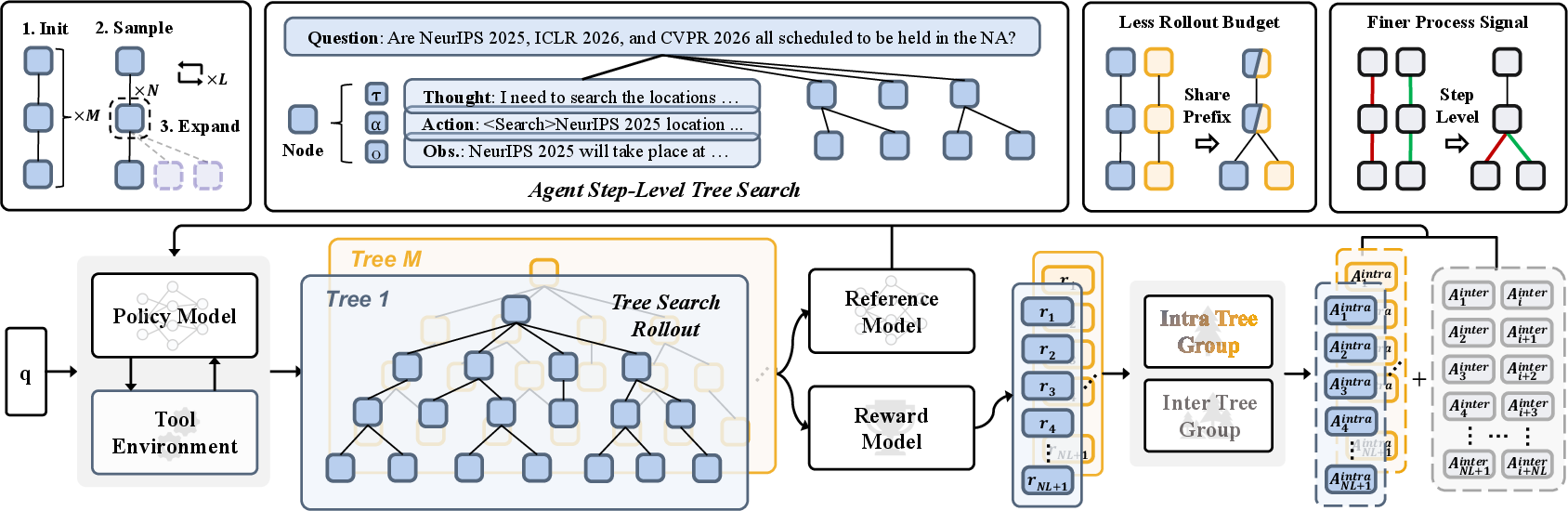
- The paper presents Tree-GRPO, a reinforcement learning strategy that uses tree search to enhance sampling efficiency in multi-turn LLM agent interactions.
- It leverages structured trajectory trees to provide granular, stepwise supervision and reduce token consumption compared to traditional chain-based methods.
- Experimental results demonstrate Tree-GRPO's superior performance and adaptability, particularly in multi-hop QA and complex task environments.
Tree Search for LLM Agent Reinforcement Learning
This paper introduces a novel reinforcement learning approach called Tree-based Group Relative Policy Optimization (Tree-GRPO) tailored for improving LLM agents in multi-turn environments. By employing tree search strategies, Tree-GRPO enhances the sampling efficiency and supervision signals available in reinforcement learning by leveraging structured trajectory data.
Problem Addressed
Traditional reinforcement learning methodologies applied to LLMs suffer from inefficiencies primarily due to sparse reward signals over long trajectories typical in multi-turn interactions. These challenges manifest as both heavy token consumption and a bottleneck in learning due to delayed, trajectory-level rewards rather than fine-grained, stepwise feedback.
Tree-GRPO Method Overview
Tree-GRPO introduces a structured tree search approach where multi-turn agent interactions are represented as nodes in a tree. Key distinctions include:
- Tree Search for Sampling: Employing tree-based rather than chain-based rollouts allows common prefix sharing across sampled trajectories, significantly improving token usage efficiency.
- Step-wise Process Supervision: The tree structure inherently provides opportunities for constructing more granular supervision signals at each interaction step.
- Group Relative Policy Optimization: Advantages are computed not only using trajectory-level outcomes but also taking into account intra-tree and inter-tree relative advantage estimations.
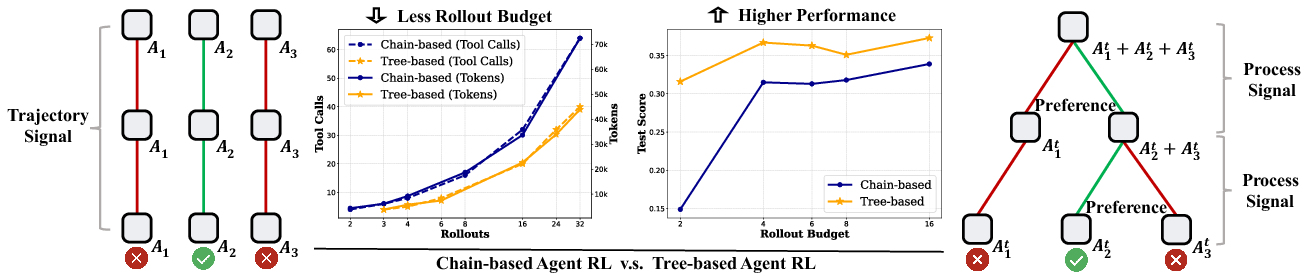
Figure 1: Comparison of chain-based and tree-based sampling strategies in LLM multi-turn agent RL. The tree structure brings two major advantages: (\romannumeral1) less rollout budget (both on tokens and tool-calls); (\romannumeral2) higher performance.
Implementation Details
Tree-GRPO's implementation requires integrating tree-based exploration within existing RL frameworks:
Experimental Results
Experiments conducted over several benchmarks demonstrate Tree-GRPO's superiority over traditional, chain-based methods:
Trade-offs and Considerations
- Configuration Choices: Performance can vary based on tree structure parameters like the number of nodes per layer and branching factor.
- Resource Allocation: While Tree-GRPO reduces token utilization, it requires sophisticated planning for memory and computational allocation due to the complexity of managing tree structures.
Future Directions
Tree-GRPO opens pathways for improving process-level training in LLM agents. Future work may include:
- Fine-tuning Tree Structures: Exploring more complex tree architectures to balance exploration and exploitation during learning.
- Integrating with External Tools: Expanding the model's capability to interact with diverse real-world utilities and datasets dynamically.
Conclusion
Tree-GRPO provides a significant leap in training efficiency and effectiveness for LLM agents engaged in complex, multi-turn tasks. The approach not only maximizes resource utilization but also enhances learning through rich, structure-based supervision signals, highlighting a promising direction for next-generation AI frameworks.