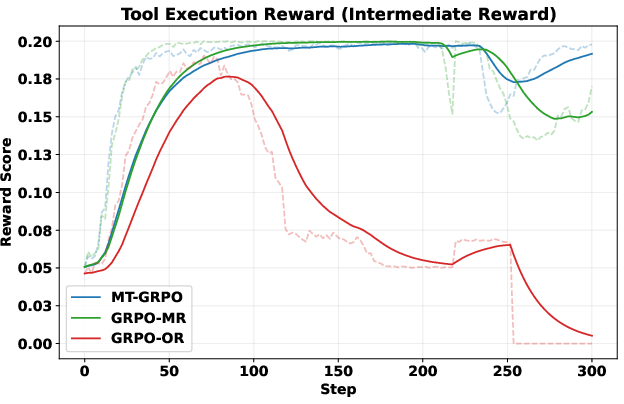
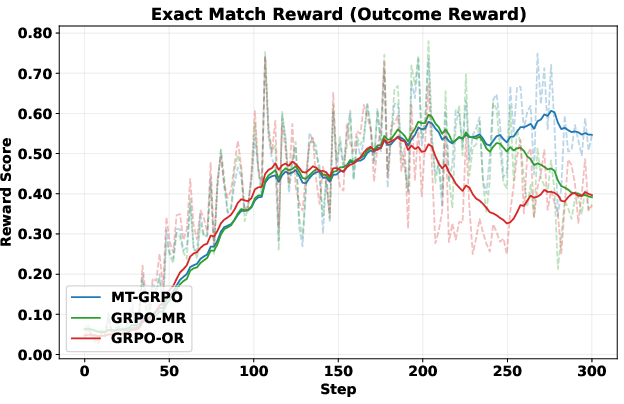
Here’s the everyday picture: training without turn-level rewards is like playing a long game and only getting a score at the very end. With turn-level rewards, you get feedback after each move—“Nice search query,” “Good formatting,” “Found something useful,” or “Too many searches—slow down.”
The paper adapts two popular Reinforcement Learning (RL) methods:
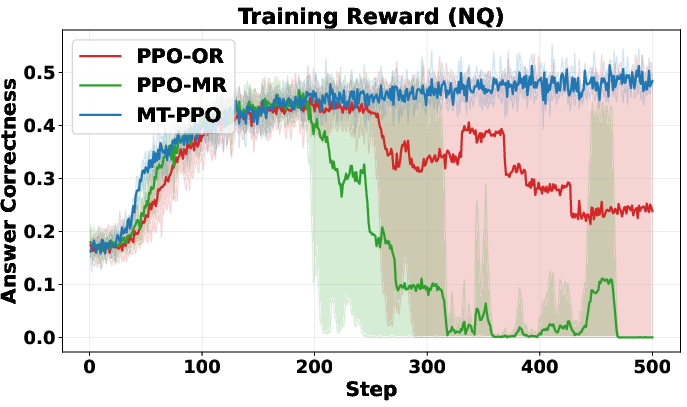
- GRPO (Group Relative Policy Optimization): Think of it as comparing multiple answers from the AI and pushing it toward the better ones. The authors create a multi-turn version (MT-GRPO) that tries to score each turn. But there’s a catch: it needs a lot of samples (like trying many paths at every step), which becomes expensive and forces a fixed number of turns. That makes it hard to use for longer tasks.
- PPO (Proximal Policy Optimization): This method uses a “critic” model—like a coach that estimates how good the current step is likely to be. The authors make a multi-turn version (MT-PPO) that inserts rewards at the right moments (end of each turn). The critic helps assign credit to specific tokens (words and symbols) and steps. MT-PPO is much more efficient and flexible than MT-GRPO.
They test these ideas on a reasoning-augmented search agent:
- The agent follows a loop: 1) Thinks about what’s needed, 2) Creates a search query, 3) Reads results, 4) Repeats until ready, 5) Writes the final answer.
Turn-Level Reward Design
To make feedback clear and fair, they use two types of turn-level rewards:
- Verifiable rewards (strict, rule-based):
- Intermediate steps:
- Did the retrieved text contain the correct answer (or a clue) from Wikipedia?
- Did the agent use the correct format tags (like
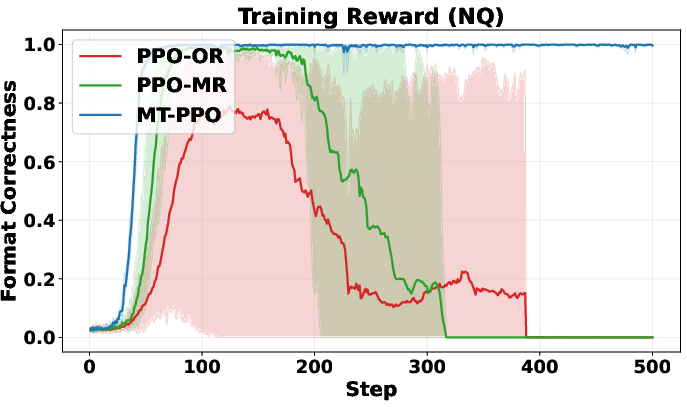
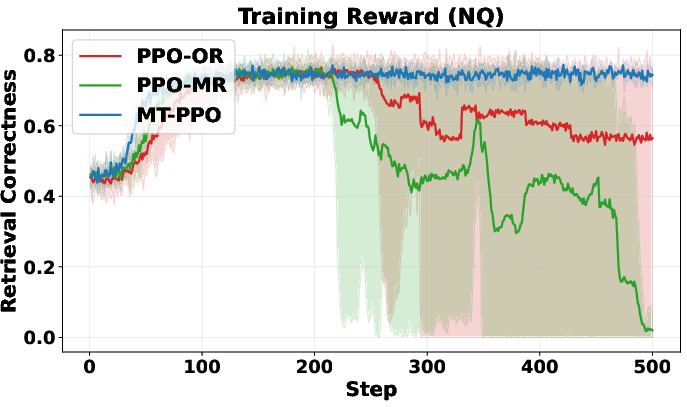
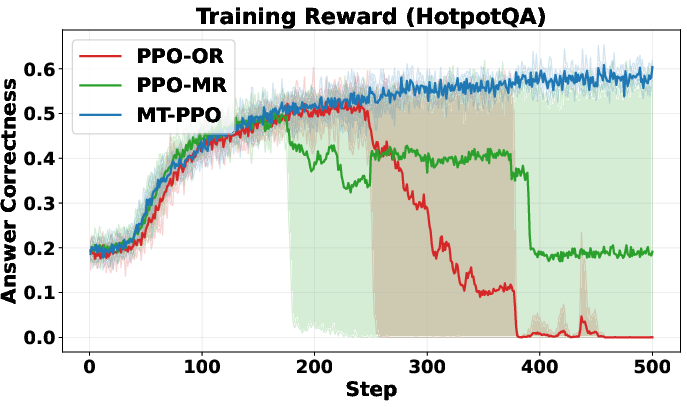
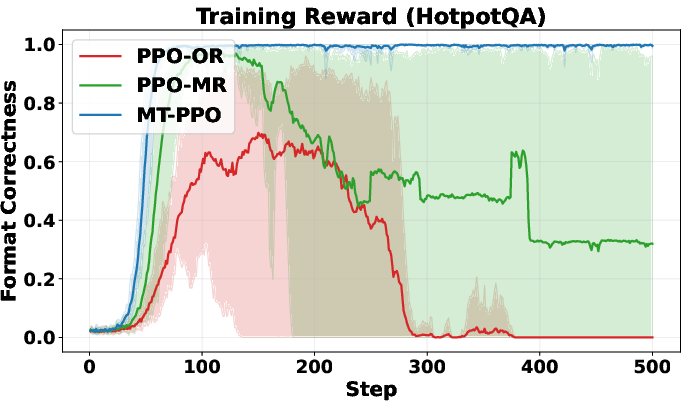
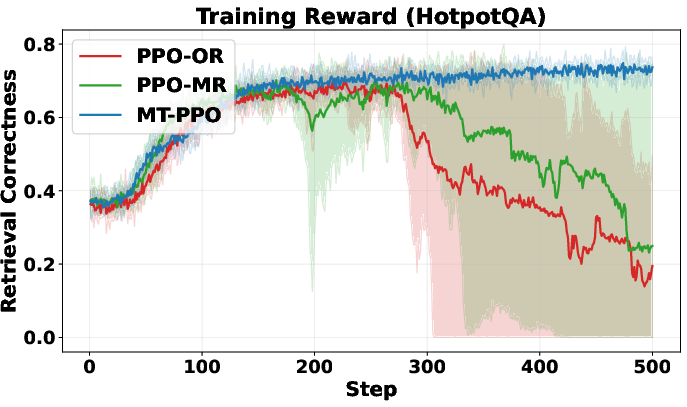
>,<search>,<information>) in the right order? > - Did it avoid overusing the search tool? (Too many searches get a small penalty.) > - Final step: > - Exact match: Does the answer between<answer>tags match the ground truth? > - Format check: Did the solution contain only<think>and<answer>tags in the right order? > > - LLM-as-judge rewards (flexible, expert grading): > - A strong LLM acts like a teacher. It reads each turn, reasons through it, then scores based on a rubric (format, reasoning quality, search usefulness, etc.). This captures nuanced improvements that strict rules might miss. > > ## Main Findings and Why They Matter > > The authors run lots of experiments on question-answering datasets (like NQ, TriviaQA, HotpotQA, etc.) and compare different training setups. Their key results: > > - Training is more stable with turn-level rewards. The learning curves don’t swing wildly or crash. > > - Training is faster early on. Turn-level feedback helps the agent quickly learn good habits (like writing properly formatted output and making efficient searches). > > - Accuracy improves. The agent answers more questions correctly, especially on harder multi-hop tasks that require multiple searches and reasoning steps (e.g., HotpotQA). > > - Format correctness is near-perfect. MT-PPO produces outputs in the required structure about 100% of the time, which is crucial for automated grading and tool use. > > - Overall, MT-PPO (the PPO version with turn-level rewards) consistently beats baselines that only use final rewards or merge everything into one lump score. > > In simple terms: giving the AI feedback at each step made it smarter, faster, and more reliable. > > ## Implications and Potential Impact > > This approach can make AI agents better at complex, step-by-step tasks—not just answering from memory, but using tools (like search engines, calculators, or code interpreters) responsibly and effectively. With turn-level rewards: > > - Agents learn which actions help long-term success, not just whether the final answer was right. > > - Outputs are more trustworthy and well-structured, which helps real-world systems that depend on correct formats. > > - The idea generalizes beyond search: it could improve tool use in coding, math, data analysis, and more. > > Bottom line: turn-level rewards are a practical way to build smarter, more dependable AI agents that can reason over multiple steps and interact with the world in a controlled, productive way.
Knowledge Gaps
Here is a concise, actionable list of the knowledge gaps, limitations, and open questions left unresolved by the paper:
- Generalization beyond search: Effectiveness of turn-level rewards for other tool-augmented tasks (e.g., calculators, code execution, database queries, APIs with errors/latency) is not evaluated.
- Dynamic environments: Results are on a static 2018 Wikipedia index; robustness to live web dynamics, content drift, and tool failures remains untested.
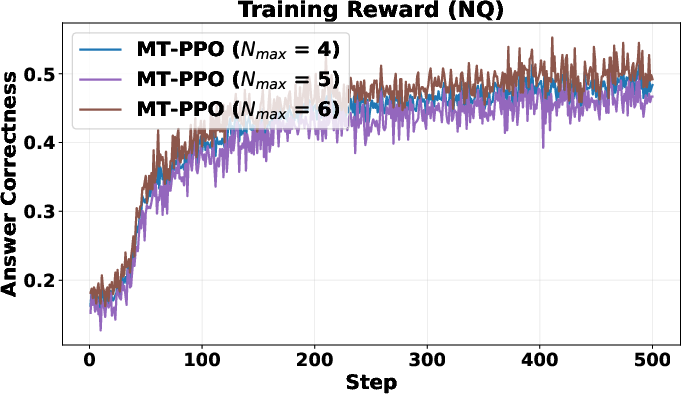
- Horizon length: MT-PPO is only evaluated with short horizons (N_max ≤ 6); scalability and stability on long-horizon, branching tasks are unknown.
- MT-GRPO practicality: The proposed MT-GRPO is only demonstrated for two turns; no approximation or variance-reduction strategy is offered to mitigate its exponential rollout cost or fixed-turn constraint for K > 2.
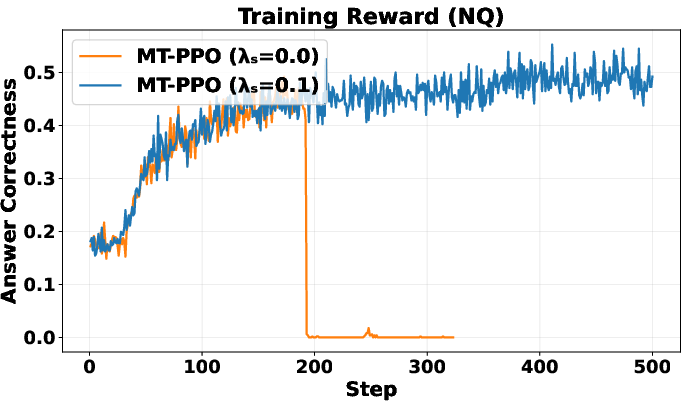
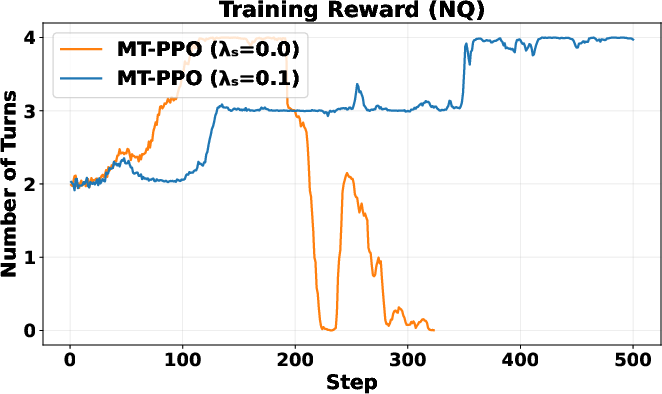
- Reward shaping sensitivity: The paper fixes ad-hoc intermediate reward magnitudes (e.g., 0.3, 0.1, −0.2) and search penalty λ_s = 0.1; sensitivity analyses and principled tuning guidelines are missing.
- Discounting and GAE choices: No study on the impact of γ and GAE λ on stability/credit propagation across turns; best practices for these hyperparameters in multi-turn settings remain unclear.
- Token-level credit within a turn: Rewards are placed only on the last token of a turn; whether denser token-level signals (e.g., at reasoning/tool-call boundaries) yield better credit assignment is not explored.
- Value function design: Architecture, conditioning, and training choices for the critic (e.g., turn markers, action-type embeddings, separate value heads per turn) are not analyzed; their effect on collapse/variance is unknown.
- PPO collapse diagnosis: While MT-PPO appears more stable, the root causes of PPO collapse in long-CoT settings (e.g., value overfitting, bootstrapping bias) are not systematically diagnosed or mitigated.
- Reward hacking risks: The retrieval-existence reward (string match) can be gamed by retrieving passages containing the surface form without true evidential grounding; safeguards or evidence-quality signals are absent.
- Judge reliability: The LLM-as-judge’s calibration, bias, inter-rater reliability, and susceptibility to manipulation by the trained agent are not measured; no adversarial or cross-judge robustness checks.
- Cost and throughput: The computational and wall-clock overhead of turn-level rewards (especially judge-based) is not quantified; trade-offs vs. trajectory-level training are unclear.
- Fairness of baselines: Some baselines reportedly crash; comparisons use “final or last-before-collapse” checkpoints; controlled re-trains under identical seeds, budgets, and early stopping criteria are needed.
- Out-of-domain coverage: Benchmarks vary within QA but remain English, Wikipedia-centric; transfer to domains with noisy/long documents (legal, biomedical) or multilingual settings is untested.
- Termination behavior: How turn-level rewards influence the stop decision (premature vs. overly long searches) is only partially probed via λ_s; a principled termination reward or learnable stopping criterion is not developed.
- Multi-objective trade-offs: There is no explicit framework for balancing accuracy, format adherence, tool cost, and latency; Pareto analyses or meta-optimization of weights are missing.
- Evidence sufficiency: Intermediate rewards do not assess whether retrieved context is sufficient/causally supportive; no supervision on reasoning-faithfulness or citation grounding.
- Credit across tool chains: The approach assumes a single search tool per turn; credit assignment across multi-tool pipelines (e.g., retrieve→parse→compute) is not addressed.
- Robustness to retriever quality: Results hinge on a fixed retriever (E5) and k=3 passages; sensitivity to retriever model, k, re-ranking, and noisy top-k is not studied.
- Format generalization: Near-100% format correctness may reflect strong tag adherence; whether such structural control transfers to more flexible or schema-free outputs is unknown.
- Safety and alignment: Effects on hallucination rates, harmful content, and miscalibration are not evaluated; no human evaluation or preference alignment beyond exact match/format metrics.
- Sample efficiency: Improvements are reported in curves but not normalized per environment interaction or token generated; data-efficiency and compute-efficiency comparisons are missing.
- Continual/transfer learning: How turn-level reward policies adapt across datasets over time (catastrophic forgetting, positive transfer) has not been explored.
- Stochastic tool feedback: The framework assumes deterministic feedback; handling noisy, delayed, or partial tool responses and their impact on advantage estimation is open.
- Theoretical guarantees: There is no theoretical analysis of bias/variance in turn-level reward assignment with GAE, or convergence/sample-complexity benefits over trajectory-level methods.
- Open benchmarking: Code/reward templates appear adapted from Search-R1; standardized, open benchmarks for turn-level reward design (with ablations and judge audits) would aid reproducibility.
Collections
Sign up for free to add this paper to one or more collections.